Como estimar os efeitos de uma mudança em uma variável Y no presente e no futuro dado uma mudança em X? No post de hoje, iremos utilizar um modelo de defasagens distribuídas para estimar o efeito dinâmico de ondas de frios no preço de suco de laranja na Flórida, usando o R como ferramenta.
Efeitos Causais e séries temporais
Em estudos de efeitos causais, é comum a prática de experimentos controlados, no qual há a separação de grupo de controle e tratamento. É possível utilizar como exemplo para esses casos o uso de fertilizante em plantações: um produtor possui duas plantações do mesmo cultivo e pode escolher aplicar o fertilizante em uma e na outra não aplicar o fertilizante. A partir do resultado desse controle, é possível comparar o efeito do fertilizante, isso o efeito causal de seu uso.
Em séries temporais, principalmente séries econômicas, esse tipo de controle é impossível. Imagine por exemplo a tentativa de estimar o efeito sobre o PIB dado uma mudança do juros de curto prazo de um país. O ideal, obviamente, seria poder ter disposto diversos países iguais e pode aplicar as mudanças da taxa de juros de curto prazo em cada um, com diferentes magnitudes e obter impacto sobre o PIB. Obviamente, não vivemos em nenhuma ficção cientifica para podermos ter diversos universos paralelos, portanto, esse método é impraticável com séries temporais.
Entretanto, em séries temporais, apesar de não termos um clone do mesmo país, temos a possibilidade de obter as mudanças de taxas de juros (ou quaisquer outras variáveis) ao longo do tempo. Com isso, podemos usar o tempo a favor de obter o efeito da mudança de uma variável X sobre uma variável Y.
Laranjas e dias gelados em Orlando
A cidade de Orlando, na Flórida, é um cidade relativamente ensolarada e quente, sendo usada para a plantação de laranjas. Essas laranjas são utilizadas na indústria local para a produção de suco de laranjas concentrados. Entretanto, em épocas diferentes do ano, há a ocorrência de ondas de frio, que levam a uma redução de produção de laranjas na cidade, o que obviamente leva ao encarecimento do preço do suco de laranja.
Vejamos, com o uso do dataset FrozenJuice, disponível no R, o gráfico da variação percentual do preço do suco de laranja mensal e o número de dias gelados no mês, ambos na Flórida.
Para obter o código de importação do dataset, da construção dos gráficos e também dos códigos subsequentes, faça parte do Clube AM, o repositório especial da Análise Macro.
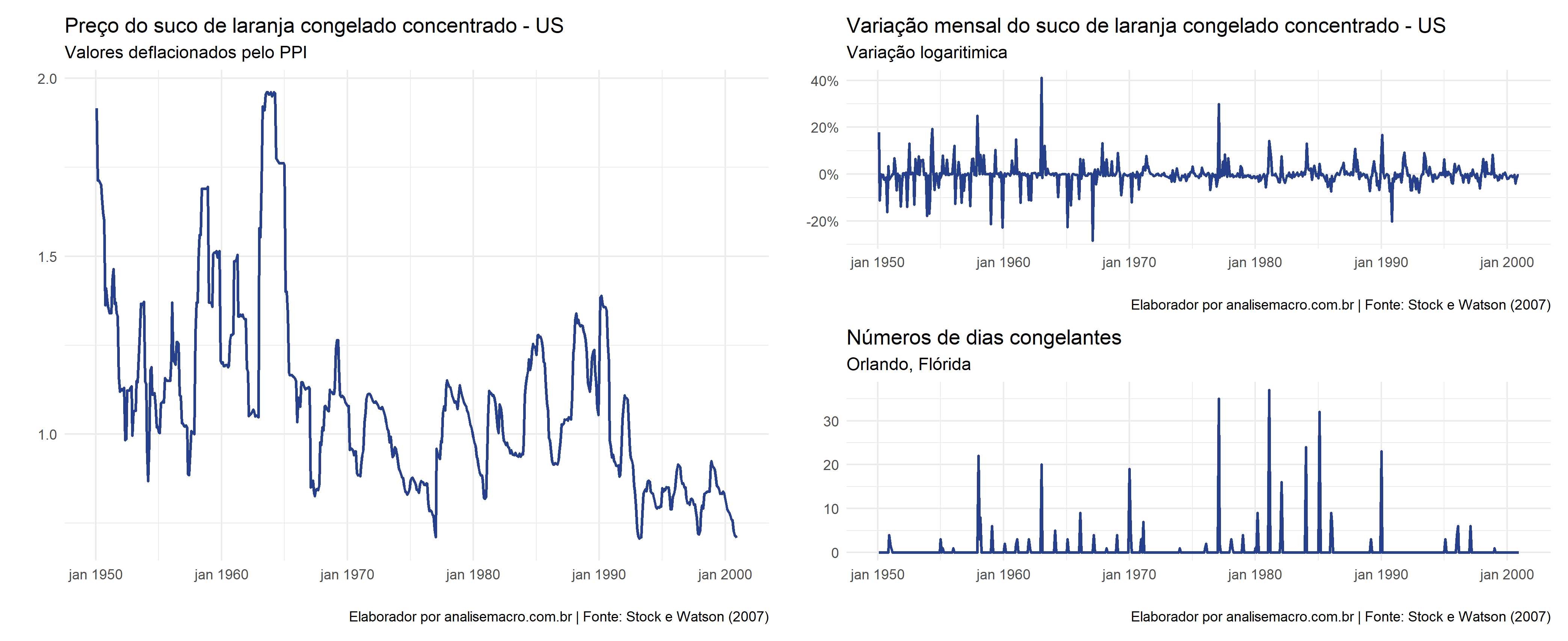
Vemos que os movimentos de crescimento do preço coincidem com o dias gelados, portanto, podemos averiguar por meio de uma Regressão Linear via MQO o efeito contemporâneo ou imediato (o efeito do mesmo ponto de observação no tempo) do dias gelado sobre o preço do suco de laranja.
Obs: O erro padrão aqui utilizado é o HAC, heteroskedasticity- and autocorrelation-consistent. Isso devido que a regressão que temos aqui possui o termo de erro e os regressores são autocorrelacionados.
Além do efeito contemporâneo, devemos lembrar que os dados são coletados ao longo do tempo, portanto, é possível estimar a trajetória temporal do efeito sobre o resultado de interesse do tratamento. As vezes há dias gelados, e as vezes não, e por vezes, o efeito dos dias gelados, possuem efeitos residuais nos dias seguintes. Isso corresponde em estimar o efeito não somente contemporâneo, mas também dinâmico.
Efeitos dinâmicos e modelos de defasagens distribuídas
O modelo econométrico para o efeito dinâmico causal necessita incorporar as defasagens do valor de X. Portanto, podemos expressar como:

onde  é um termo que inclui o erro de mensuração de
é um termo que inclui o erro de mensuração de  e o efeito dos valores das variáveis omitidas na equação. A equação acima é chamada de modelo de defasagens distribuídas.
e o efeito dos valores das variáveis omitidas na equação. A equação acima é chamada de modelo de defasagens distribuídas.
Ao aplicar nos dados de FrozenJuice, com 6 defasagens, possuímos o seguinte resultado:
Dois tipos de Exogeneidade
Um variável exógena é aquela em que a variável usada no modelo não é correlacionada com o termo de erro da regressão, enquanto o termo endógeno, representa a variável que é correlacionada com o termo de erro.
Isso representa que a variável endógena refere-se ao que é determinado dentro do modelo, enquanto exógeno é determinado fora do modelo.
Se estamos estimando usando um modelo de defasagem distribuída, o X da regressão não pode ser correlacionado com o termo de erro, portanto, é necessário o uso de uma variável exógena.
Entretanto, há dois tipos de exogeneidade em séries temporais:
- A que refere-se aos valores do passado e do presente (exogeneidade), em que:
-

- A que refere-se aos valores do passado, do presente e do futuro (exogeneidade estrita), em que:

Estimação dos efeitos causais dinâmicos com regressores exógenos
Se X é exógeno, portanto, o seu efeito causal sobre Y pode ser estimado via MQO com base na equação de regressão defasada distribuída. Para certificar que a inferência estatística seja valida, é necessário tomar algumas suposições.
Suposições
Ao criar o modelo de defasagem distribuída, devemos levar em conta algumas condições:
- X é exógeno, isto é,

- (a) A variáveis aleatórias Y e X possuem uma distribuição estacionária; (b)
 e
e  , tornam-se independentes a medida que j aumenta;
, tornam-se independentes a medida que j aumenta; - Valores extremos na amostra não são desejados;
- Não existe multicolineariedade perfeita.
 e
e  , tornam-se independentes a medida que j aumenta;
, tornam-se independentes a medida que j aumenta;Multiplicadores dinâmicos e Multiplicadores Dinâmicos acumulados.
