Neste exercício percorremos cada etapa para solucionar um problema real de um contexto de negócios, onde requer-se o uso de linguagens de programação e ciência de dados. O objetivo é demonstrar de forma prática e objetiva os primeiros passos de uma implementação de modelos de machine learning com o R.
Vamos primeiro contextualizar um case de exemplo para depois abordar a solução (informações didáticas).
Problema:
Focaremos no clássico problema de previsão de demanda de usuários, comum em diversas empresas de diversos setores.
Descrição:
Usaremos como case de exemplo a empresa Uber, que fornece o serviço de transporte por aplicativo. Vamos imaginar que você trabalha na área de Dados da empresa (ou pretende trabalhar) na posição de Cientista de Dados. Os demais departamentos internos da empresa necessitam de informações com uma estimativa do nº de usuários por hora/dia para um horizonte de uma semana a frente, para fins de gestão interna. Não há nenhuma solução implementada ainda e o seu prazo de entrega é de 1 dia útil.
Como resolver esse problema nesse curto espaço de tempo? Existem várias possibilidades, sendo que quase todas envolvem o uso de Ciência de Dados e linguagens de programação. Vamos focar em uma abordagem simples e funcional.
Dados:
Os dados que temos a disposição estão estruturados em tabelas organizadas por mês, em formato CSV e disponibilizadas publicamente pela FiveThirtyEight. As tabelas trazem informações sobre corridas (momento do embarque) na cidade de Nova Iorque nos EUA, no período de 01/04/2014 a 30/09/2014.
Mais informações no link https://github.com/fivethirtyeight/uber-tlc-foil-response
Solução:
Vamos propor o uso da linguagem R percorrendo o seguinte fluxo de trabalho para a entrega de previsões do nº corridas por hora aos departamentos internos da empresa.

- Coleta de dados: usamos o repositório público de dados, definindo um projeto de trabalho no ambiente de programação para versionar o código de extração de dados.
- Criação do banco de dados: transformamos a informação bruta de milhões de linhas de arquivos CSV para um banco de dados SQLite, possibilitando consultas de maneira ágil e fácil com pacotes e R.
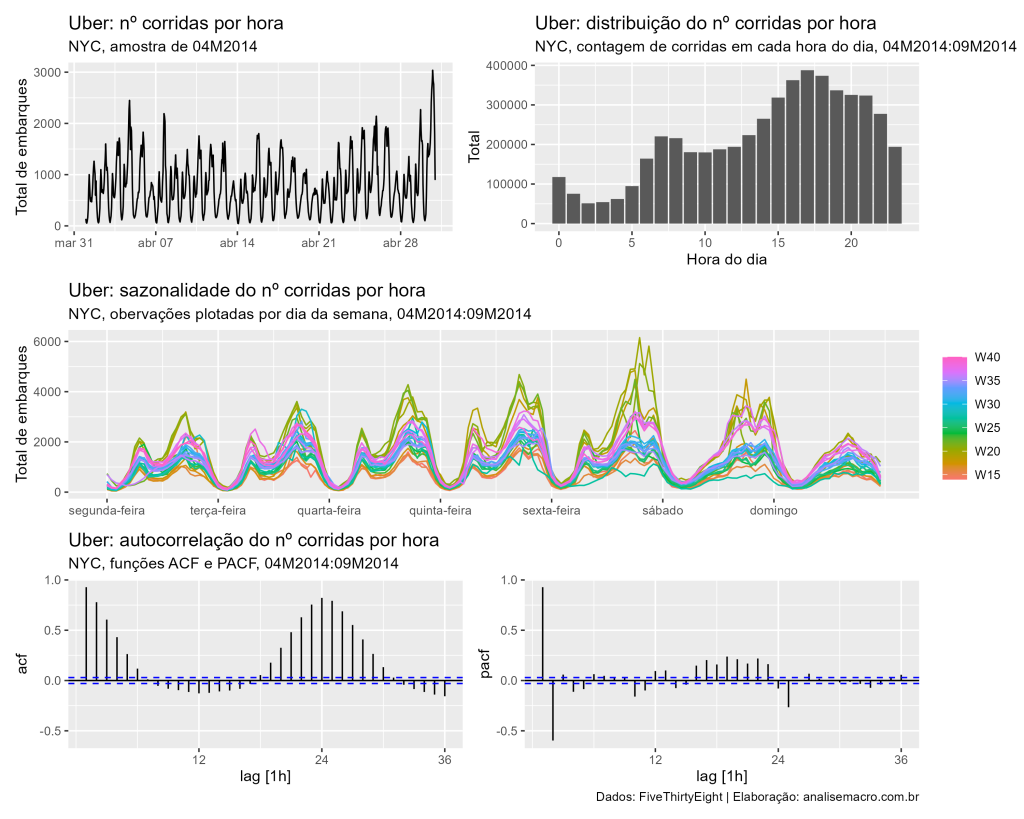
- Análise Exploratória de Dados: com o objetivo de conhecer melhor os dados à disposição, geramos estatísticas descritivas e gráficos de série temporal, focando como série de interesse o nº de corridas por hora do dia. Dessa forma é possível verificar que a média de corridas é de 1181 e que a série possui um forte componente sazonal. Além disso, podem ser identificados possíveis modelos candidatos seguindo processos AR e MA.
