A Pesquisa Nacional por Amostra de Domicílios Contínua (PNADc) é uma importante fonte de dados que descreve de modo detalhado a situação da população brasileira. Suas tabelas incluem dados de diversos temas, como instrução, trabalho, famílias e características dos domicílios, sendo assim uma fonte ampla para pesquisas e análises aprofundadas. É possível analisar facilmente os Microdados da pesquisa usando o R por meio do pacote {PNADcIBGE}.
PNADc
A PNADc visa acompanhar as flutuações trimestrais e a evolução, no curto, médio e longo prazos, da força de trabalho, e outras informações necessárias para o estudo do desenvolvimento socioeconômico do País. Para atender a tais objetivos, a pesquisa foi planejada para produzir indicadores trimestrais sobre a força de trabalho e indicadores anuais sobre temas suplementares permanentes (como trabalho e outras formas de trabalho, cuidados de pessoas e afazeres domésticos, tecnologia da informação e da comunicação etc.), investigados em um trimestre específico ou aplicados em uma parte da amostra a cada trimestre e acumulados para gerar resultados anuais, sendo produzidos, também, com periodicidade variável, indicadores sobre outros temas suplementares. Tem como unidade de investigação o domicílio.
Os dados da pesquisa são totalmente desagregados e com um tamanho amostral considerável, portanto, eles são dispostos em microdados que exigem cuidados na sua importação e análise.
Microdados PNADc
Microdados consistem no menor nível de desagregação dos dados de uma pesquisa, retratando, sob a forma de códigos numéricos, o conteúdo dos questionários, preservado o sigilo das informações. Os microdados possibilitam aos usuários, com conhecimento de linguagens de programação ou softwares de cálculo, criar suas próprias tabelas.