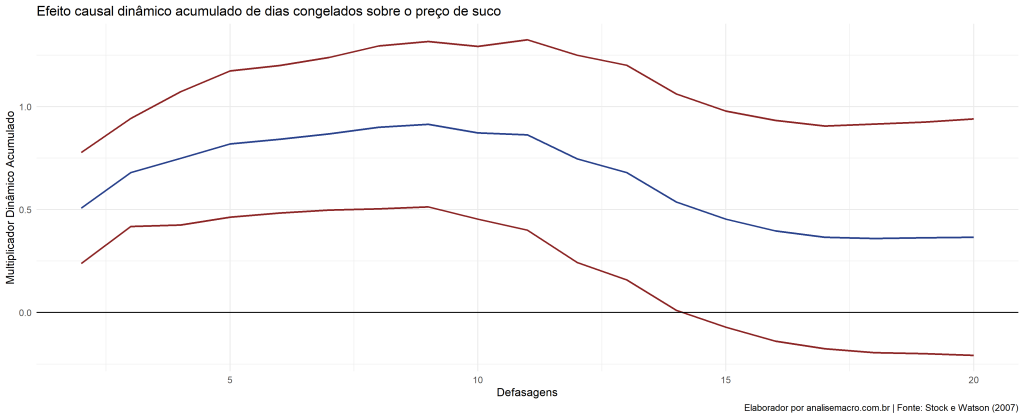
Outro nome dado para o efeito causal dinâmico é o multiplicador dinâmico. O multiplicador dinâmico acumulado é o efeito causal acumulado, até uma determinada defasagem, portanto, representa o efeito acumulado de uma mudança de X em Y.
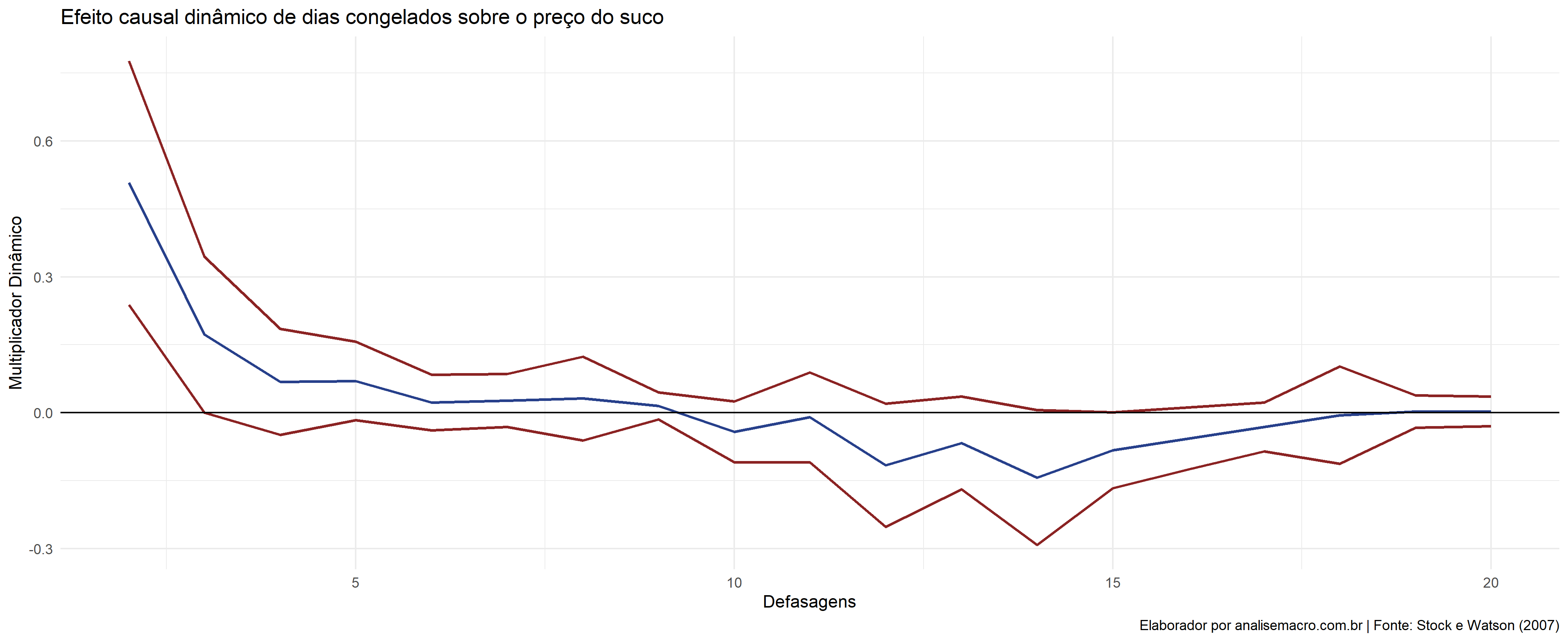
Multiplicador Dinâmico
O efeito de uma unidade de mudança de X em Y depois de h períodos, em que  , é chamada de multiplicador dinâmico em h períodos. Esse termo refere-se aos coeficientes estimados do efeito de X em Y na equação de regressão.
