A curva IS é uma curva de demanda agregada da economia, descrevendo o equilíbrio no mercado de bens e serviços, sendo expressa pelo hiato do produto em função de suas próprias defasagens, da taxa real de juros e do resultado primário. Vejamos neste post a implementação da Curva IS utilizando o Python.
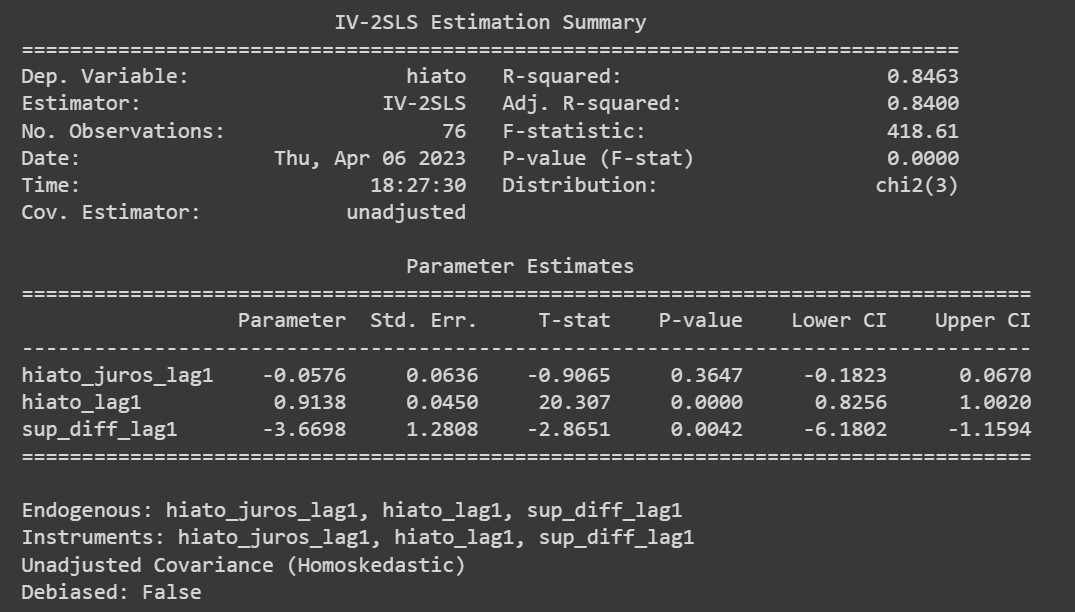
O objetivo do exercício será estimar uma versão da Curva IS do Modelo Semiestrutural de Pequeno Porte do BCB descrito nesse Relatório, conforme a equação descrita abaixo:

Basicamente, a Curva IS estimada irá descrever a dinâmica do hiato do produto com base em suas próprias defasagens, da taxa de juros real ex-ante e da variação do superávit primário.
Para obter o código do modelo abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.