- Especificação de modelos: existem diversos modelos à disposição, com abordagens de estatística e de machine learning, mas geralmente será necessário um prazo maior para testá-los e implementá-los. Sendo assim, focando no simples e rápido que funciona, definimos como variável dependente o número de corridas por hora e treinamos os modelos de séries temporais Random Walk (como benchmark de comparação), SARIMA, ETS, OLS, Prophet e ensemble (combinação dos dois melhores modelos).
- Treinamento de modelos: usamos o framework do {tidyverts} para, em poucas linhas de código, esquematizar amostras de dados com janela crescente usando validação cruzada para previsão de 24×7 períodos (data points) a frente. Esse esquema tem como finalidade estimar os modelos para diversas amostras de dados, gerar previsão para cada amostra/modelo e, por fim, comparar o previsto versus observado.
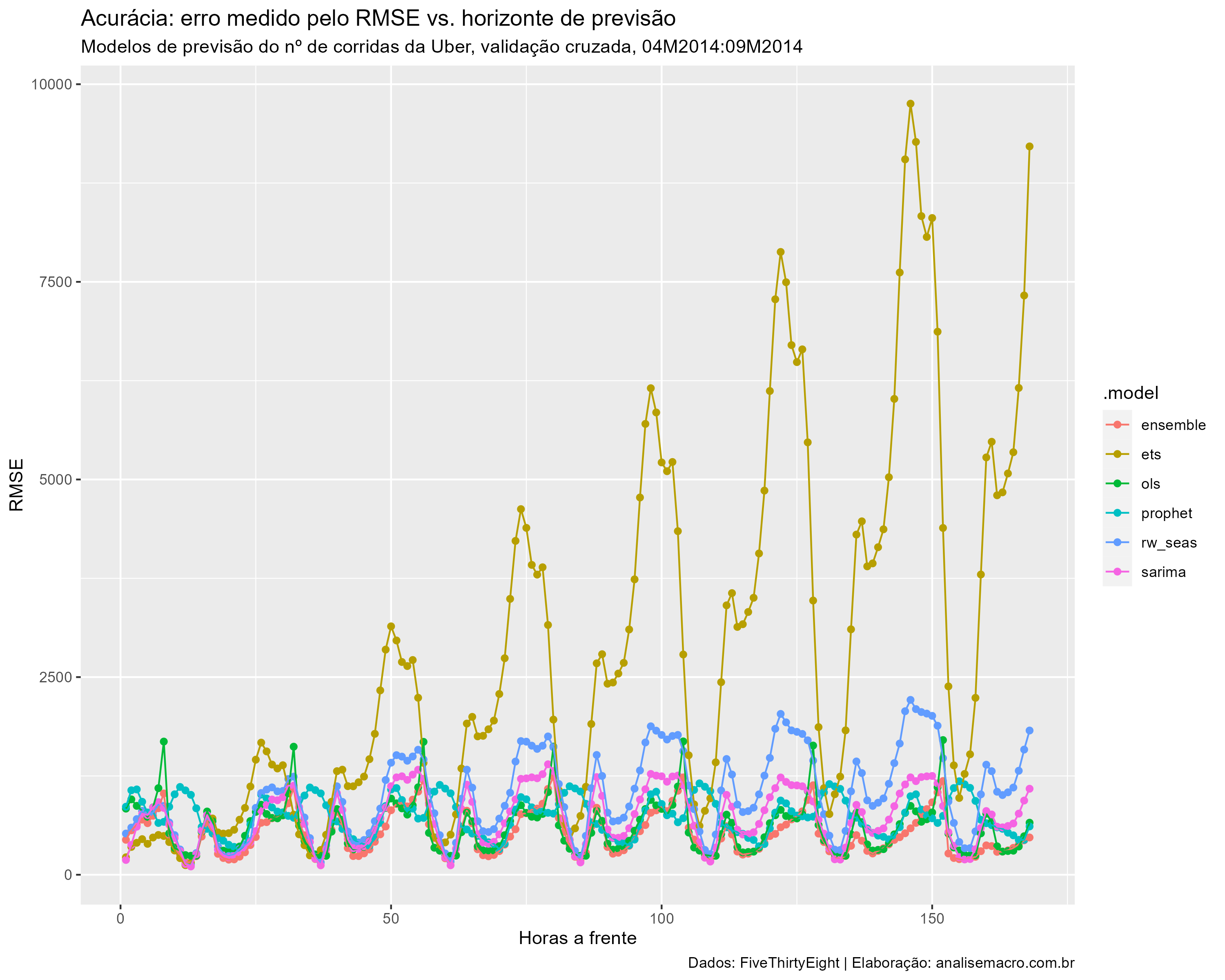
- Escolha de modelo: definimos o critério de escolha do modelo final, após o treinamento, a métrica de erro conhecida como RMSE. Quando menor seu valor, melhor (mais acurado) é o modelo. Calculamos a métrica por horizonte preditivo, assim podemos ver como os modelos performam no curto e "longo" prazo. O gráfico abaixo sintetiza os valores, mostrando a média do RMSE de todas as amostras de validação cruzada, sendo possível definir como modelo mais acurado aquele que é resultado da combinação de outros dois (Random Walk e ETS foram deixados de fora do gráfico pois performaram de maneira muito inferior aos demais, distorcendo a escala).
