Trabalhar com arquivos de dados brutos em CSV ou Excel pode ser complicado no dia a dia: com poucas dezenas de arquivos já há dificuldade em se gerenciar e localizar os dados, além de ser um formato propício para acontecer erros como leitura incorreta de tipos de coluna. E a situação fica pior se há mais dados do que a capacidade de memória do seu computador (ou do que o seu programa de planilha eletrônica suporta), nesse caso fica impossível você fazer uma simples análise de dados importando os arquivos diretamente.
Uma forma mais moderna e, atualmente, padrão na indústria de dados para armazenar e gerenciar informações tabulares são os bancos de dados SQL. Estes sistemas estão no nosso dia a dia, mesmo que você nunca tenha tido o contato direto. Desde o app do seu banco até o caixa do supermercado, os bancos de dados SQL estarão em atuação provendo e armazenando dados de forma segura e eficiente. Portanto, neste exercício mostramos as principais vantagens e ferramentas para sair da "terra de ninguém" dos arquivos CSV até chegar no "Jardim do Éden" dos bancos de dados SQL.
Vantagens de um banco de dados SQL
Sair do modelo de armazenar dados em arquivos flat, como um CSV, para o modelo que usa um sistema gerenciador de banco de dados não é fácil no início, mas é vantajoso no longo prazo. Aqui destacamos as principais vantagens em usar um banco de dados SQL:
- É mais fácil de gerenciar, armazenar e ler os dados;
- Performance: é significativamente mais rápido para análises de dados volumosos;
- Integração: permite consultas feitas pelo R e Python, seja localmente ou pela nuvem;
- Big Data: permite armazenar e lidar com um grande volume de dados;
- Segurança: permite definir senhas e usuários para acesso.
Agora que você sabe porquê deve migrar para um banco de dados SQL, que tal usar o R para facilitar o processo?
Como criar um banco de dados SQL no R
Com a linguagem R o processo de criar um banco de dados SQL é fácil e rápido, são apenas 4 etapas:
- Instale e carregue os pacotes necessários: DBI, RSQLite e data.table.
- Abra uma conexão com um banco de dados com a função DBI::dbConnect(): pode ser uma base existe ou você pode criar uma do zero (recomendamos o SQLite para iniciantes, basta usar RSQLite::SQLite() no argumento drv e definir um nome_da_base.sqlite no argumento dbname da função anterior).
- Importe o arquivo CSV com a função data.table::fread(): esse procedimento importa para a memória do R os dados que serão armazenados na base SQL e este pacote lida melhor com o uso da memória se o arquivo for pesado.
- Crie uma tabela na base SQL e armazene os dados na mesma com a função DBI::dbWriteTable(): esse procedimento se conecta com as etapas 2 e 3, basta definir o objeto com a conexão SQL, o nome da tabela a ser criada e o objeto com os dados importados que serão armazenados na tabela.
Ao final você terá uma banco de dados SQL criado e pronto para uso. A melhor parte é que para usar essa base SQL criada você nem precisa sair do R: é possível utilizar os verbos do {dplyr} se conectando com a tabela dentro do banco de dados SQL e operacionalizando tratamentos e análises de dados como se fosse qualquer outra classe de tabela suportada pelo pacote! Em outras palavras, com o R você nem precisa ser um especialista em SQL para utilizá-lo no dia a dia! 😉
Saiba mais
Se você precisar de mais detalhes e códigos de exemplo, no Clube AM da Análise Macro mostramos todo o procedimento passo a passo usando os dados das eleições 2022 do TSE como exemplo.
