Colocar modelos em produção pode ser um grande desafio. Lidar com custos monetários, infraestrutura operacional e complexidades de códigos e ferramentas pode acabar matando potenciais projetos.
Uma solução que elimina todos estes obstáculos é a recém lançada Shinylive. Esta ferramenta permite transformar um app Shiny em uma estrutura compacta de arquivos que pode ser hospedada com se fosse um site estático, mas com a possibilidade de rodar códigos de Python no próprio navegador. Em outras palavras, é possível colocar um modelo em produção sem a necessidade de um servidor (computador) por trás.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados com Python.
As vantagens de utilizar o Shinylive para deploy de modelos são:
- Custo monetário igual a zero
- Simples e rápido de utilizar
- Permite rodar Python no navegador
- Elimina necessidade de configurar servidores
Dessa forma, basta ter um app Shiny funcional com um modelo de previsão embutido. A parte chata, burocrática e complicada de colocar este modelo em produção fica sob responsabilidade do Shinylive, que converte o app em uma estrutura de arquivos “deployable”, restando apenas hospedá-los em algum local (como o GitHub Pages).
Algumas desvantagens de utilizar o Shinylive para de deploy de modelos são:
- Não há gerenciamento nativo de logs e registros de execução da aplicação
- Tempo de inicialização da aplicação costuma ser demorado
- Realizar requisições de APIs externas na aplicação não é tão simples
Dito isso, vamos exemplificar como colocar um modelo de previsão para o preço do petróleo Brent em produção. Utilizaremos o Python para desenvolver o modelo, o Shiny para criar uma interface interativa com parâmetros do modelo, o Shinylive para fazer o deploy e o GitHub Pages para hospedar os arquivos e gerar um link de acesso.
Passo 01: Shiny App com modelo de exemplo
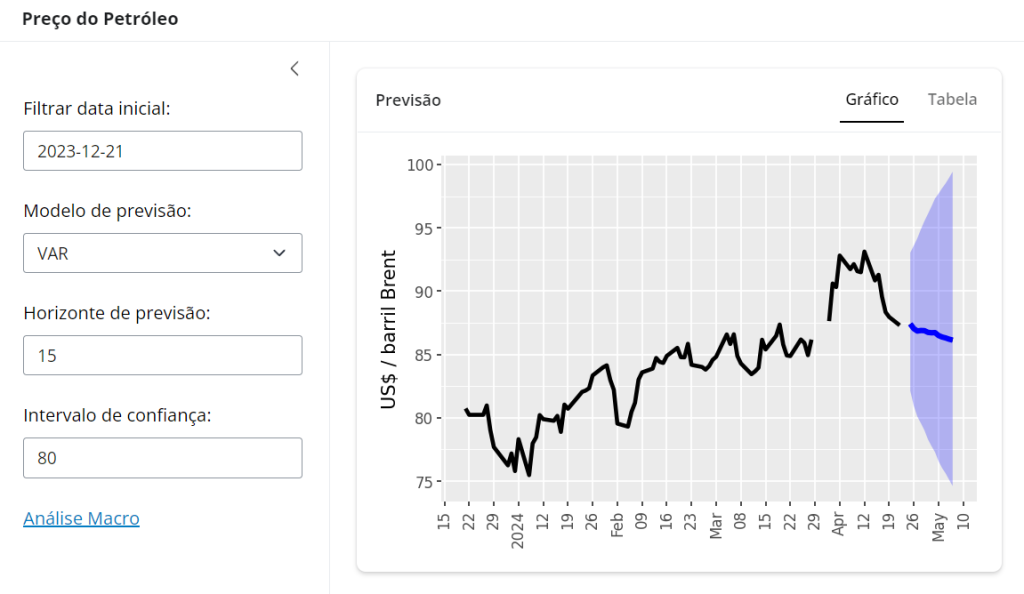
Crie um modelo de previsão e coloque o mesmo em um app Shiny, como abaixo:
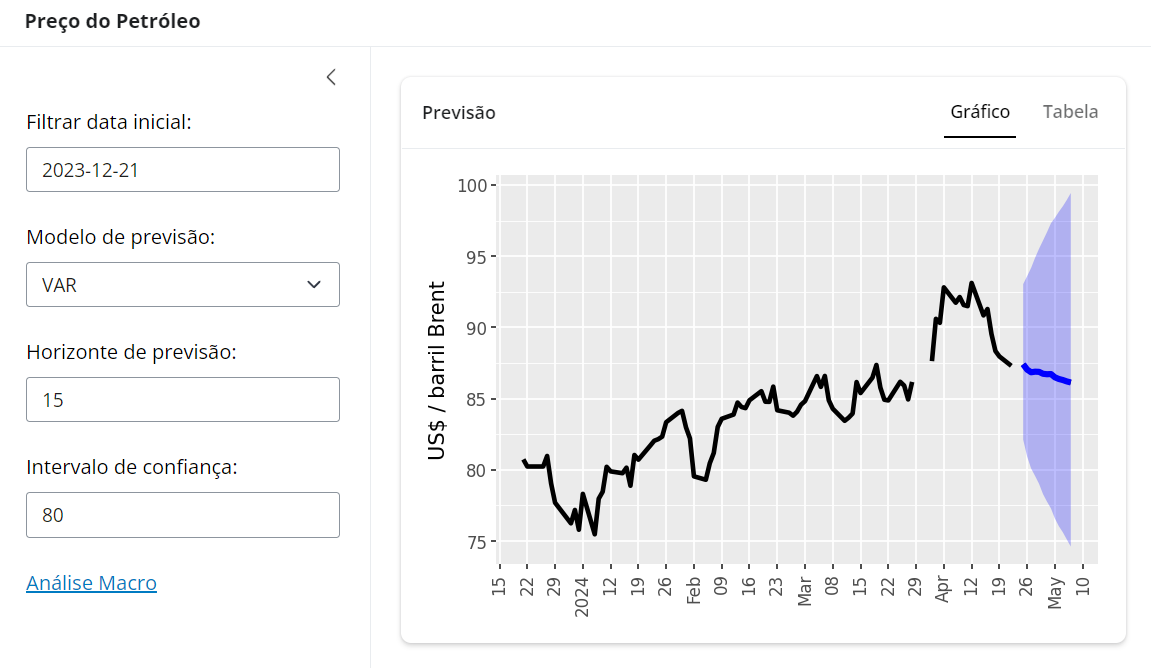
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas. app.py
# Bibliotecas
from shiny import reactive
from shiny.express import input, render, ui
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
import statsmodels.api as sm
from statsmodels.tsa.api import VAR
import plotnine as p9
from pathlib import Path
