Tidymodels é uma coleção de pacotes no R construídos para dar suporte ao desenvolvimento de modelos de Machine Learning. No post de hoje, vamos conhecer brevemente esse conjunto de pacotes.
Tidymodels
O tidymodels é um conjunto de pacotes R que fornecem uma abordagem organizada e coerente para a modelagem de dados. Ele se concentra em tornar a modelagem de dados mais fácil, mais consistente e mais eficiente por meio da utilização de uma sintaxe padronizada, compartilhamento de recursos e automação.
No conjunto dos pacotes, há uma variedade de ferramentas para a modelagem de dados, como pré-processamento de dados, seleção de variáveis, validação cruzada, ajuste de hiperparâmetros e avaliação de modelos. O objetivo é permitir que os usuários criem, ajustem e avaliem modelos de forma mais rápida e fácil, sem ter que se preocupar com detalhes técnicos ou se lembrar de comandos específicos.
O ponto forte do tidymodels é que foi construído em cima da infraestrutura do tidyverse, o que significa que ele segue os mesmos princípios de organização e estilo de codificação. Isso torna a integração com outros pacotes do tidyverse, como ggplot2 e dplyr, fácil e natural.
Na imagem abaixo, compreendemos a relação de cada etapa do processo de modelagem e o uso de cada pacote na etapa.
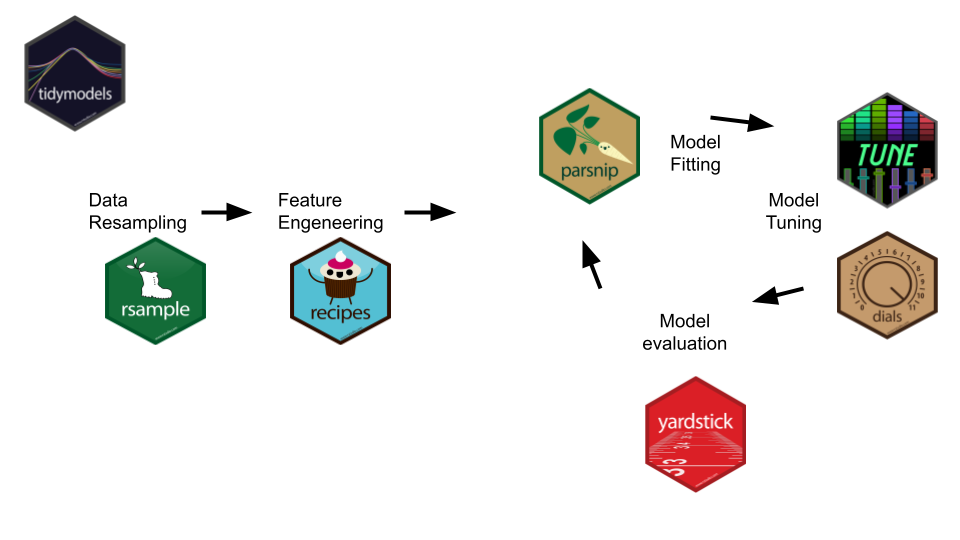
- Data Resampling: O pacote {rsample} contém funções que permitem criar diferentes tipos de reamostragem e classes de objetos para análises.
- Feature Engeneering: O pacote {recipes} permite utilizar funções no estilo do pacote {dplyr}, para criar um conjunto de passos de feature engineering nos dados.
- Model Fitting: O pacote {parsnip} oferece os modelos de Machine Learning para especificar, desenvolver e gerar previsões.
- Model Tuning: Os pacotes {tune} e {dials} permitem ajustar os modelos.
- Model Evaluation: o pacote {yardstick} permite avaliar as métricas do modelo.
