Premissas
A volatilidade não é diretamente observável e é estimada por meio das flutuações de retorno de preços. Os retornos são iguais aos retornos médios mais os resíduos. Os resíduos são choques de retorno estocásticos dependentes do tamanho da volatilidade.
Portanto, para modelar a volatilidade, os modelos requerem premissas de distribuição dos resíduos e dos retornos médios. Quanto mais representativas dos dados reais as premissas forem, melhor o modelo criado.
Sendo assim, consideramos que
![\[r_t = \mu_t + a_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c970839f9c067b2a50bfda627d3be21e_l3.png "Rendered by QuickLaTeX.com")
![\[a_t = \sigma_t \varepsilon_t \sim N(0, \sigma^2_t)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-1c5a260d4eb37e7a12b326247d5f3607_l3.png "Rendered by QuickLaTeX.com")
onde  uma sequência de variáveis aleatórias independentes e identicamente distribuídas com média zero e variância igual 1, ou seja, um ruído branco.
uma sequência de variáveis aleatórias independentes e identicamente distribuídas com média zero e variância igual 1, ou seja, um ruído branco.
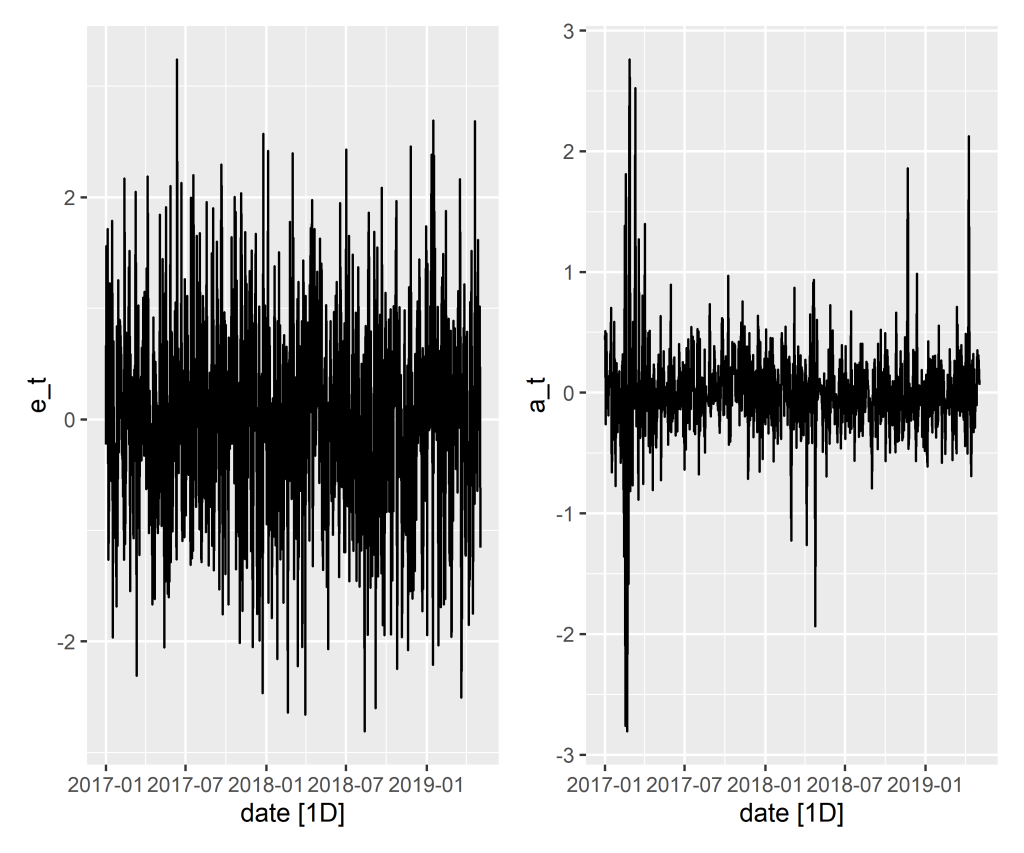
Os dois gráficos abaixo relatam o comportamento de e  , respectivamente.
, respectivamente.
Vamos, portanto, verificar as premissas sobre o valores de normalizados.