, é chamada de multiplicador dinâmico em h períodos. Esse termo refere-se aos coeficientes estimados do efeito de X em Y na equação de regressão.
Vejamos o cálculo do efeito de dias congelantes sobre a variação do preço do suco em Orlando.
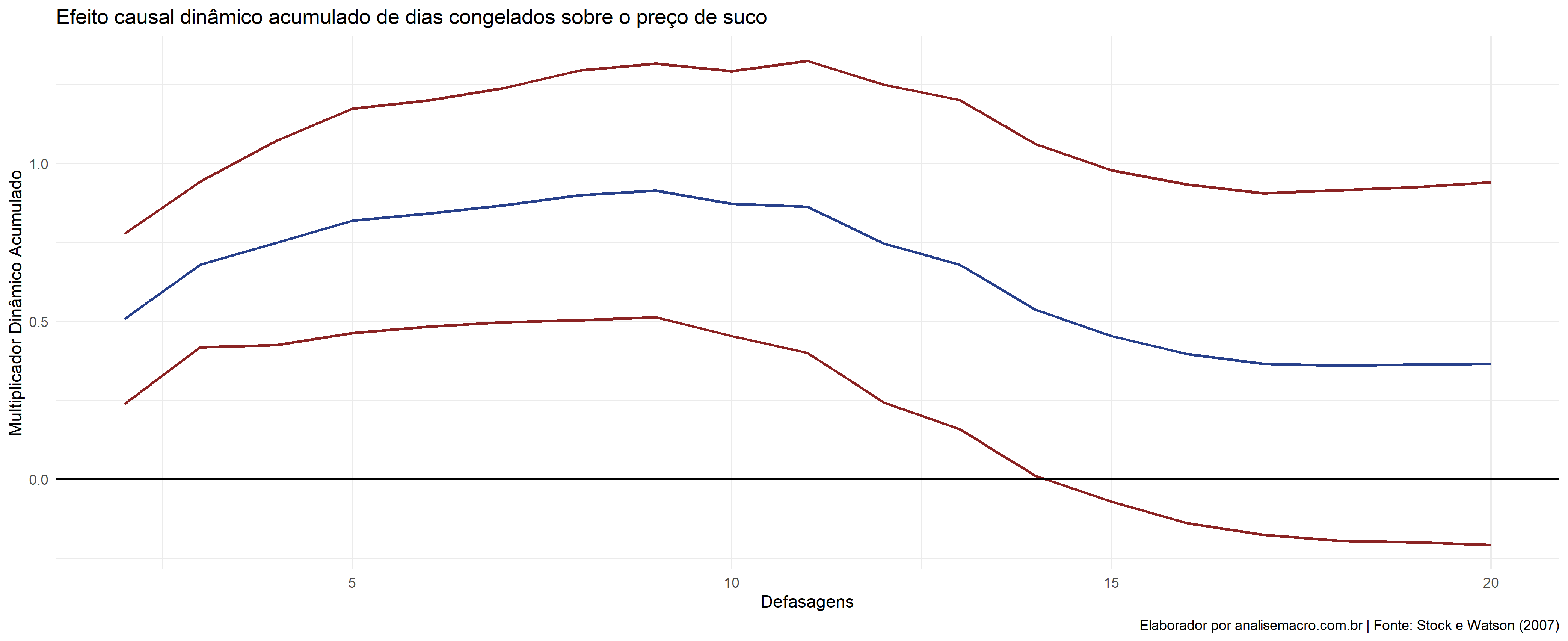
Multiplicador Dinâmico Acumulado
O Multiplicador Dinâmico Acumulado em períodos é o efeito acumulado da mudança de X em Y em h períodos. Em outras palavras, isso o Multiplicador Dinâmico acumulado é a soma do Multiplicador Dinâmico, isso é, a soma dos coeficientes das defasagens. A soma de todos os coeficiente  , é o efeitos de longo prazo acumulado de Y dado uma mudança de X.
, é o efeitos de longo prazo acumulado de Y dado uma mudança de X.
________________________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Ciência de dados para Economia e Finanças podem aprender a como construir projetos que envolvem dados reais usando modelos econométricos e de Machine Learning com o R.
Referências
Stock, J.H. e Watson, M.W. (2007). Introduction to Econometrics, 2nd ed. Boston: Addison Wesley.
Hanck, C.; Arnold, M., Gerber, A.; Schmelzer, M.. Introduction to Econometrics with R. Acessado em: "https://www.econometrics-with-r.org/index.html".

