Alguns modelos preditivos costumam apresentar alta variância, outros alto viés. Nenhum destes extremos é desejável se o objetivo é maximizar a acurácia do modelo. Felizmente, ainda podemos utilizar modelos assim para tarefas preditivas, se conciliarmos com técnicas adicionais adequadas.
Neste artigo exploramos as técnicas de Bootstrapping, Bagging, Boosting e Random Forests com o objetivo de aumentar o desempenho em modelos preditivos. Percorremos o modo de funcionamento de cada técnica e sua aplicação usando linguagem de programação com dados econômicos do Brasil.
Para aprender mais e ter acesso a códigos confira o curso de Modelagem e Previsão usando Python ou comece do zero em análise de dados com a formação Do Zero à Análise de Dados com Python.
Bootstrapping
O que é?
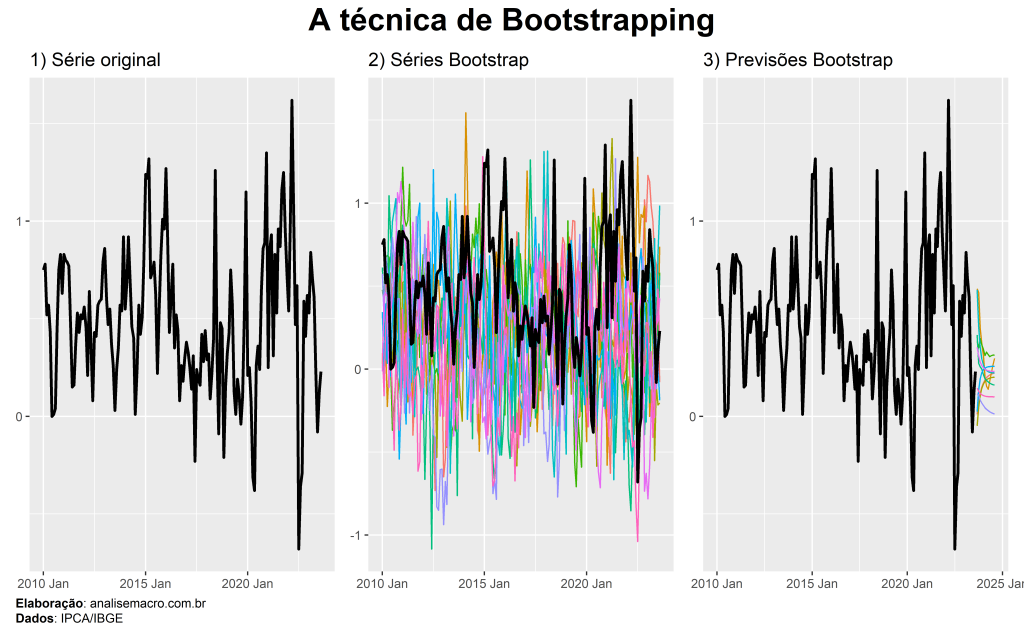
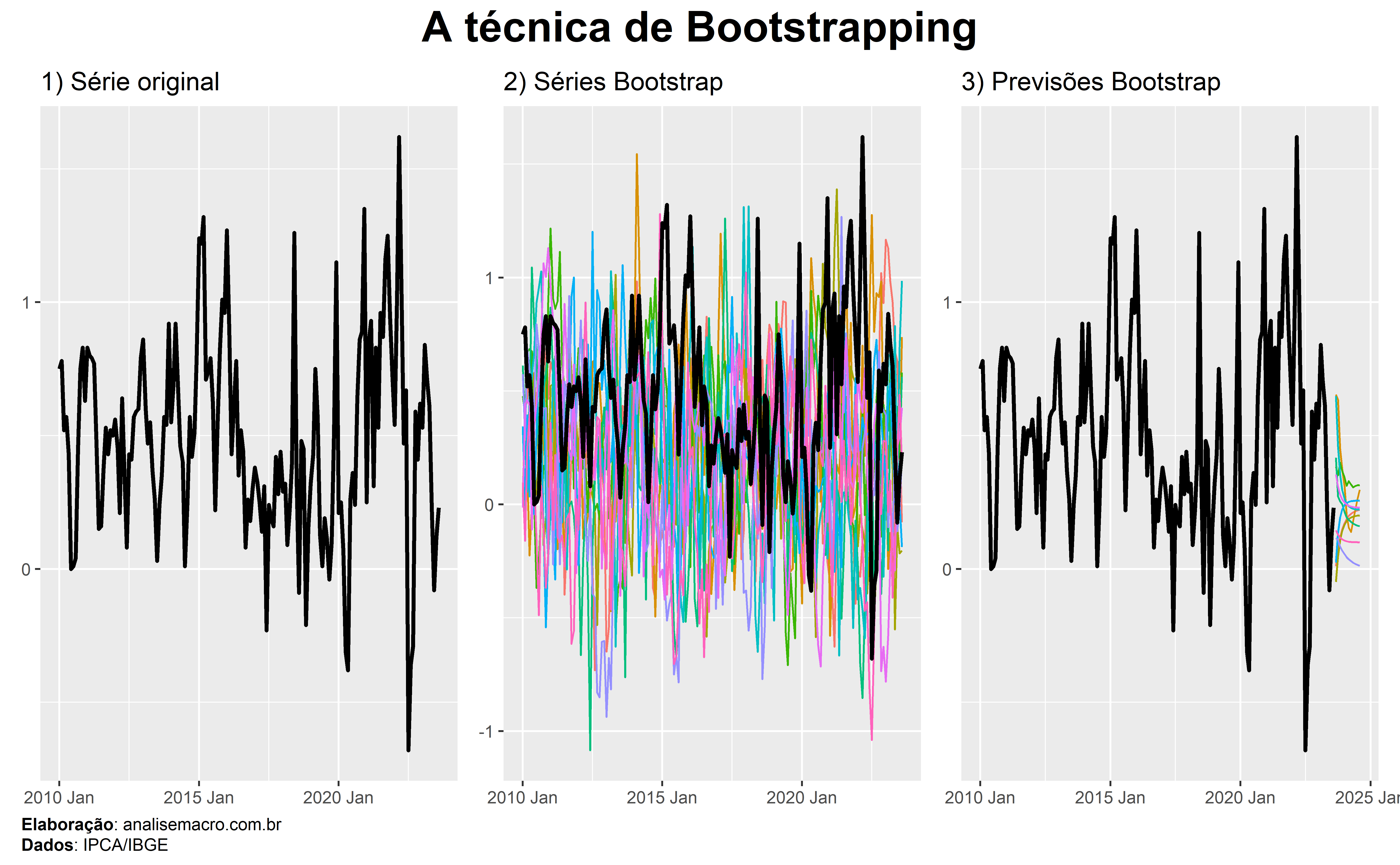
Bootstrapping é uma técnica estatística que permite gerar quase qualquer estatística ou estimador de interesse ao empregar a amostragem aleatória com reposição em dados observados.
Intuição
