No post de hoje, continuamos com a série de postagens envolvendo exercícios de Macroeconometria no Python, investigando dessa vez a relação entre o Swap pré-DI 360 dias e a Expectativas da Selic de acordo com o Focus. Estimamos ao fim, por meio de um 2SLS com instrumentos o Prêmio.
O objetivo do exercício será modelar a curva para o prêmio do Swap pré-DI de 360 dias frente, por meio da seguinte equação, com base no RTI de Junho/2017.
(1) 
Onde  é o diferencial entre a taxa swap pré-DI de 360 dias e a expectativa para a taxa Selic para o período do contrato do swap;
é o diferencial entre a taxa swap pré-DI de 360 dias e a expectativa para a taxa Selic para o período do contrato do swap;  é uma variável representativa do prêmio de risco do país (Embi ou CDS 5 anos, por exemplo); e
é uma variável representativa do prêmio de risco do país (Embi ou CDS 5 anos, por exemplo); e  é um termo de erro.
é um termo de erro.
Para obter todo o código do processo de criação do modelo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
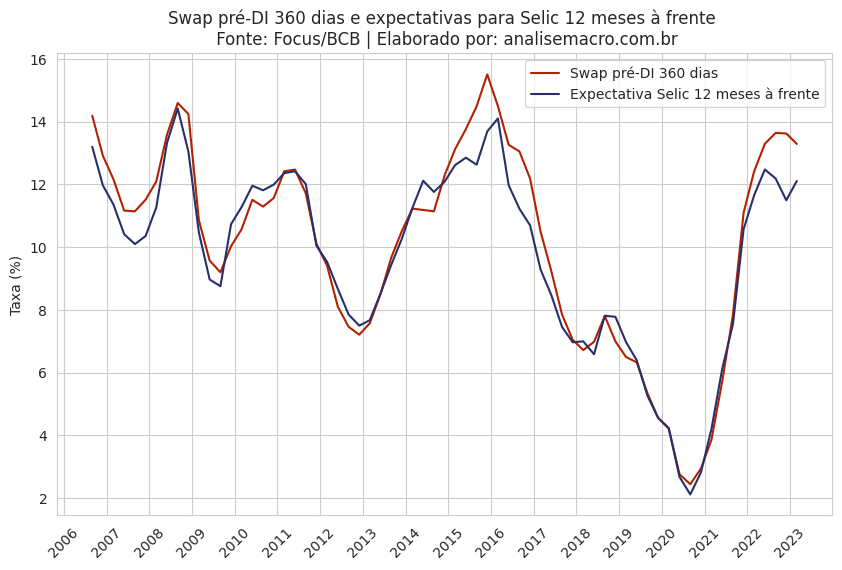
O gráfico abaixo mostra a estreita relação entre a taxa swap pré-DI 360 dias e a expectativa para a taxa Selic 12 meses à frente de acordo com a pesquisa Focus. Podemos então extrair o prêmio pela diferença entre as duas séries.
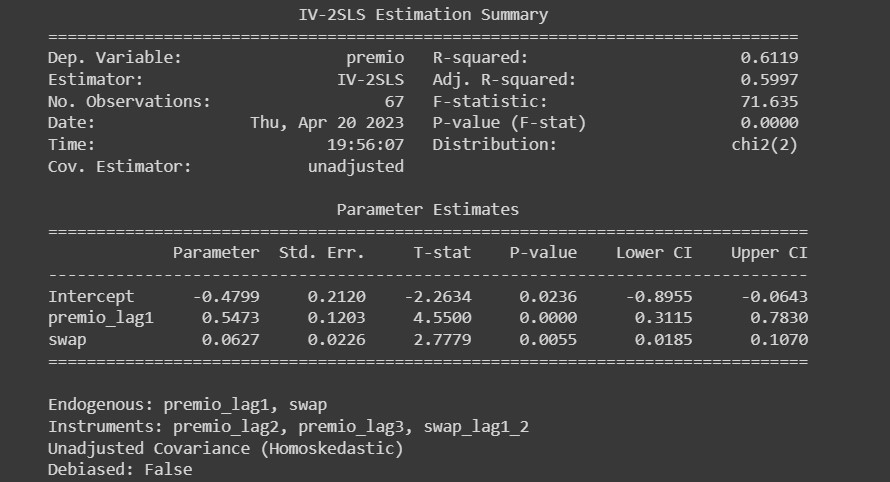
Com a coleta e tratamento dos dados por meio do Python, obtemos os seguintes resultados da regressão exposta acima.
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.