Exemplo no R
Para obter o código da coleta, tratamento, visualização e dos testes estatísticos abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
Exploração dos dados
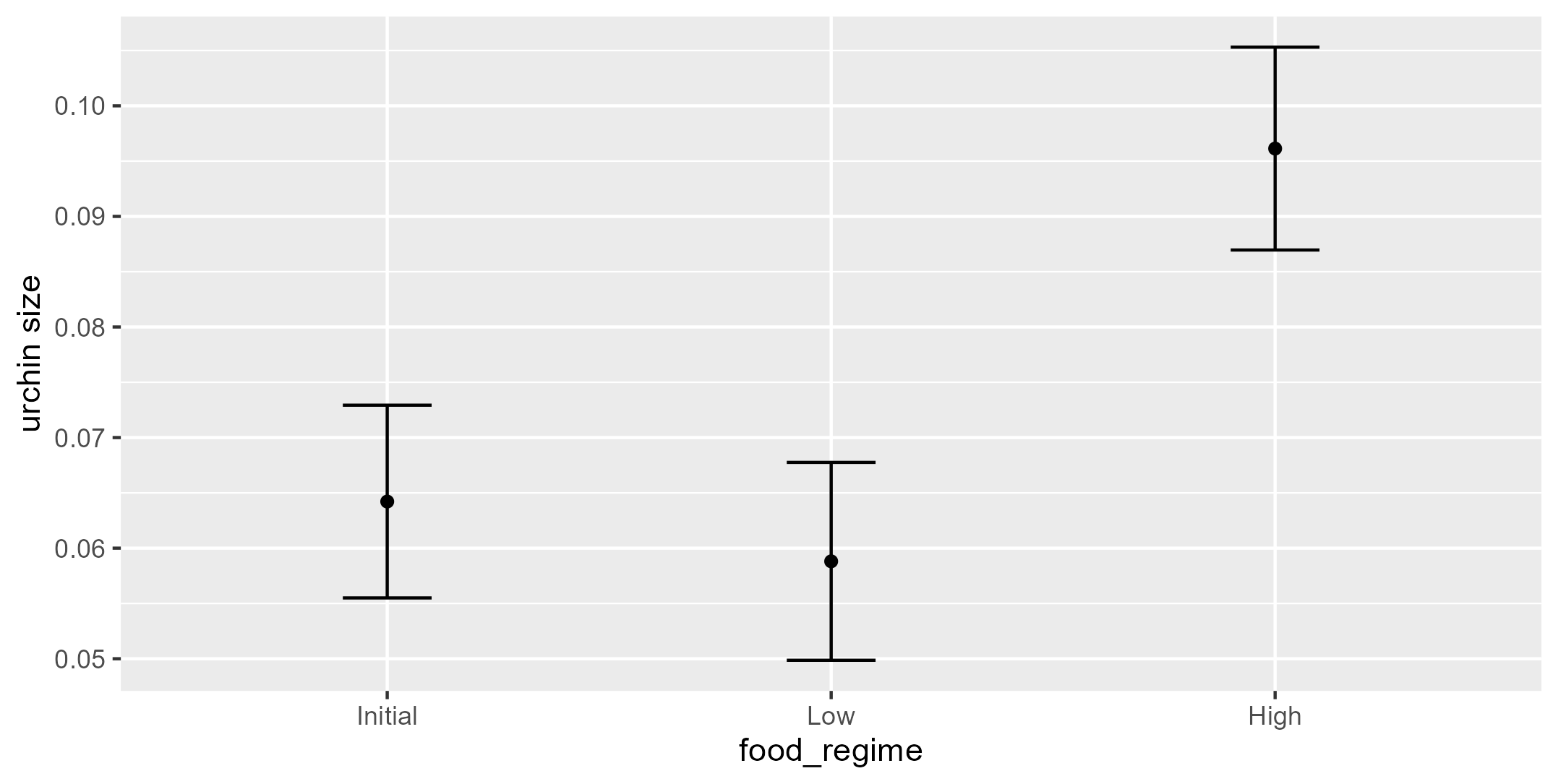
Vamos usar como exemplo o dataset de Constable (1993), para explorar como três tipos de dietas diferentes afetam o tamanho do ouriço do mar ao longo do tempo. Veremos que o peso inicial do ouriço do mar provavelmente é um fator de maior significância em quão maior ficam conforme são alimentados.
Uma vez importado o dataset no R, verificamos brevemente a relação das três variáveis contidas no dataframe: initial_volume (volume inicial do ouriço), food_regime (tipo de dieta) e width (largura). A relação pode ser verificada por um gráfico de dispersão igual ao abaixo.