A ideia desta técnica é simular múltiplos conjuntos de dados similares aos dados observados ao extrair amostras do mesmo. Cada conjunto de dados é criado ao selecionar aleatoriamente observações dos dados observados originais, com a possibilidade de que a mesma observação seja selecionada várias vezes ou nunca seja selecionada.
Vantagens
As principais vantagens da técnica de bootstrapping são:
- Simplicidade de uso e implementação;
- Pode ser usada para obter quase qualquer estatística ou estimador;
- É mais acurada para obter intervalos de confiança do que o uso da variância amostral ou suposições de normalidade.
Exemplo
A disponibilidade limitada de dados históricos é um exemplo interessante de aplicação da técnica bootstrapping. Tome como exemplo a nova série temporal do CAGED, um sistema de estatísticas do Ministério do Trabalho do Brasil que sofreu “rupturas” em 2020. Suponha que seja de interesse produzir previsões para esta série temporal curta.
A técnica de bootstrapping poderia ser utilizada para gerar múltiplos conjuntos de dados, usando amostragem aleatória com reposição, a partir dos dados históricos disponíveis. Este processo permite gerar vários cenários possíveis que refletem os padrões observados nos dados históricos, além de possibilitar a estimativa de pontos e intervalos de previsão.
Bagging
O que é?