# Dados
# url_base = "http://www.ipeadata.gov.br/api/odata4/ValoresSerie(SERCODIGO="
# url_p = f"{url_base}'EIA366_PBRENT366')"
# url_c = f"{url_base}'GM366_EREURO366')"
#
# dados_petroleo = pd.DataFrame.from_records(pd.read_json(url_p).value.values)
# dados_cambio = pd.DataFrame.from_records(pd.read_json(url_c).value.values)
#
# petroleo = pd.DataFrame(
# data = {"brent": dados_petroleo.VALVALOR.astype(float).apply(np.log).values},
# index = pd.to_datetime(dados_petroleo.VALDATA, utc = True).rename("data")
# )
# cambio = pd.DataFrame(
# data = {"eurusd": dados_cambio.VALVALOR.astype(float).values},
# index = pd.to_datetime(dados_cambio.VALDATA, utc = True).rename("data")
# )
#
# dados = petroleo.join(cambio, how = "outer")
# dados.insert(0, "data", pd.to_datetime(dados.index.date))
# dados.to_csv("app/dados.csv", index= False)
def ler_csv():
infile = Path(__file__).parent / "dados.csv"
df_dados = pd.read_csv(
infile,
converters = {"data": lambda x: pd.to_datetime(x)}
)
return df_dados
dados = ler_csv()
dados.index = dados.data
# Inputs
ui.page_opts(title = ui.strong("Preço do Petróleo"), fillable = True)
with ui.sidebar(width = 300):
ui.input_date(
id = "periodo",
label = "Filtrar data inicial:",
value = (dados.index.max() - pd.offsets.BusinessDay(n = 90)).date(),
min = dados.index.min().date(),
max = dados.index.max().date(),
language = "pt-BR"
)
ui.input_select(
id = "modelo",
label = "Modelo de previsão:",
choices = ["Regressão linear", "SARIMAX", "VAR"],
selected = "VAR"
)
ui.input_numeric(
id = "horizonte",
label = "Horizonte de previsão:",
value = 7,
min = 1,
max = 30,
step = 1
)
ui.input_numeric(
id = "intervalo",
label = "Intervalo de confiança:",
value = 80,
min = 1,
max = 100,
step = 1
)
ui.markdown("[Análise Macro](https://analisemacro.com.br/)")
# Outputs
with ui.navset_card_underline(title = "Previsão"):
with ui.nav_panel("Gráfico"):
@render.plot
def grafico():
df_previsao = (
previsao()
.assign(
brent = lambda x: x["Previsão"],
data = lambda x: pd.to_datetime(x["Período"])
)
)
data_ini = input.periodo().strftime("%Y-%m-%d")
df_filtrado = (
dados
.query("data >= @data_ini")
.assign(brent = lambda x: np.exp(x.brent))
)
df_grafico = pd.concat([df_filtrado, df_previsao])
from datetime import date
def weekinmonth(dates):
firstday_in_month = dates - pd.to_timedelta(dates.day - 1, unit='d')
return (dates.day-1 + firstday_in_month.weekday()) // 7 + 1
def custom_date_format2(breaks):
res = []
for x in breaks:
# First day of the year
if x.month == 1 and weekinmonth(x) == 1:
fmt = "%Y"
# Every other month
elif x.month != 1 and weekinmonth(x) == 1:
fmt = "%b"
else:
fmt = "%d"
res.append(date.strftime(x, fmt))
return res
return (
p9.ggplot(df_grafico) +