![\[\frac{r_t - \mu_t}{\sigma_t} \sim N(0, \sigma^2_t)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-238a458e082415401235d2112e883057_l3.png "Rendered by QuickLaTeX.com")
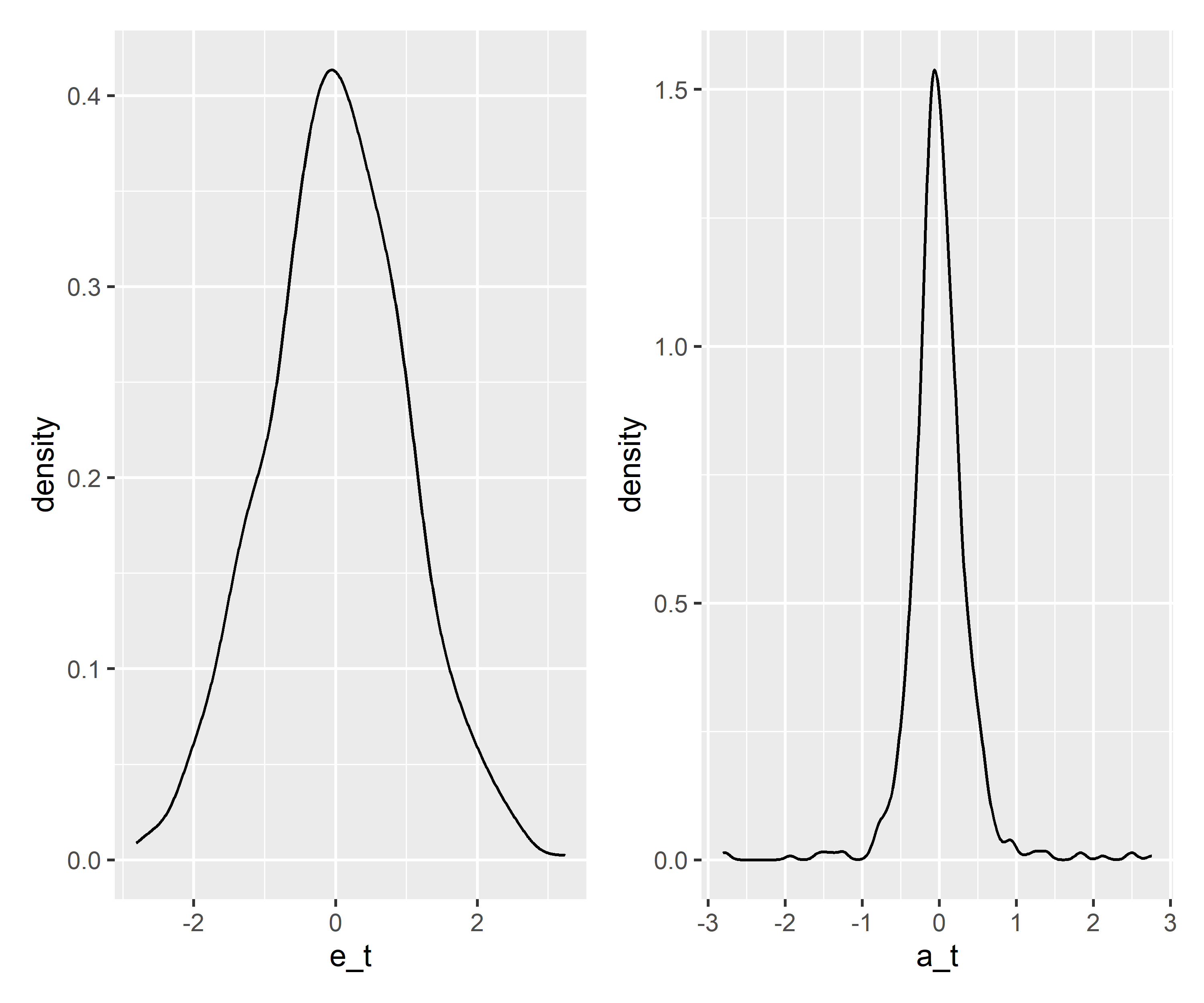
Os resíduos padronizados seguem uma distribuição, e para tornar mais realístico, devemos ter em mente:
- fat tails (caudas gordas): maior probabilidade de observar altos valores de retornos (positivos ou negativos).
- Skewness: assimetria da distribuição dos retornos.
Para solucionar podemos usar dois tipos de distribuições:
- Distribuição t de student: permite corrigir o problema de caudas gordas, levando em consideração o valor dos graus de liberdade pelo parâmetro
 (quanto menor , mais gordas as caudas).
(quanto menor , mais gordas as caudas). - Distribuição t de student assimétrica: além de corrigir as caudas gordas, leva em consideração a assimetria (skew). Quando o valor é igual a 1, a distribuição é simétrica, menor 1 que, assimetria negativa, e maior que 1, assimetria positiva.
 (quanto menor
(quanto menor Quando  e assimetria igual a 1, temos uma distribuição normal.
e assimetria igual a 1, temos uma distribuição normal.
Quando a assimetria é igual a 1, temos uma distribuição t de student.
Modelo da Média
O valor do retorno médio pode ser considerado por diferentes formas:
- Nulo
- Média amostral (constante)
- ARMA
Se lembrarmos que existe uma relação de risco ( ) e retorno (
) e retorno ( ), podemos usar o modelo da média para realizar uma leitura do comportamento da série analisada.
), podemos usar o modelo da média para realizar uma leitura do comportamento da série analisada.
Interpretação do retorno médio
Retorno médio constante
![\[\mu_t = \mu + \lambda\sigma^2_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-06384e3c48f40b42d49772254b2b4ded_l3.png "Rendered by QuickLaTeX.com")
, temos que  representa o parâmetro de risco-retorno. Isto, é o aumento no retorno esperado dado um unidade de aumento da variância (risco). (é necessário que
representa o parâmetro de risco-retorno. Isto, é o aumento no retorno esperado dado um unidade de aumento da variância (risco). (é necessário que  seja positivo).
seja positivo).
AR
![\[\mu_t = \mu + \rho(r_{t-1} - \mu)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-3337c08ce02c54a6a3c860cd294a7873_l3.png "Rendered by QuickLaTeX.com")
, se  for positivo, prevemos que quando o retorno está acima de
for positivo, prevemos que quando o retorno está acima de  , o próximo valor também estará acima de e vice-versa.
, o próximo valor também estará acima de e vice-versa.
se  significa reversão à média, isto é, os desvios de
significa reversão à média, isto é, os desvios de  de serão transitórios.
de serão transitórios.
MA
![\[\mu_t = \mu + \theta(r_{t-1} - \mu_{t-1})\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-e388f598e713d0273f0db2bd491971d0_l3.png "Rendered by QuickLaTeX.com")
prevê o retorno considerando o valor o retorno passado de sua média condicional.
Performance
Ao analisar um modelo de volatilidade, devemos manter a parcimoniosidade, isto é, devemos manter o menor número possível de parâmetros estimados e preferir modelos mais simples do que complexos, se possível.
Para isso, verificamos se:
- O p-value dos parâmetros são menores que 0,05 para rejeitar a hipótese nula de que o valor do parâmetro não é 0. Se for, retire-o;
- Para auxiliar a validação, verificamos se o módulo da t-statistic é maior que 2;
- Visualização do gráficos dos resíduos padronizados, que devem ser visualmente iguais a um ruído branco;
- Não deve haver Autocorrelação dos resíduos padronizados. Podemos verificar através do gráfico FAC (ACF) ou pelo teste de Ljung-Box, que testa H0 se os dados são distribuidos independemente (o valor deve ser p > 0,05);
- Para verificar se o modelo pode explicar muito bem os dados históricos por meio dos valores ajustados, utiliza-se os critérios de informação AIC e BIC, que permitem avaliar o trade-off de um modelo bem ajustado e de complexidade. Quanto menor, melhor;
Previsão
A previsão de modelos ARCH e GARCH segue os mesmos passos do modelo ARIMA. Prevê-se um passos à frente; com o resultado, realiza-se o passo seguinte e assim sucessivamente.
Para ilustrar, vemos o caso de um GARCH (1,1) que comece em  :
:
![\[\hat{\sigma}_t(1) = \omega + \alpha_1 a^2_t + \beta_1 \sigma^2_1\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-9ffd95ae4fe1bdffd379bde2c1b51089_l3.png "Rendered by QuickLaTeX.com")
Para 
![\[\hat{\sigma}_t(l) = \omega + (\alpha_1 + \beta_1) \hat{\sigma}_t(l - 1), \quad l > 1\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-7736024393c427c95a7848da7cb61ce4_l3.png "Rendered by QuickLaTeX.com")
Backtesting
Backtesting é um método para avaliar a qualidade de uma previsão. Comparamos os resultados previstos pelo modelo com os dados históricos para verificar o quão próximo eles estão.
Separamos os dados históricos em duas partes:
- In-sample (dentro da amostra): são usados para o ajuste.
- Out-of-sample (fora da amostra): sõa reservados para o backtesting para avaliar o desempenho.
Portanto, para gerar um backtesting eficiente, temos que:
- Dividir o data set em uma subamostra de estimação e previsão;
- Estimar o modelo utilizando a subamostra de estimação e utilizar o modelo estimado para gerar a previsão ℎ passos à frente, onde ℎ é igual ao tamanho da subamostra de previsão;
- Comparar as previsões geradas com as observações da subamostra de previsão.
Desse posse do erro de previsão, é possível calcular algumas métricas de acurácia.
A primeira consiste simplesmente na média da série de erros de previsão, isto é, o erro médio (ME), dado conforme segue:
(1) 
A segunda é a raiz quadrada do erro médio (RMSE), dada por
(2) 
A terceira medida, por sua vez, é dada pela média dos erros em valores absolutos ou simplesmente erro médio absoluto (MAE), expressa conforme
(3) 
Essas três medidas fazem parte do grupo de medidas que dependem da escala na qual os dados estão. Logo, elas podem ser utilizadas para efeito de comparação de diferentes modelos aplicados a mesma amostra de dados.
A quarta medida é o erro médio percentual (MPE), isto é,
(4) 
A quinta medida é o erro médio absoluto percentual (MAPE), dado conforme
(5) 
Por se tratarem de percentuais, essas medidas não são sensíveis à escala dos dados.
Rolling Window
Podemos estimar e gerar previsões dos modelos de volatilidade em janelas deslizantes, isto é, utilizar janelas da amostra com o objetivo de performar repetidamente o ajuste e a previsão a medida que o tempo avança.
Há dois métodos que podemos utilizar:
- Janela não fixa: o tamanho da amostra começa em um valor determinado e aumenta conforme o tempo avança.
- Janela fixa: o tamanho da amostra fica fixo conforme o tempo avança, isto é, as observações passadas são removidas em detrimentos das novas.
As janelas deslizantes são muito úteis para quando desejamos avaliar o modelo e para obter os coeficientes estimados conforme o tempo, de acordo com os dados históricos de determinado período.
_____________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas