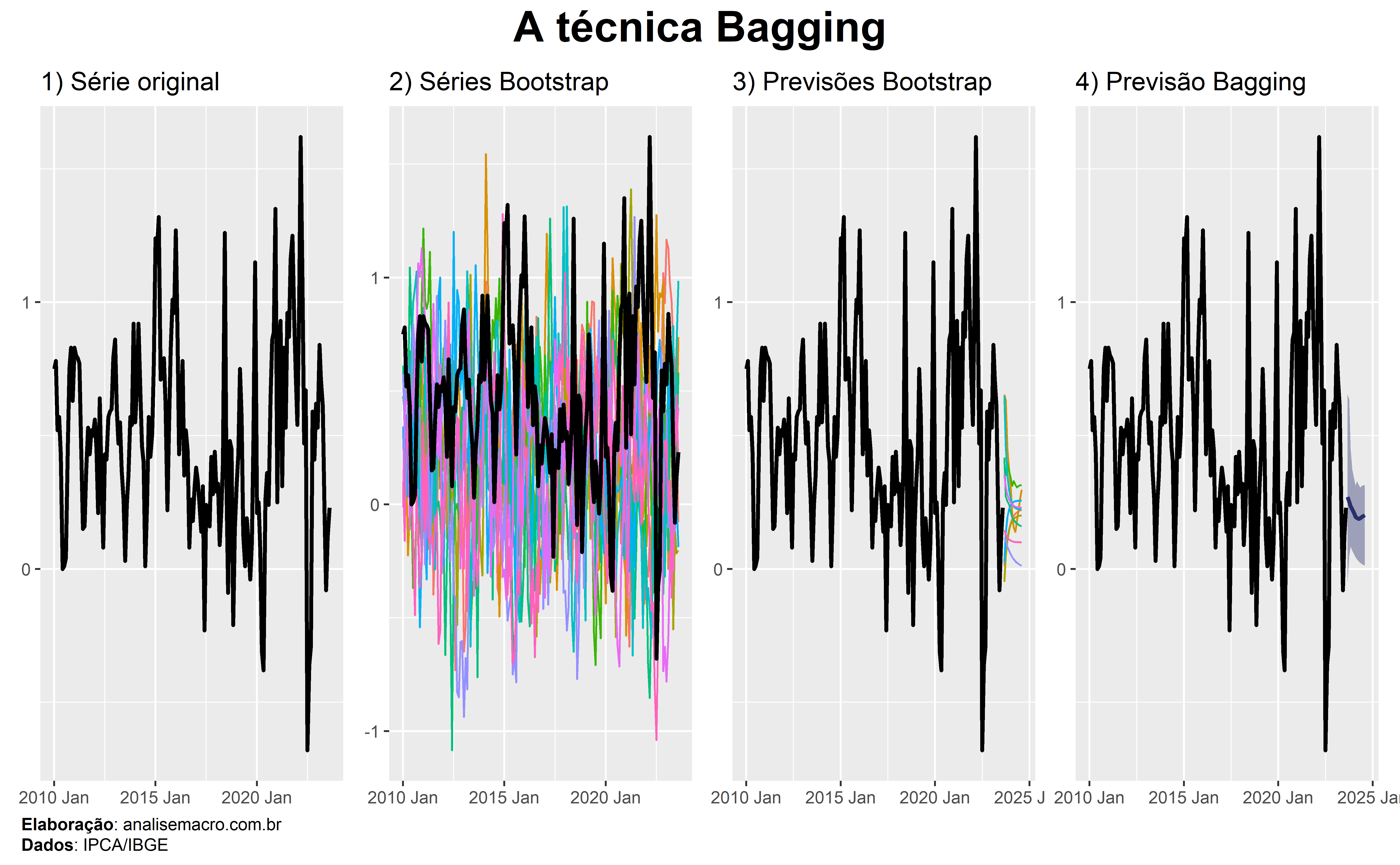
Bootstrap aggregating, também chamada de bagging, é uma técnica de combinação de previsões de múltiplos modelos estimados a partir de amostras de bootstrapping.
Intuição
A ideia desta técnica é utilizar modelos estimados em múltiplas amostras de bootstrapping para produzir múltiplas previsões e, então, agregar estas previsões, geralmente usando uma média. Ao fazer isso, introduzimos diversidade de dados nos modelos ao estimar os mesmos em diferentes amostras de dados. Isto tende a produzir previsões mais acuradas e robustas em relação a modelos individuais.
Vantagens
As principais vantagens da técnica bagging são:
- Costuma performar melhor do que modelos individuais;
- Reduz o sobreajuste e a variância do modelo;
- Pode ser executado usando computação paralela.