p9.aes(x = "data", y = "Previsão") +
p9.geom_line(mapping = p9.aes(y = "brent"), size = 1.5) +
p9.geom_line(size = 2, color = "blue") +
p9.geom_ribbon(
mapping = p9.aes(ymin = "Intervalo Inferior", ymax = "Intervalo Superior"),
alpha = 0.25,
fill = "blue"
) +
p9.scale_x_date(
date_breaks = "1 week" if df_grafico.shape[0] < 120 else "1 month",
labels = custom_date_format2,
date_minor_breaks = "1 week"
) +
p9.theme_gray(base_size = 12) +
p9.theme(axis_text_x = p9.element_text(angle = 90)) +
p9.labs(y = "US$ / barril Brent", x = "")
)
with ui.nav_panel("Tabela"):
@render.data_frame
def tabela():
return render.DataGrid(previsao(), editable = False, width = "100%")
# Servidor
@reactive.calc
def previsao():
modelo = input.modelo()
h = input.horizonte()
ic = 1 - input.intervalo()/100
df_treino = dados.dropna(subset = "brent").query("data > '2014-01-01'")
df_ex = dados.query("data > @df_treino.data.max()")
index_cenario = pd.date_range(
start = df_ex.index.max() + pd.DateOffset(days = 1),
end = df_ex.index.max() + pd.DateOffset(days = h - df_ex.shape[0]),
freq = "D"
)
df_cenario = pd.DataFrame(
data = {
"eurusd": pd.Series(
[df_ex.eurusd.iloc[-1]] * (h - df_ex.shape[0])
).values,
"data": pd.to_datetime(index_cenario.date),
"brent": np.nan
},
index = index_cenario
)
df_previsao = pd.concat([df_ex, df_cenario])
if modelo == "Regressão linear":
mod = smf.ols(formula = "brent ~ eurusd", data = df_treino).fit()
prev = mod.get_prediction(df_previsao)
df_prev = pd.DataFrame(
data = {
"Período": pd.to_datetime(df_previsao.index.date).astype(str),
"Intervalo Inferior": np.exp(prev.conf_int(alpha = ic)[:,0]),
"Previsão": np.exp(prev.predicted),
"Intervalo Superior": np.exp(prev.conf_int(alpha = ic)[:,1]),
}
)
elif modelo == "SARIMAX":
mod = sm.tsa.statespace.SARIMAX(
endog = df_treino.dropna()["brent"],
exog = df_treino.dropna()["eurusd"],
order = (1, 0, 0),
seasonal_order = (0, 0, 1, 12),
trend = "ct"
).fit()
prev = mod.get_forecast(
steps = df_previsao.shape[0],
exog = df_previsao.eurusd
)
df_prev = pd.DataFrame(
data = {
"Período": pd.to_datetime(df_previsao.index.date).astype(str),
"Intervalo Inferior": np.exp(prev.conf_int(alpha = ic)["lower brent"]),
"Previsão": np.exp(prev.predicted_mean.values),
"Intervalo Superior": np.exp(prev.conf_int(alpha = ic)["upper brent"]),
}
)
else:
mod = VAR(df_treino.drop(labels = "data", axis = "columns").dropna()).fit(
maxlags = 15,
trend = "ct"
)
prev = mod.forecast_interval(
y = df_treino.drop(labels = "data", axis = "columns").dropna().values[-mod.k_ar:],
steps = df_previsao.shape[0],
alpha = ic
)
df_prev = pd.DataFrame(
data = {
"Período": pd.to_datetime(df_previsao.index.date).astype(str),
"Intervalo Inferior": np.exp(prev[1][:,0]),
"Previsão": np.exp(prev[0][:,0]),
"Intervalo Superior": np.exp(prev[2][:,0]),
}
)
return df_prevAlém do arquivo app.py da dashboard Shiny, ainda há o arquivo dados.csv neste projeto.
Passo 02: repositório no GitHub
- Acesse github.com
- Faça o cadastro/login se necessário
- Clique no botão “New” para criar um repositório
- Digite um nome no campo “Repository name*”
- Marque a opção “Add a README file”
- Clique no botão “Create repository”
Passo 03: ambiente de desenvolvimento
- Clique no botão “Code” no repositório GitHub criado
- Clique em “Codespaces”
- Clique em “Create codespace on main”
- Selecione os arquivos
app.pyedados.csvdo seu computador, clique e arraste os mesmos para o painel “EXPLORER” do VS Code web - Instale a versão “0.3.0.9000” ou superior do Shinylive, rodando o comando no painel “TERMINAL” (Ctrl+'Ctrl+' para exibir)
pip install git+https://github.com/posit-dev/py-shinylive.git
Passo 04: deploy com Shinylive + GitHub Pages
- Rode o comando abaixo no painel “TERMINAL”
shinylive export . docs - Clique no painel “Source Control”
- Clique no botão “+” (“Stage All Changes”) ao lado de “Changes”
- Digite uma mensagem como “Deploy do meu modelo” no campo textual acima do botão “Commit”
- Clique no botão “Commit”
- Clique no botão “Sync Changes”
- Clique no botão “OK”
- Navegue até a página inicial do repositório GitHub criado anteriormente
- Clique no botão “Settings”
- Clique no menu “Pages” na seção “Code and automation”
- Clique no botão “None” na seção “Branch”
- Clique na opção “main”
- Clique no botão “/(root)” na seção “Branch”
- Clique na opção “/docs”
- Clique no botão “Save”
Ao final de todos estes passos o modelo estará em produção (deploy) e pode ser acessado pelo link:
- https://USUARIO.github.io/REPOSITORIO/
Onde “USUARIO” é o nome de usuário da sua conta cadastrada no GitHub e REPOSITORIO é o nome do repositório criado anteriormente.
Conclusão
Colocar modelos em produção pode ser um grande desafio. Lidar com custos monetários, infraestrutura operacional e complexidades de códigos e ferramentas pode acabar matando potenciais projetos. Uma solução que elimina todos estes obstáculos é a recém lançada Shinylive. Neste artigo mostramos um exemplo com um modelo de previsão para o preço do petróleo Brent.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