A PNAD Contínua possui três tipos de microdados:
- Trimestral, que contém a parte básica investigada pela pesquisa, contendo variáveis conjunturais de mercado de trabalho referentes a um trimestre civil;
- Anual acumulados em determinada visita, que contém temas e tópicos suplementares pesquisados ao longo do ano em determinada visita;
- Anual concentrados em determinado trimestre, que contém temas e tópicos suplementares pesquisados em trimestres específicos do ano.
Mas como coletar esses dados? É possível facilitar esse trabalho utilizando o pacote {PNADcIBGE} criado por Gabriel Assunção. Usando o pacote, coleta-se as diversas variáveis disponíveis na pesquisa em determinado período de tempo. Abaixo, realizamos duas possibilidades de uso dos dados.
A construção de todos os procedimentos para a coleta e criação dos gráficos abaixo você pode obter fazendo parte do Clube AM, o repositório especial de códigos da Análise Macro.
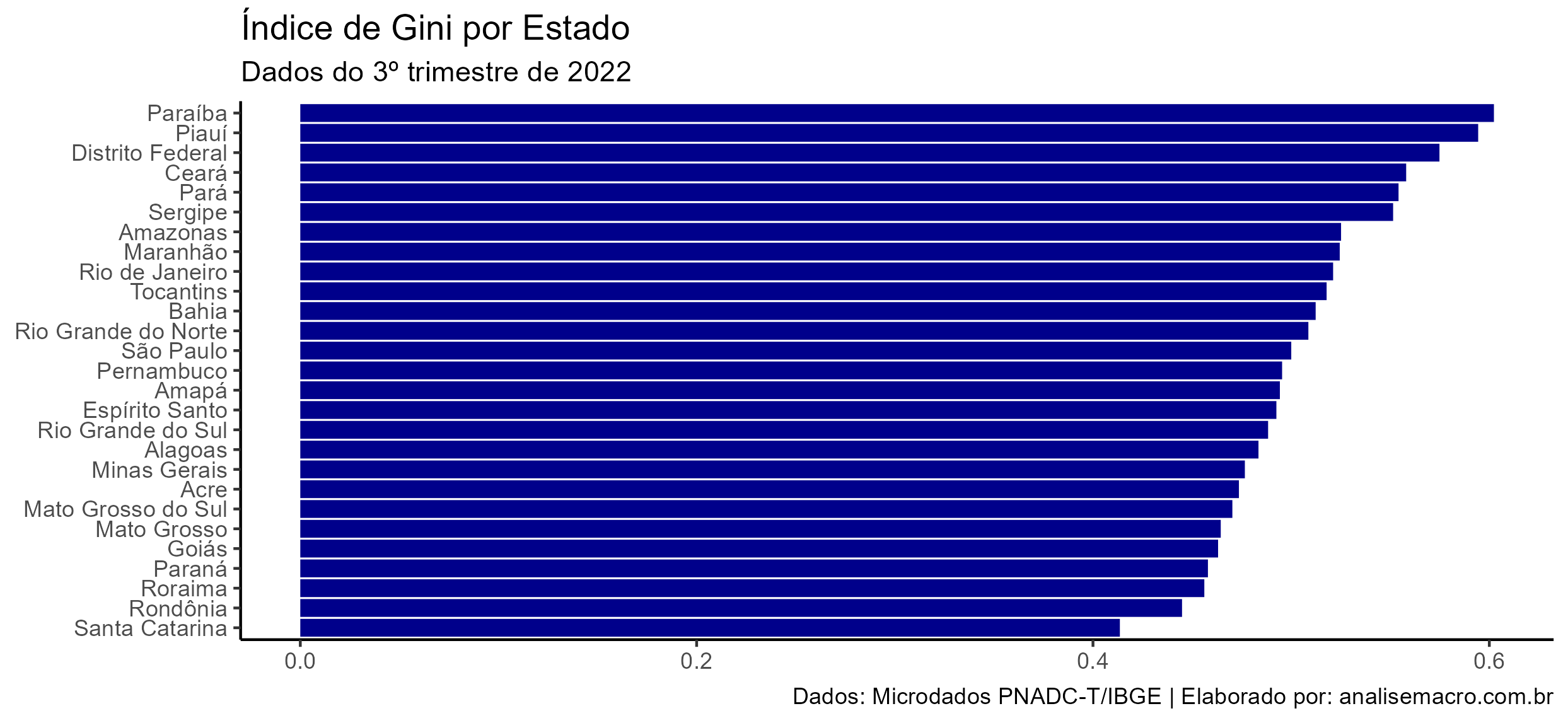
Análise da PNADc: Índice de Gini
O índice de Gini é uma medida de distribuição de renda muito interessante e conhecida, que tenta expressar em um valor único a desigualdade apresentada na curva de Lorenz. Neste exercício mostramos como podemos estimar essa medida facilmente no R.
O índice de Gini consiste em um número entre 0 e 1, onde 0 corresponde à completa igualdade e 1 corresponde à completa desigualdade e pode ser calculado com a fórmula de Brown abaixo:
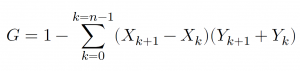
Onde:
G = coeficiente de Gini
X = proporção acumulada da variável "população"
Y = proporção acumulada da variável "renda"
Para esse exercício usaremos os microdados da PNAD Contínua trimestral do IBGE, que possui a variável Rendimento mensal efetivo de todos os trabalhos (VD4020). E para tornar o exercício interessante faremos a estimação do índice de Gini por estado (UF) brasileiro.
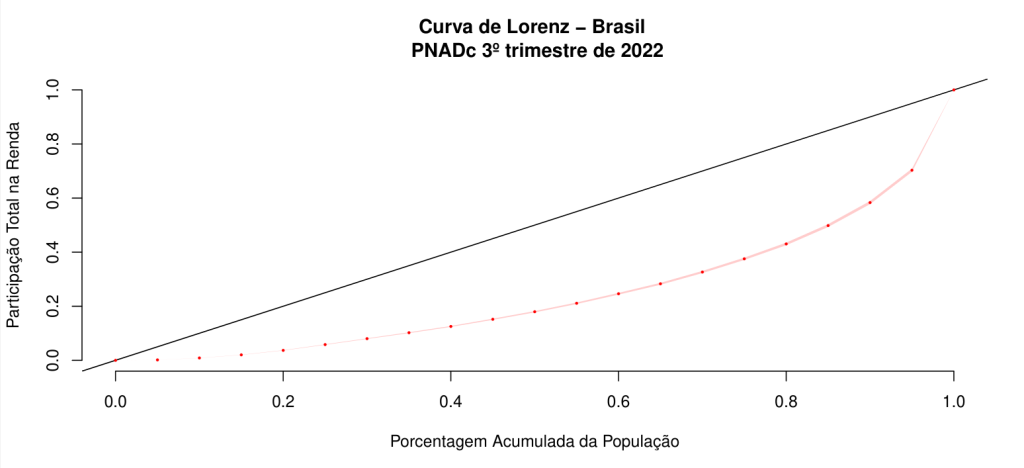
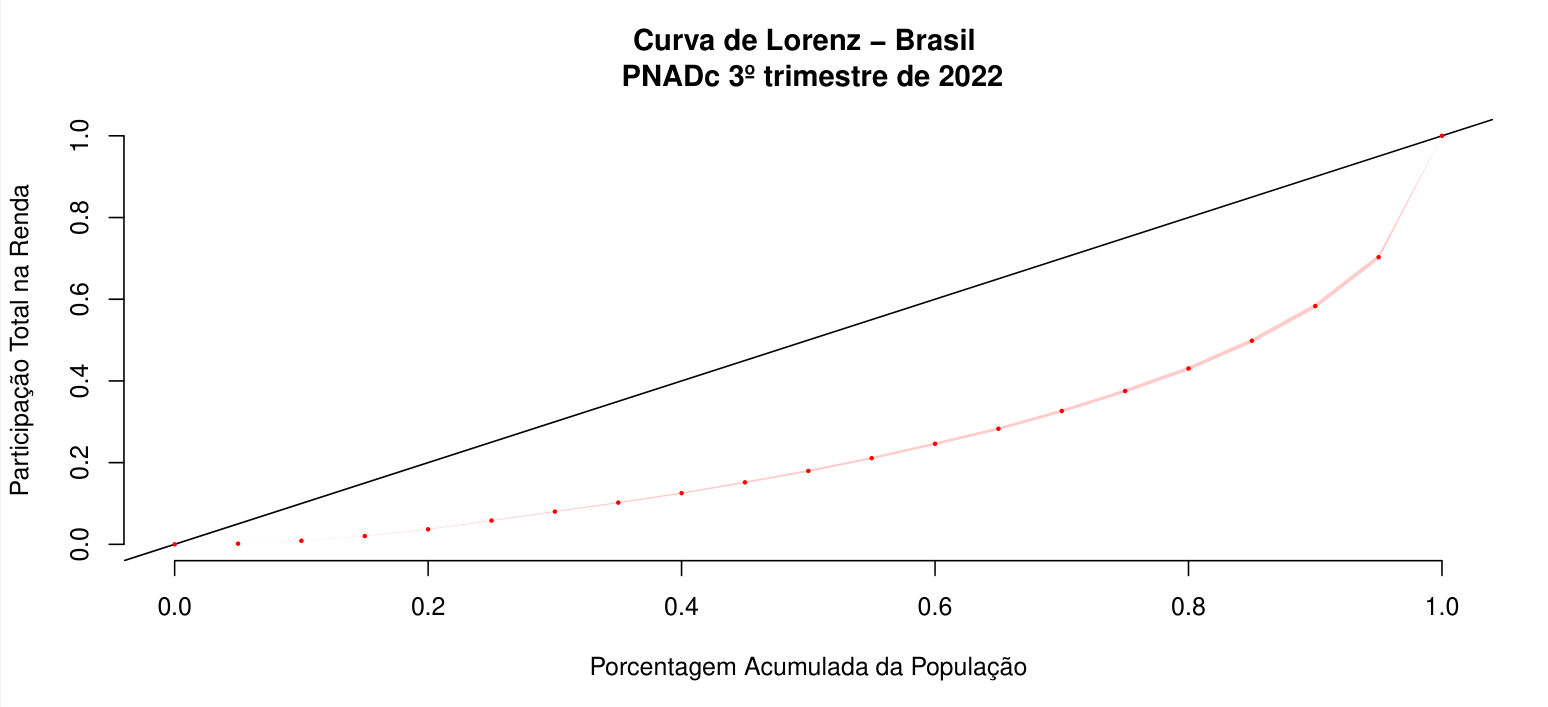
Analise da PNADc: Curva de Lorenz
A curva de Lorenz é um simples instrumental gráfico e analítico que nos permite descrever e analisar a distribuição de renda em uma sociedade, além de permitirem que ordenamos distribuições de renda sob um ponto de vista de bem-estar.
A curva de Lorenz é uma linha que representa a distribuição cumulativa da renda ou riqueza de uma população, colocando em ordem crescente a porcentagem da população em um dos eixos e a porcentagem da renda ou riqueza acumulada por essas pessoas no outro eixo. A linha de 45 graus que vai do canto inferior esquerdo até o superior direito do gráfico representa uma distribuição igualitária da renda ou riqueza, enquanto a curva de Lorenz mostra o quão distante a distribuição atual está da igualdade.
Quanto mais a curva de Lorenz se afasta da linha de igualdade, maior é a desigualdade na distribuição de renda ou riqueza.
________________________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Especialista em Avaliação de Políticas Públicas podem aprender a como construir projetos que envolvem dados reais usando microdados, análise exploratória e modelos estatísticos/econométricos.
Referências
Assunção, G. (2023). Análise de microdados da PNAD Contínua https://rpubs.com/gabriel-assuncao-ibge/pnadc Acesso em: 27/02/2023.