Exemplo
A disponibilidade limitada de dados históricos é um exemplo interessante de aplicação da técnica bagging. Tome como exemplo a nova série temporal do CAGED, um sistema de estatísticas do Ministério do Trabalho do Brasil que sofreu “rupturas” em 2020. Suponha que seja de interesse produzir previsões para esta série temporal curta.
A técnica bagging poderia ser utilizada para gerar múltiplos conjuntos de dados, usando amostragem aleatória com reposição, a partir dos dados históricos disponíveis. Este processo permite gerar vários cenários possíveis que refletem os padrões observados nos dados históricos e, no final, calcular uma previsão pontual, assim como intervalos de confiança.
Boosting
O que é?
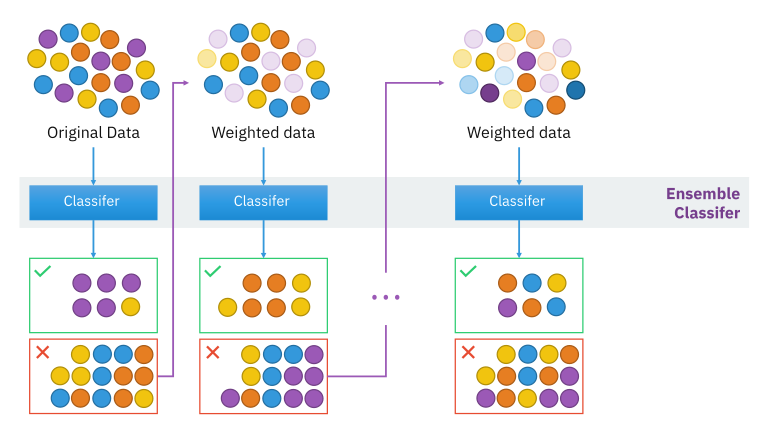
Boosting é uma técnica para melhorar a acurácia de modelos preditivos ao sequencialmente combinar modelos fracos (tipicamente modelos simples) para formar um modelo forte.
Intuição
A ideia da técnica boosting é treinar modelos preditivos sequencialmente, onde cada novo modelo tenta corrigir os erros do modelo anterior. Erros são corrigidos com a atribuição de pesos maiores, fazendo com que os modelos subsequentes errem menos. Ao final os modelos são combinados, usualmente através de média.
Vantagens
As principais vantagens da técnica boosting são:
- Costuma performar melhor do que modelos individuais;
- Reduz o viés e a variância do modelo;
- Lida com relações complexas nos dados.
Exemplo
O relacionamento complexo entre variáveis é uma aplicação interessante da técnica boosting. Tome como exemplo o problema de previsão do PIB do Brasil. Diversos fatores podem afetar esta variável, como taxas de juros, inflação, desemprego, gastos do governo e outros.
A técnica bagging poderia ser utilizada para prever o PIB trimestral, estimando um modelo com o conjunto de dados e sequencialmente corrigindo os erros ao modelar os mesmos na próxima iteração. Este processo permite agregar vários modelos fracos em um modelo forte e mais acurado.
Random Forests
O que é?
