Trabalhar com dados e aplicar todo o ciclo de análise em uma única ferramenta, como a linguagem R, é ótimo e poupa tempo. No entanto, há situações em que é necessário recorrer a outras ferramentas para executar etapas específicas, como no caso de processar um volume de dados maior do que a memória. Para a felicidade dos usuários de R, mesmo nestas situações desafiantes, é possível utilizar pacotes que integram SQL com a linguagem R, permitindo escrever e executar comandos de SQL sem precisar trocar de tela!
Neste artigo, traduzimos 5 tarefas rotineiras de quem trabalha com dados, de R para SQL. O objetivo é mostrar que a sintaxe do código é parecida entre as linguagens e que é possível utilizar apenas uma interface que integra ambas as ferramentas. Mostramos exemplos com dados econômicos do Brasil.
Aprenda mais sobre SQL com o curso de SQL para Economia e Finanças da Análise Macro.
Dados de exemplo
Para exemplificar as 5 tarefas rotineitas de análise de dados em R e SQL, utilizaremos os dados desagregados do IPCA divulgados pelo IBGE em seu site. Abaixo uma amostra das tabelas, das quais criamos um banco de dados SQL para os exemplos:
Para obter o código deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Tabela de variação mensal do IPCA:
# A tibble: 6 × 18
Item RJ POA BH REC SP DF BEL FOR SAL CUR GOI VIT
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ÍNDIC… 0.33 0.56 0.71 0.88 0.62 0.5 1.05 0.61 0.39 0.75 0.55 0.65
2 ALIME… 0.49 -0.46 1.25 0.72 0.77 0.41 0.61 0.75 0.84 0.47 1.21 0.77
3 ALIME… 0.34 -0.73 1.27 0.86 0.97 0.86 0.71 0.91 0.65 0.58 1.34 0.7
4 CEREA… 4.79 3.19 5.43 3.86 5.04 2.39 2.33 5.05 3.72 3.97 5.32 6.94
5 ARROZ 4.07 3.43 4.08 3.06 4.09 2.75 1.5 5.58 1.43 4.29 3.63 6.1
6 FEIJÃ… NA NA NA 5.38 NA NA NA NA 6.23 NA NA NA
# ℹ 5 more variables: CG <dbl>, RB <dbl>, SL <dbl>, AJU <dbl>, NACIONAL <dbl>
Tabela de peso mensal do IPCA:
# A tibble: 6 × 18
Item RJ POA BH REC SP DF BEL FOR SAL
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ÍNDICE… 100 100 100 100 100 100 100 100 100
2 ALIMEN… 21.0 22.4 22.8 24.4 20.5 17.5 28.0 24.8 23.4
3 ALIMEN… 15.3 16.6 17.0 18.0 14.4 11.0 22.6 19.1 17.7
4 CEREAI… 0.892 0.593 0.905 0.894 0.721 0.511 0.983 1.57 0.859
5 ARROZ 0.61 0.406 0.672 0.450 0.522 0.327 0.685 1.13 0.538
6 FEIJÃO… NA NA NA 0.115 NA NA NA NA 0.114
# ℹ 8 more variables: CUR <dbl>, GOI <dbl>, VIT <dbl>, CG <dbl>, RB <dbl>,
# SL <dbl>, AJU <dbl>, NACIONAL <dbl>Exemplo 1: selecionando colunas de uma tabela
O primeiro exemplo consiste em selecionar as colunas “Item”, “RJ” e “SP” da tabela de variação mensal do IPCA. O procedimento é bem simples em ambas as linguagens e abaixo exibimos as primeiras 6 linhas do resultado das operações:
# A tibble: 6 × 3
Item RJ SP
<chr> <dbl> <dbl>
1 ÍNDICE GERAL 0.33 0.62
2 ALIMENTAÇÃO E BEBIDAS 0.49 0.77
3 ALIMENTAÇÃO NO DOMICÍLIO 0.34 0.97
4 CEREAIS, LEGUMINOSAS E OLEAGINOSAS 4.79 5.04
5 ARROZ 4.07 4.09
6 FEIJÃO-MULATINHO NA NA Exemplo 2: filtrando linhas de uma tabela
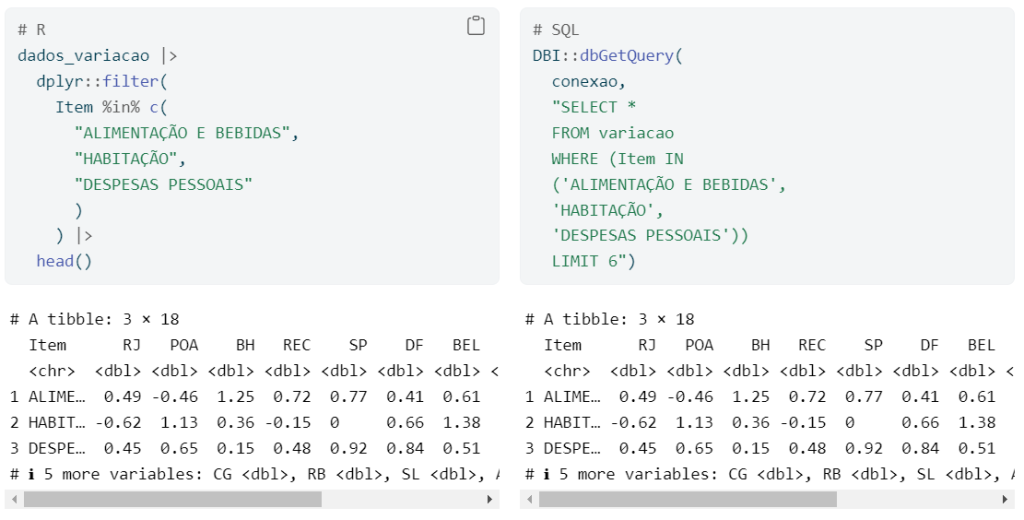
No segundo exemplo, filtramos as linhas que possuam as observações “ALIMENTAÇÃO E BEBIDAS”, “HABITAÇÃO” ou “DESPESAS PESSOAIS” na coluna “Item” da tabela de variação mensal do IPCA. Abaixo exibimos as primeiras 6 linhas do resultado das operações:
# A tibble: 3 × 18
Item RJ POA BH REC SP DF BEL FOR SAL CUR GOI VIT
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ALIME… 0.49 -0.46 1.25 0.72 0.77 0.41 0.61 0.75 0.84 0.47 1.21 0.77
2 HABIT… -0.62 1.13 0.36 -0.15 0 0.66 1.38 0.55 0.07 0.23 1.01 0.12
3 DESPE… 0.45 0.65 0.15 0.48 0.92 0.84 0.51 0.23 0.66 0.18 0.27 0.61
# ℹ 5 more variables: CG <dbl>, RB <dbl>, SL <dbl>, AJU <dbl>, NACIONAL <dbl>Exemplo 3: ordenando valores de uma coluna da tabela
No terceiro exemplo, ordenamos decrescentemente a tabela de variação mensal do IPCA com base na coluna numérica “NACIONAL”. Abaixo exibimos as primeiras 6 linhas do resultado das operações:
# A tibble: 6 × 18
Item RJ POA BH REC SP DF BEL FOR SAL CUR GOI VIT
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 LARAN… NA 21.2 NA NA NA NA NA NA NA NA NA NA
2 PEIXE… NA NA NA NA NA 1.27 18.9 NA NA NA NA NA
3 TOMATE 6.94 -0.72 20.3 16.6 14.7 23.6 10.2 31.4 8.22 21.8 16.8 16.9
4 BANAN… NA NA NA NA NA NA NA NA NA NA 14.3 NA
5 TRANS… 2.19 33.9 13.8 3.09 11.1 5.54 NA 2.74 -0.48 NA 12.0 13.9
6 COENT… NA NA NA 10.4 NA NA NA NA 6.36 NA NA NA
# ℹ 5 more variables: CG <dbl>, RB <dbl>, SL <dbl>, AJU <dbl>, NACIONAL <dbl>Exemplo 4: sumarizando dados de uma tabela
No quarto exemplo, calculamos a média da coluna “NACIONAL”. Abaixo exibimos o resultado das operações:
# A tibble: 1 × 1
media
<dbl>
1 0.771Exemplo 5: cruzando dados de duas tabelas
Por fim, no quinto exemplo, fazemos um cruzamento do tipo inner join com as tabelas de variação e peso mensal do IPCA, selecionando a coluna “Item” e as colunas de variação e peso nacional de cada tabela, além de filtrar o “Item” correspondente à “ÍNDICE GERAL”. Abaixo exibimos o resultado das operações:
# A tibble: 1 × 3
Item Variacao Peso
<chr> <dbl> <dbl>
1 ÍNDICE GERAL 0.62 100Conclusão
Neste artigo, traduzimos 5 tarefas rotineiras de quem trabalha com dados, de R para SQL. O objetivo é mostrar que a sintaxe do código é parecida entre as linguagens e que é possível utilizar apenas uma interface que integra ambas as ferramentas. Mostramos exemplos com dados econômicos do Brasil.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