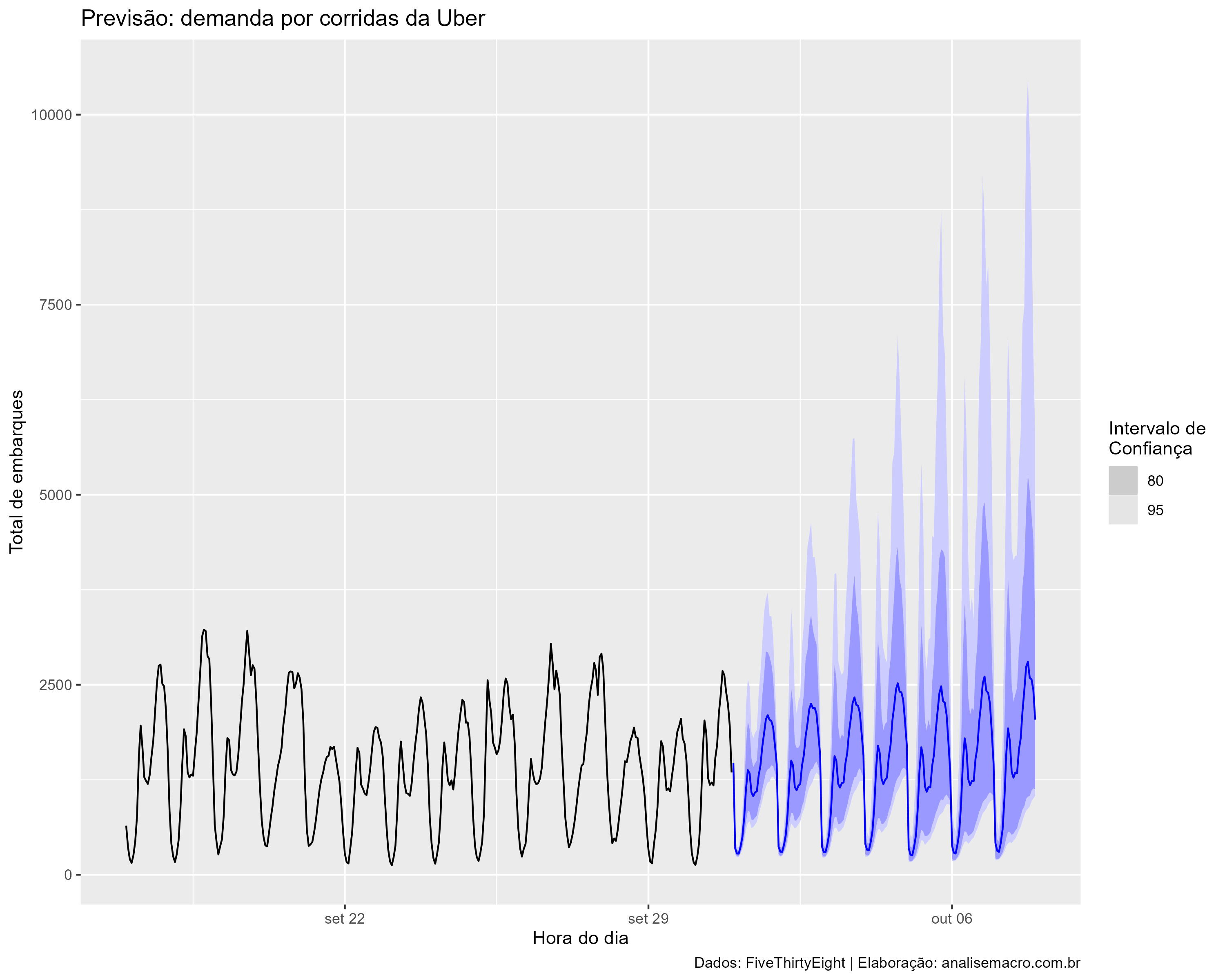
- Previsão fora da amostra: com um modelo definido, chegamos na etapa final e de interesse para os usuários que irão consumir essa informação, ou seja, geramos as previsões fora da amostra pontuais (média) e a distribuição para computar intervalos de confiança. O gráfico abaixo apresenta essas previsões.
Próximos passos
Esses são alguns pontos interessantes em qualquer fluxo de previsão de séries temporais em larga escala que não foram implementados neste exercício e que ficam como sugestão para outros exercícios.
- Criar uma API para consumo dos dados/previsões;
- Criar uma dashboard para atender demanda por rápida análise dos modelos/previsões;
- Usar infraestrutura de nuvem para automatizações e arquitetura de dados;
- Avaliar a performance de outros modelos.
Saiba mais
Para se aprofundar nos tópicos confira os cursos aplicados da Análise Macro e obtenha todo o suporte necessário para dúvidas de R e Python sendo membro do Clube AM.