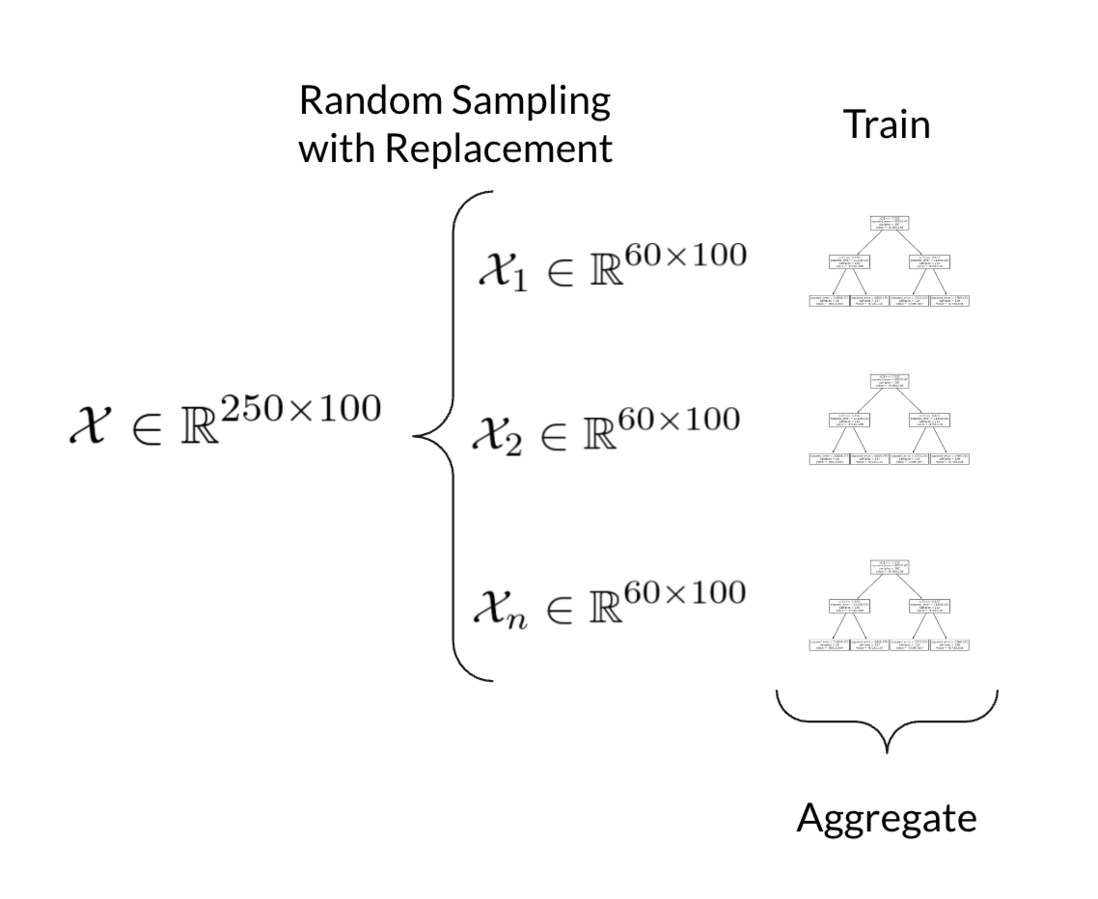
Florestas aleatórias (do inglês random forests) é um método de aprendizado de máquina para tarefas de classificação, regressão e outras que constrói uma infinidade de árvores de decisão no momento do treinamento do modelo preditivo. Para tarefas de classificação, a saída da floresta aleatória é a categoria selecionada pela maioria das árvores. Para tarefas de regressão, a média ou previsão média das árvores individuais é retornada.
Intuição
Florestas aleatórias é uma forma de equilibrar múltiplas árvores de decisão profundas, que individualmente tendem a sobreajuste. Dados um conjunto de dados, múltiplas amostras são extraídas usando amostragem aleatórias com reposição e árvores de decisão são treinadas em cada amostra. Durante o treinamento, um conjunto aleatório de variáveis é selecionado em cada nó da árvore. Depois do treinamento, previsões podem ser geradas ao calcular a média das previsões individuais das árvores. Ao introduzir aleatoriedade nas amostras de dados e nas variáveis consideradas, tende-se a obter melhores resultados de acurácia.
Vantagens
As principais vantagens do método Random Forests são:
- Costuma ser mais acurado do que árvores de decisão individuais;
- Reduz a variância do modelo;
- É menos sensível a ruídos nos dados.
Exemplo
O relacionamento complexo entre variáveis é uma aplicação interessante do método Random Forests. Tome como exemplo o problema de previsão do PIB do Brasil. Diversos fatores podem afetar esta variável, como taxas de juros, inflação, desemprego, gastos do governo e outros.
O método Random Forests poderia ser utilizado para prever o PIB trimestral, separando amostras dos dados e treinando árvores de decisão individuais. Ao final deste processo, é possível obter previsões possivelmente mais acuradas combinando as previsões individuais.
Conclusão
Neste artigo exploramos as técnicas de Bootstrapping, Bagging, Boosting e Random Forests com o objetivo de aumentar o desempenho em modelos preditivos. Percorremos o modo de funcionamento de cada técnica e sua aplicação usando linguagem de programação com dados econômicos do Brasil.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
G. James, D. Witten, T. Hastie, and R. Tibshirani. An Introduction to Statistical Learning with applications in R. Springer, 2017.
R. Hyndman and G. Athanasopoulos. Forecasting principles and practice. 1rd edition. OTexts, 2019.