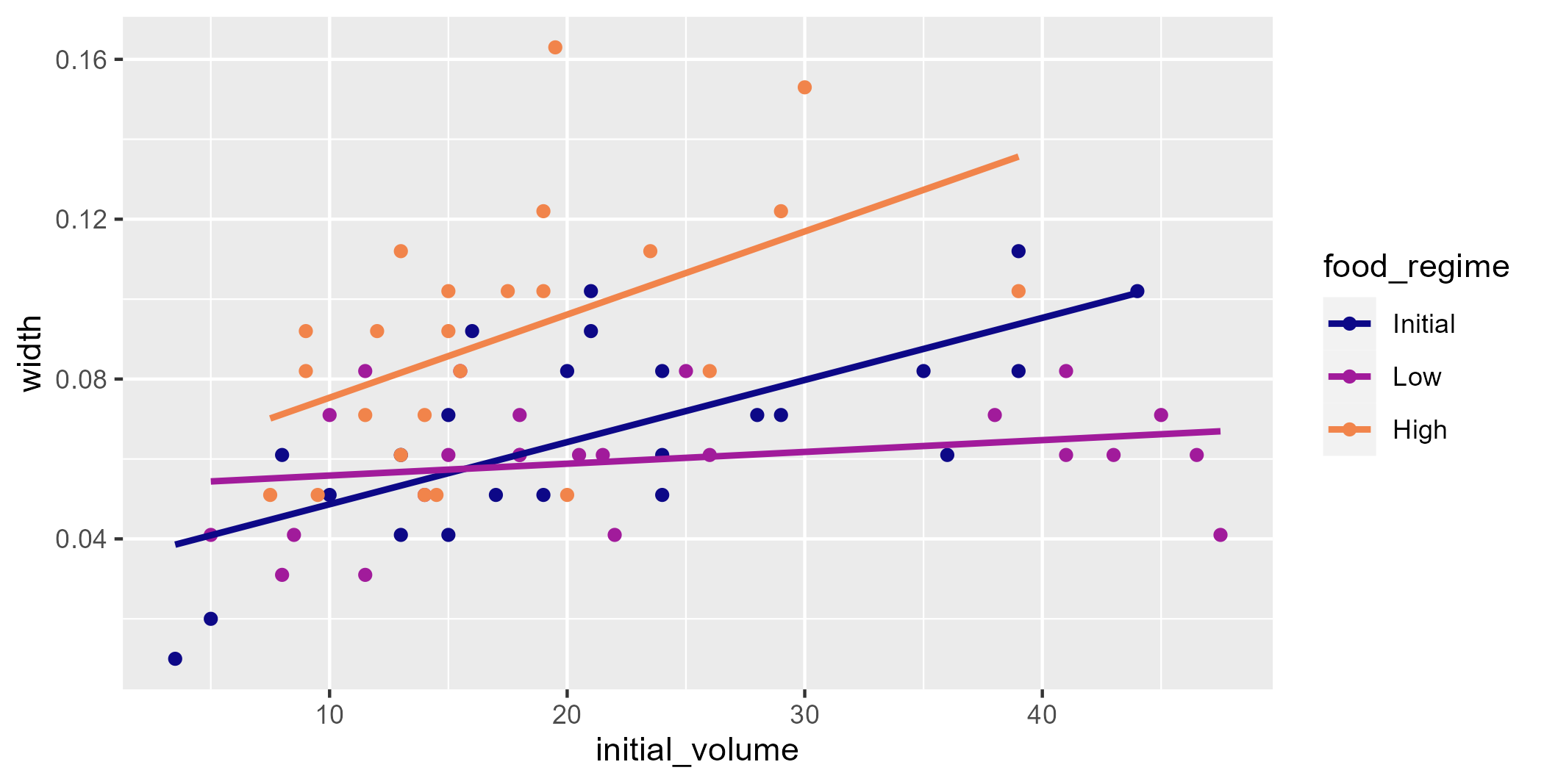
Vemos que há de fato relação positiva entre o volume inicial e a largura do ouriço do mar, entretanto, com diferentes inclinações para cada tipo de dieta. Para dietas de maiores quantidades (High) há, obviamente, maiores ganhos de peso, enquanto para dietas de menores quantidades, há menor ganho de peso.
Fit
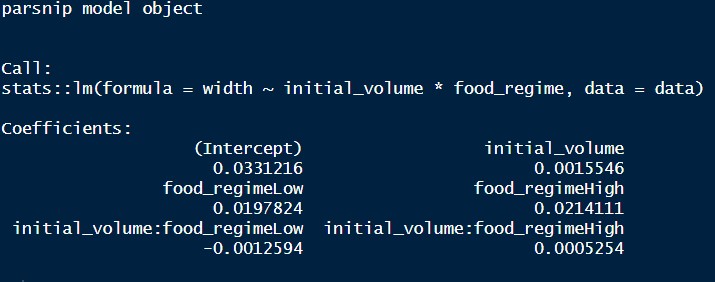
Usando o pacote {parsnip}, é possível especificar e modelar uma regressão linear, que tenha a seguinte fórmula: width ~ initial_volume * food_regime, que permite que o volume inicial tenha diferentes interceptos e inclinações de acordo com cada dieta.
