A necessidade de criar dashboards para sumarizar e apresentar dados e análises é rotineira para quem trabalha na área de dados. Também é frequente o uso de ferramentas simples do tipo point & click, como Excel, para produzir dashboards. Algo mais frequente ainda são problemas de reprodutibilidade e automatização que acabam acontecendo com o uso de tais ferramentas.
Neste texto mostramos uma alternativa interessante para usuários de Python. Imagine criar sua dashboard, analisar e apresentar os dados com código de Python usando apenas uma interface, sem copia e cola, sem fórmulas em células aleatórias e sem quebra galhos? A biblioteca Shiny proporciona exatamente isso, permitindo que o usuário desenvolva sua dashboard com códigos simples e com flexibilidade de opções de recursos.
A seguir demonstramos o fluxo de trabalho de usar o Python + Shiny para produzir uma dashboard de exemplo com dados econômicos. Para saber mais veja o curso de Produção de Dashboards Automáticos usando Python.
Passo 01: ambiente de programação
Para este exercício utilizamos o ambiente GitHub Codespaces, que é gratuito para usuários da plataforma (basta cadastrar uma conta, também gratuita). Para acessar este ambiente, primeiro navegue até https://github.com/new e preencha conforme abaixo, mudando o que achar relevante:

- Clique em “Create repository” e aguarde a página carregar
- Clique em Code
- Clique em Codespaces
- Clique em Create codespace on main
Aguarde a tela do ambiente de programação carregar (VS Code + Python).
Passo 02: dados de exemplo
Uma vez que o ambiente de programação esteja preparado, vamos prosseguir com a preparação dos dados a serem utilizados na dashboard. Aqui vamos usar dados de inflação brasileira, disponíveis no Banco Central do Brasil. Comece criando um arquivo de script Python na raiz do respositório para coletar, tratar e salvar os dados:
- Clique em Explorer
- Clique em New File…
- Digite etl.py e pressione Enter
No arquivo Python escreva o seu código de preparação de dados (instalando bibliotecas conforme a necessidade), tal como:

Finalize executando o script (Shift + Enter se a extensão Python estiver instalada), que deve salvar um arquivo “dados.csv” com as séries temporais de inflação na raiz do diretório.
Passo 03: biblioteca Shiny
Para começar a criar a dashboard, prossiga instalando e configurando a biblioteca shiny, seguindo a documentação vigente:
- Rode o comando
pip install shinyno Terminal bash (Ctrl + ’ para habilitar o Terminal) - Crie uma pasta .vscode na raiz do diretório
- Crie um arquivo settings.json na pasta criada
- Armazene o conteúdo abaixo no arquivo

- Clique em Extensions no VS Code
- Digite Shiny
- Clique em Install na extensão Shiny for Python
Passo 04: interface visual
Para começar a criar a dashboard, vamos definir a interface visual do usuário. Esta interface conterá um título no topo, uma bara lateral de botões na esquerda e uma painel principal de visualizações de dados na direita. Os botões que criamos são um de seleção de variável e outro de filtro de período. Com o Shiny, definimos tudo isso conforme abaixo:
- Clique em Explorer
- Clique em New File…
- Digite app.py e pressione Enter
- Digite o código da interface visual, conforme abaixo

Instale todas as bibliotecas que utilizar no código.
Passo 05: lógica de servidor
Para tornar a dashboard utilizável, é necessário inserir visualizações de dados (preferencialmente interativas). No nosso exemplo, vamos criar um gráfico de linha e um de histograma para exibir a variável que o usuário selecionou no botão da interface visual, aplicando o filtro temporal conforme a seleção do usuário no botão. Isso é feito no Shiny através do código de lógica do servidor, conforme abaixo:

Passo 06: visualizar a dashboard
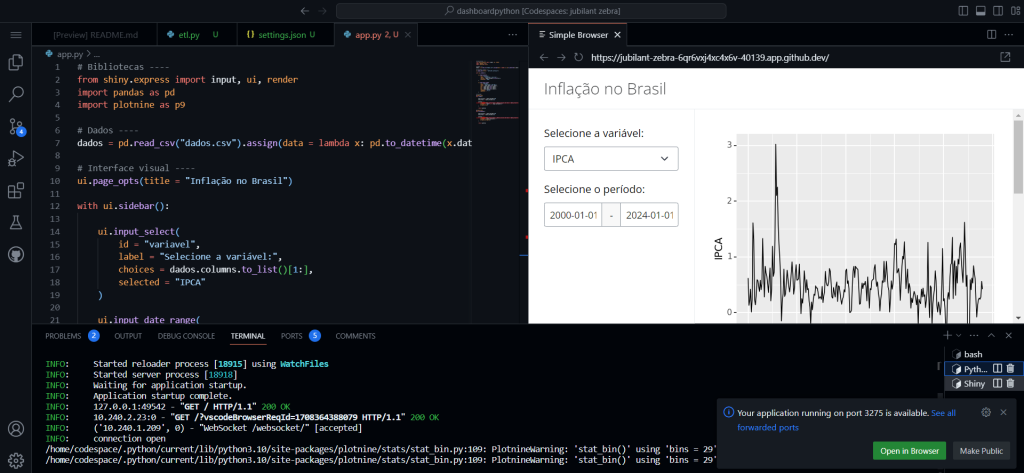
Para verificar visualmente o resultado do código da dashboard, basta clicar no botão superior direito “Run Shiny App”. A pré-visualização será exibida em um painel na tela ou pode ser aberta em uma nova aba no navegador, conforme abaixo:

Com esta dashboard de exemplo, você pode usar a documentação do Shiny para se aprofundar e aperfeiçoar o que achar necessário.
Esta dashboard é bem simples e básica, serve apenas para demonstrar o fluxo de trabalho com o Python + Shiny. Dá para criar dashboards mais completas, complexas e personalizadas. Para saber mais veja o curso de Produção de Dashboards Automáticos usando Python.
Conclusão
Neste exercício mostramos do zero como criar dashboards de análise de dados econômicos usando Python + Shiny. A vantagem destas ferramentas gratuitas é a facilidade de automatização e os ricos recursos disponíveis.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

