Picos de demanda referem-se ao consumo excessivo em determinado períodos e usualmente exibem sazonalidades múltiplas, principalmente por serem séries temporais de baixa frequência. No post de hoje, iremos tentar prever o pico de demanda diária por energia elétrica no Brasil usando o Python por meio de uma combinação de um modelo MSTL e AutoArima.
O primeiro passo é capturar os dados de curva de energia horária, em MWmed, referente ao Consumo de Energia por meio do site da ONS. Realizamos o procedimento de forma manual, baixando o arquivo .csv. A seguir, importamos o arquivo no Python.
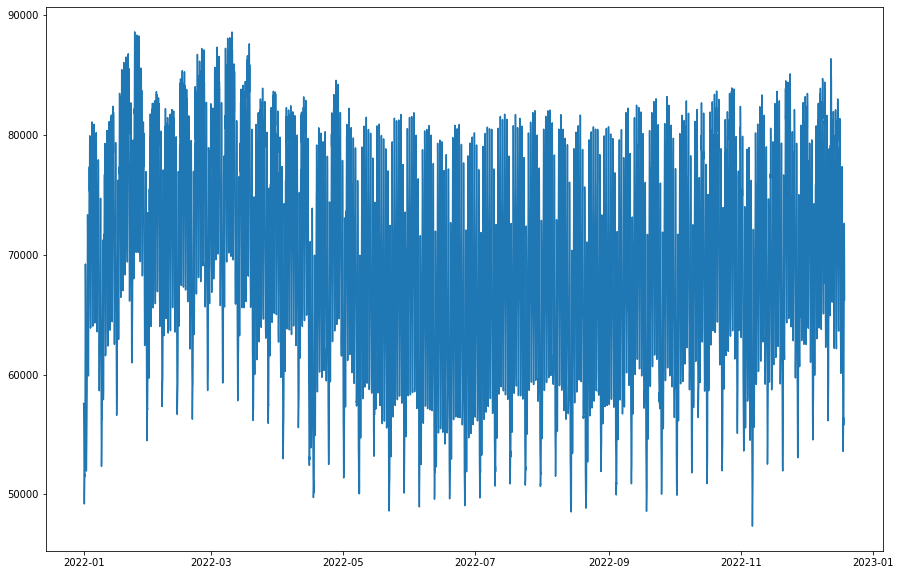
Vemos abaixo o gráfico da série em frequência horária do ínicio do ano de 2022 até 21/12/2022. É visível que há sazonalidade na série, e tomaremos essa sazonalidade com sendo a diária e a semanal.
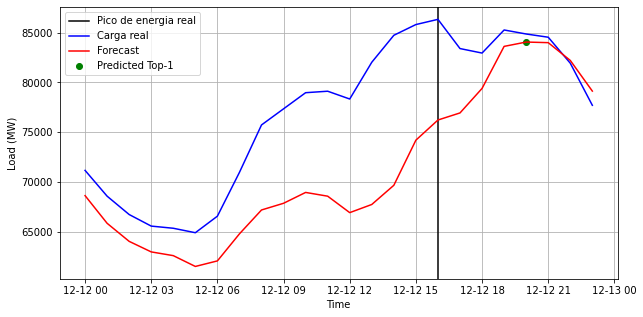
Uma vez que temos a série, a tarefa será estimar os componentes (tendência e as sazonalidades) por meio de um MSTL e realizar o ajuste da tendência por meio de um AutoArima. O modelo é estimado usando Cross Validation. No resultado abaixo, vemos no mês de setembro os valores previstos e o valor real e podemos comparar ambos. Vemos que de fato o modelo não foi suficiente para estimar o pico de energia nos valores ajustados.
Para entender todo o processo listado acima, com os códigos e video-aula, faça parte do Clube AM, o repositório de código da Análise Macro, contendo exercícios semanais de R e Python.
________________________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Ciência de dados para Economia e Finanças possuem acesso o curso Analise de dados Macroeconômicos e Financeiros e podem aprender a como construir projetos que envolvem dados reais usando modelos econométricos e de Machine Learning com o R.
Referências
Hyndman, R.J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3.