O output do modelo tem o seguinte resultado:
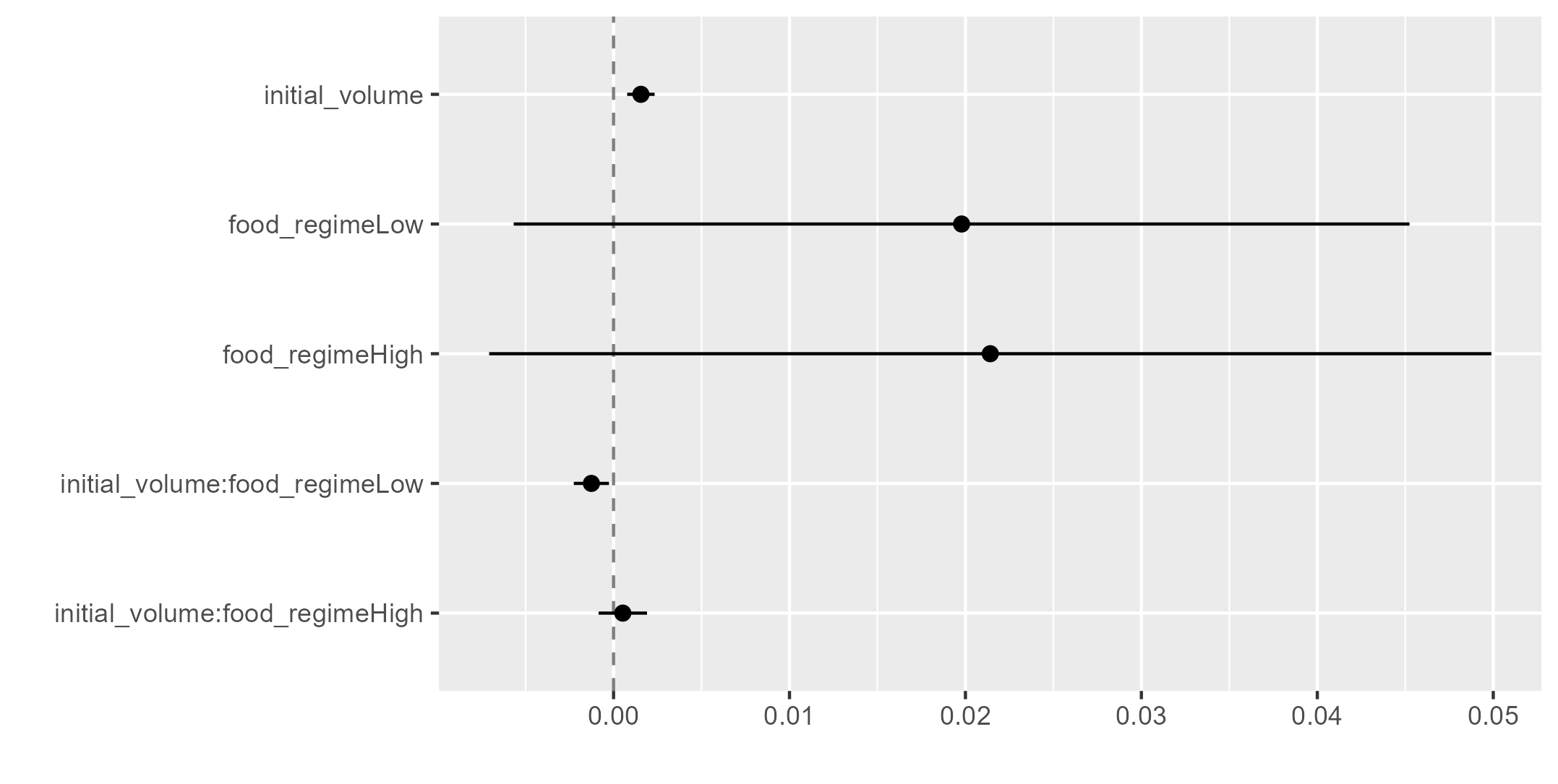
Para facilitar a visualização dos parâmetros acima, podemos utilizar o pacote {dotwhisker} para auxiliar. O gráfico abaixo exibe os coeficientes e o intervalo de seus erros.
 Previsão
Previsão
Agora que temos conhecimento do relacionamento entre o volume inicial, o tipo de dieta e largura dos ouriços do mar, podemos utilizar o modelo construído para prever a largura dos ouriços.
 _________________________________
_________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Especialista em Ciência de Dados para Economia e Finanças podem aprender a como construir projetos que envolvem dados reais usando o R e o Python como ferramentas.
Referências
Constable, A.J. The role of sutures in shrinking of the test in Heliocidaris erythrogramma (Echinoidea: Echinometridae). Marine Biology 117, 423–430 (1993).

