Durante a segunda semana de janeiro deste ano, aproveitando minhas férias, dei um curso introdutório de R com aplicação a séries de tempo na Faculdade de Economia da UFF. A ideia do curso foi basicamente introduzir o aluno ao mundo do R, porém com uma aplicação prática, fugindo um pouco daquele esquema de ficar tentando memorizar todas as funções e pra que servem. Por isso, durante cinco dias sentamos na frente de um computador e escrevemos scripts ao mesmo tempo que olhávamos os dados reais e exemplos concretos.
O andamento do curso foi bem mais rápido do que eu tinha antecipado, principalmente dada a resposta por parte dos alunos. Assim, não consegui me programar muito bem e, no último dia de aula, fiquei devendo um exercício. Consequentemente, resolvi escrever este post para tentar me redimir.
O exercício consistia em fazer N previsões de um passo a frente. Assim, o aluno deveria criar um loop que seguisse os seguintes passos:
- Estima um modelo;
- Faz a previsão de um passo a frente para este modelo;
- Salva a previsão;
- Acrescenta uma observação a amostra inicial;
- Repete 1-4 até incluir todos os dados da amostra.
O intuito desse exercício era justamente utilizar uma das características mais importantes do R, o poder de reproduzir e automatizar processos (de maneira razoavelmente lógica).
Neste exercício vou utilizar a série mensal de variação percentual do IPCA (a partir de janeiro de 2004) e o pacote forecast. Além disso vou assumir que o IPCA segue o seguinte processo:
![\[ IPCA_t = \alpha + \rho IPCA_{t-1} + \gamma \varepsilon_{t-1} + \varepsilon_t \]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-8768ace53563050f32f54fdfdfb53837_l3.png "Rendered by QuickLaTeX.com")
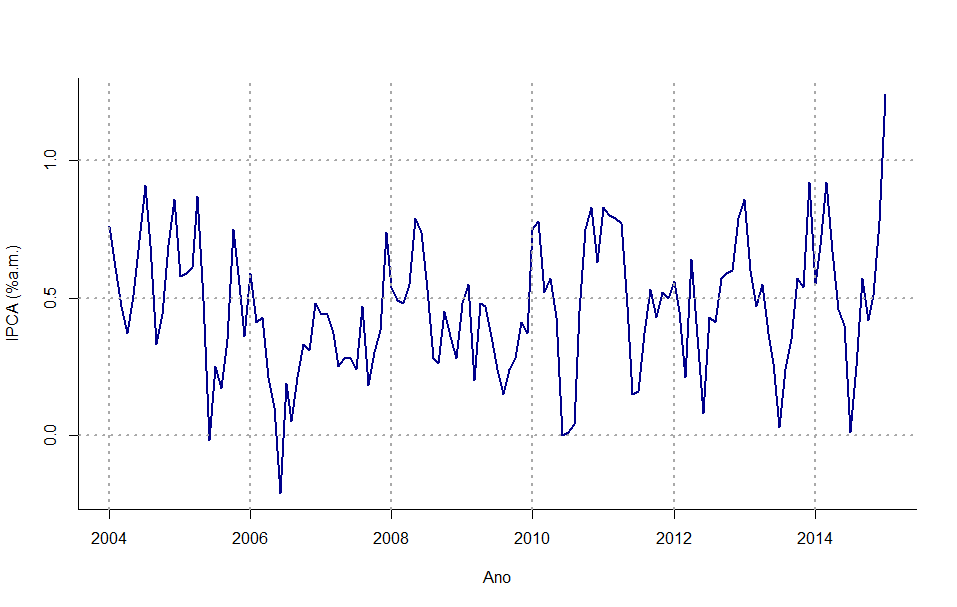
Portanto, o modelo que vou estimar é um ARMA(1,1). O gráfico da série e o código que usei para faze-lo estão a seguir.
plot(ipca,
ylab = 'IPCA (%a.m.)', xlab = 'Ano',
col = 'darkblue', lwd=2,
bty='l')
grid(col='darkgrey', lwd=2)
Em seguida, escolhi primeiro o quanto da amostra total eu iria utilizar para a primeira estimação. O valor inicial escolhido foi 20%. Assim sendo, como pode ser visto no código abaixo, tive que definir, a partir desta informação, aonde no vetor de observações que eu iria começar a estimação. Eu aproveito também para já calcular o o número de previsões que serão feitas (dado por comp.prev), informação está que servirá como input quando formos pré-alocar a matriz de previsões. Notem que, dado que uma certa porcentagem possa gerar números não inteiros, eu utilizo a função round para arredondar para um número inteiro.
p <- 20 inicio <- round((p/100)*length(ipca),0) comp.prev <- length(ipca[(inicio):length(ipca)])
Antes de começar efetivamente a pensar no loop vou pré-alocar uma matriz que receberá não só a previsão mas também os valores da previsão que representam um intervalo de confiança de 95%. Note que esta matriz deve ter o mesmo número de linhas (nrow) que o número de previsões (ou o tamanho da amostra retirados os 20%).
prev <- matrix(NA, ncol=3, nrow=comp.prev)
Agora, finalmente, podemos criar o loop que irá reproduzir os 5 passos dados acima. Eu começo estimando o modelo e depois extraindo as informações do objeto previsao.
for (i in 1:comp.prev){
previsao <- forecast(Arima(ipca[1:(inicio+i-1)],
order = c(1,0,1)), level=95, h=1)
prev[i,1] <- previsao$mean
prev[i,2] <- previsao$lower
prev[i,3] <- previsao$upper
}
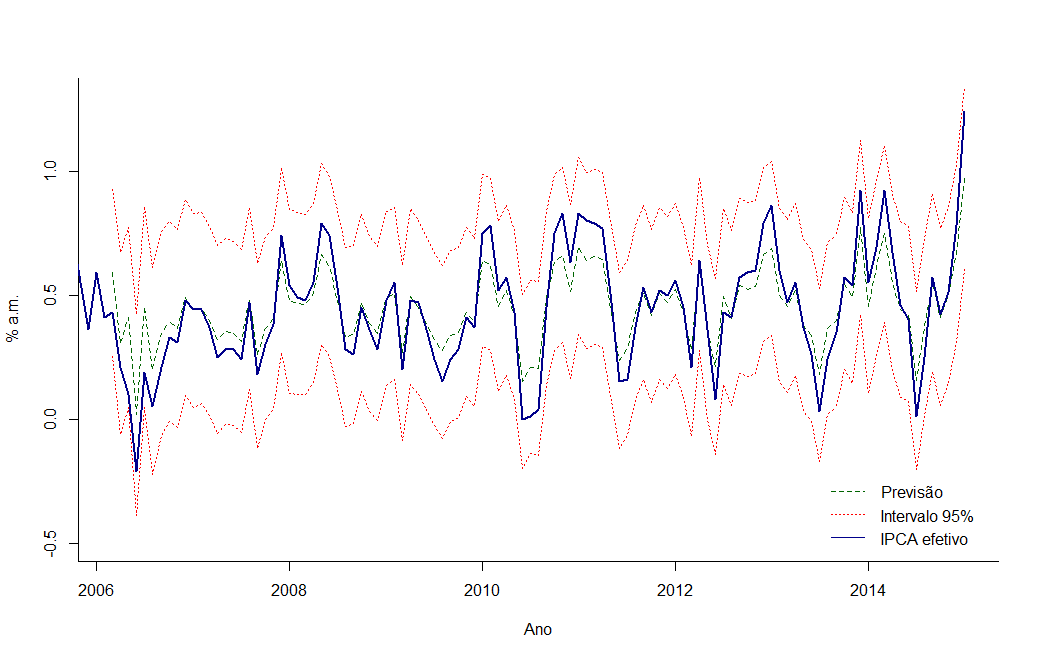
Finalmente podemos fazer um gráfico com a N previsões de um passo a frente, incluindo seu intervalo de confiança e o IPCA efetivo.
plot(prev[,1],
ylab = '% a.m.', xlab = 'Ano',
col = 'darkgreen', lwd=1,lty=2,
ylim=c(-0.5,1),
bty='l')
lines(prev[,2],
col='red',
lty=3)
lines(prev[,3],
col='red',
lty=3)
lines(ipca,
col='darkblue',
lwd=2)
legend('bottomright',
c('Previsão','Intervalo 95%','IPCA efetivo'),
lty=c(2,3,1),
col=c('darkgreen','red','darkblue'),
bty='n')