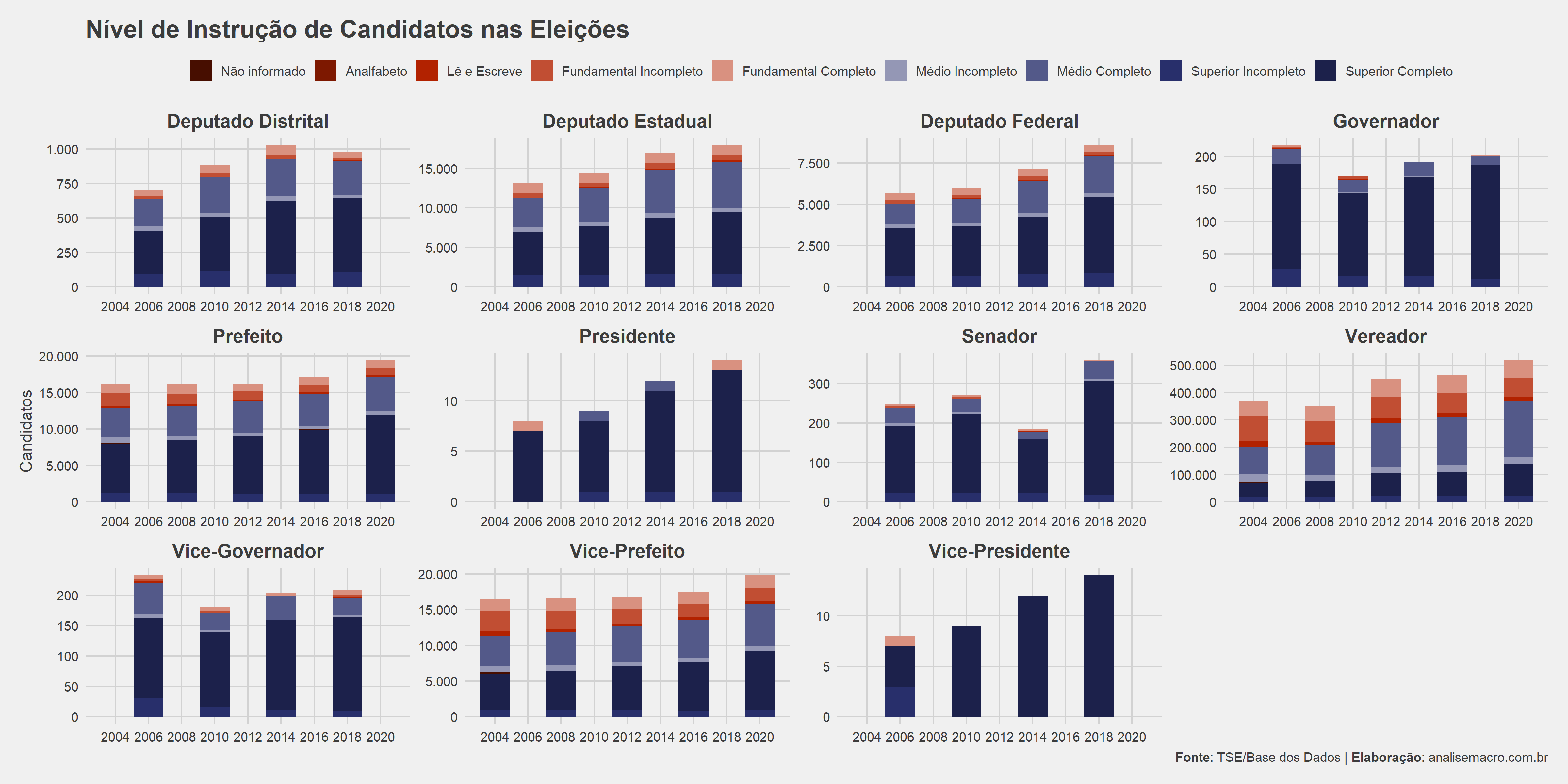
E se você precisa trabalhar com grandes volumes de dados brasileiros, mais especificamente microdados, confira o curso de Microdados Brasileiros onde mostramos como utilizar bancos de dados SQL para analisar microdados de diversos temas relevantes. Ao longo do curso você aprende a fazer análises como essa: