Look-ahead bias é um termo usado na análise de dados e na tomada de decisões que se refere a um tipo de viés que ocorre quando as informações disponíveis no momento atual são utilizadas para fazer previsões ou tomar decisões que deveriam ter sido baseadas somente nas informações disponíveis no momento em que as decisões foram tomadas originalmente.
Esse tipo de viés ocorre quando informações futuras são incluídas indevidamente nas decisões tomadas no passado, levando a resultados distorcidos ou imprecisos. Por exemplo, em um modelo quantitativo, um look-ahead bias pode ocorrer quando informações futuras sobre o desempenho de um determinado ativo são utilizadas para tomar decisões de investimento no passado, o que pode levar a resultados superestimados e perdas financeiras significativas.
 Vamos pensar em um exemplo. Um analista quantitativo que trabalha criando análises de investimentos usando dados financeiros de empresas, e que deseja verificar o impacto da divulgação das demonstrações contábeis trimestrais de empresas listadas na bolsa de valores. Ao utilizar os dados históricos dos demonstrativos, o analista cria a análise tomando como base a data de divulgação dos demonstrativos na mesma data de fim do trimestre fiscal.
Vamos pensar em um exemplo. Um analista quantitativo que trabalha criando análises de investimentos usando dados financeiros de empresas, e que deseja verificar o impacto da divulgação das demonstrações contábeis trimestrais de empresas listadas na bolsa de valores. Ao utilizar os dados históricos dos demonstrativos, o analista cria a análise tomando como base a data de divulgação dos demonstrativos na mesma data de fim do trimestre fiscal.
Obviamente, isso não pode ser tomado como verdadeiro na análise. Qualquer efeito produzido pela divulgação dos demonstrativos devem ser analisadas no dia em que os dados foram divulgados, e que normalmente não batem com a data do fim do período fiscal. Qualquer análise fora desse período sugere visões distorcidas dos efeitos produzidos pela informação do demonstrativo (visto que a informação é do futuro, já que usualmente a data de divulgação é posterior ao fim do período fiscal). Esse é o problema de look-ahead bias.
Exemplo com o Beta de mercado no R
É muito comum encontrar o look-ahead bias em diversas aplicações de análise quantitativa, e uns dos problemas reside no uso do Beta de mercado de ações.
O Beta é uma medida de risco usada em finanças que mede a sensibilidade de um ativo em relação às mudanças no mercado geral. Ele é frequentemente usado como uma ferramenta para avaliar o risco de um portfólio de investimentos. No entanto, o uso do Beta em estratégias de investimento pode levar ao problema do look-ahead bias se as informações futuras forem usadas para calcular o Beta.
No R, podemos estimar facilmente o Beta de mercado de ações utilizando dados de retornos do preço de ações listadas na B3, utilizando o retorno do Ibovespa e também tomando como taxas livre de risco o retorno histórico do CDI. Além do Beta da amostra inteira, é possível construir o Beta móvel, isto é, o Beta em janelas de amostras fixas, tornando o indicador dinâmico.
Para entender como foi criado o gráfico e o modelo abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
Vejamos a estimação do Beta Móvel da ações ABEV3, BRFS3, ITUB4 JBSS3 e PETR4.
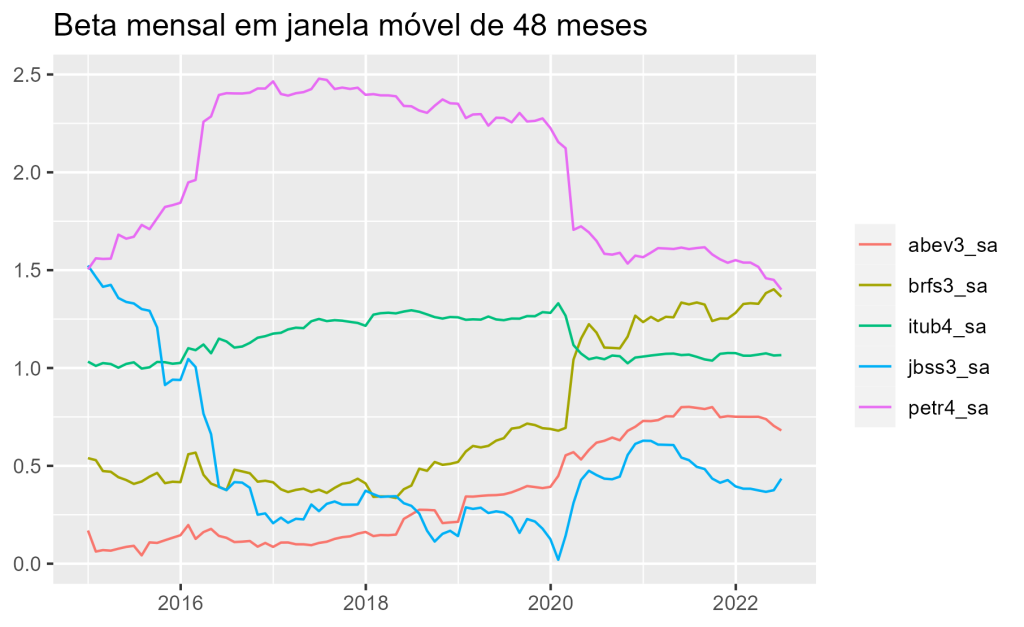 O tamanho da amostra de dados utilizado no gráfico acima é de 48 meses, ou seja, os dados passados não são utilizados a medida que o tempo transcorre e são substituídos por observações novas. Esse tipo de análise do beta é muito útil para verificar mudanças estruturais no modelo conforme o tempo passa.
O tamanho da amostra de dados utilizado no gráfico acima é de 48 meses, ou seja, os dados passados não são utilizados a medida que o tempo transcorre e são substituídos por observações novas. Esse tipo de análise do beta é muito útil para verificar mudanças estruturais no modelo conforme o tempo passa.
Entretanto, qualquer estratégia utilizando os dados acima deve levar em conta o problema de look-ahead bias. O Beta é calculado com base nos retornos históricos do ativo e do mercado, e se as informações futuras são usadas para calcular esses retornos, isso pode levar a uma estimativa imprecisa do risco do ativo e do portfólio como um todo. Por exemplo, se um investidor usa informações futuras sobre o desempenho de um ativo para calcular o Beta, ele pode superestimar o risco desse ativo e, consequentemente, fazer escolhas de investimento inadequadas.
Vamos pensar um pouco, cada Beta produzido é estimado no fim do mês com base nos dados passados disponíveis, entretanto, se realmente utilizarmos os dados desse mês, estaríamos incorrendo de um erro, pois os dados históricos do beta estimado do mês em questão não estariam disponíveis no momento da estimação Beta.
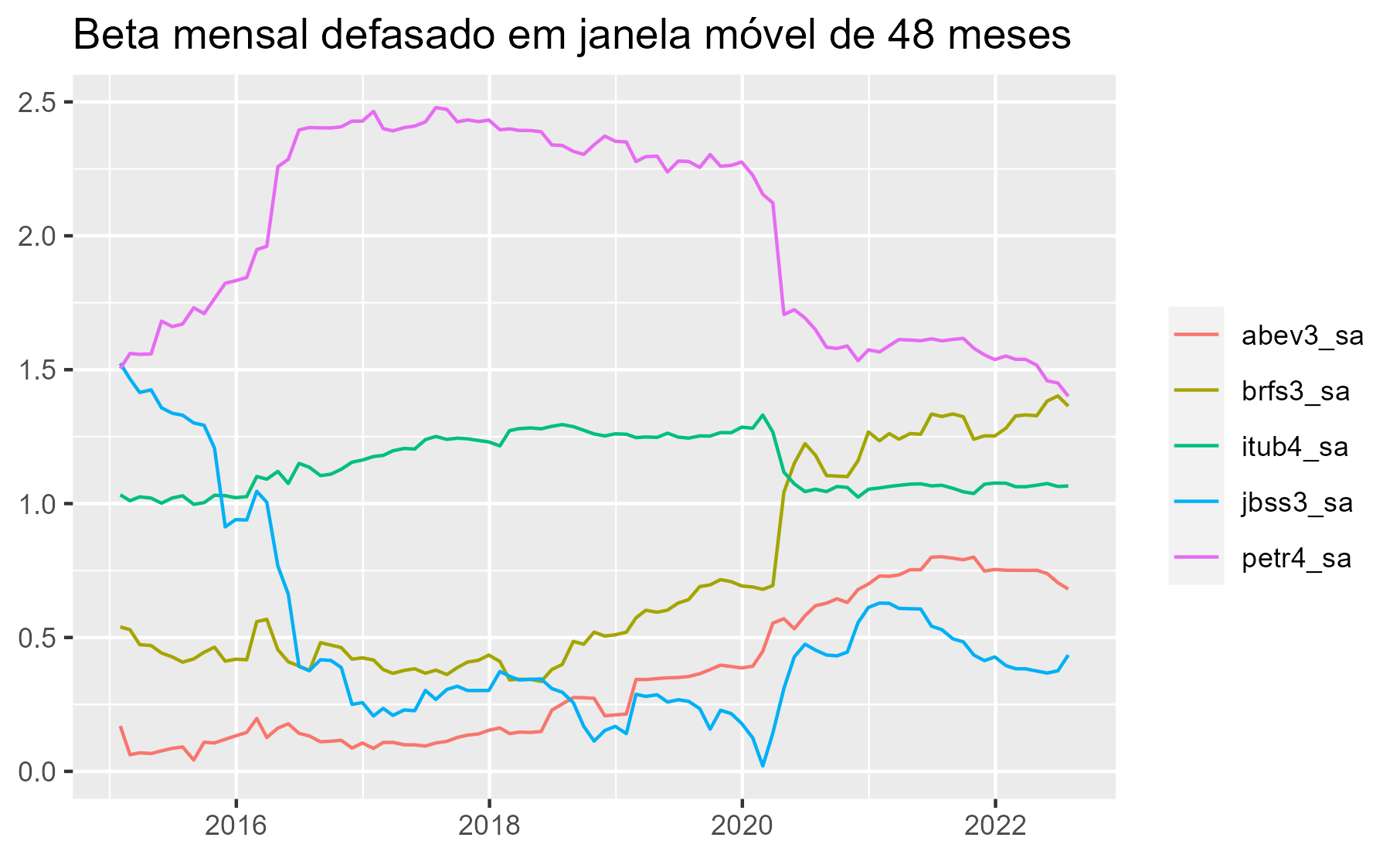
Ou seja, o valor do Beta do mês no gráfico, em circunstâncias práticas no presente, não estavam disponíveis. Nos dados históricos elas estão, pois o período já havia passado, mas no presente não estavam. Qual a solução?
Para evitar esse problema nesse exemplo, a melhor solução é defasar o Beta, assim evita-se usar a informação futura como decisão de investimento. Dessa forma, os dados no gráfico ficam levemente diferente, entretanto, não carregam informações do futuro, levando a possibilidade de diminuir o risco de ter o look-ahead bias.
_____________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas

