Nem sempre a melhor visualização de dados é um gráfico, seja do tipo que for. Muitas vezes quem quer analisar os dados precisa ver os números. Nestes casos, uma tabela bem formatada faz o serviço, além de ser um tipo de apresentação de dados que é mais conhecido pelo grande público.
Mas como contextualizar os dados usando Data Storytelling quando o chefe pede uma tabela e não um gráfico? Neste artigo, mostramos um caminho para criar boas análises e visualizações de dados através de tabelas personalizadas com o Python.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados Econômicos e Financeiros com Python.
Passo 01: bibliotecas
Aqui iniciamos um exemplo importando 3 bibliotecas de Python:
great_tablespara criar e personalizar tabelaspandaspara processar dados tabularespython-bcbpara coletar dados de exemplo no Banco Central
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Passo 02: coleta de dados
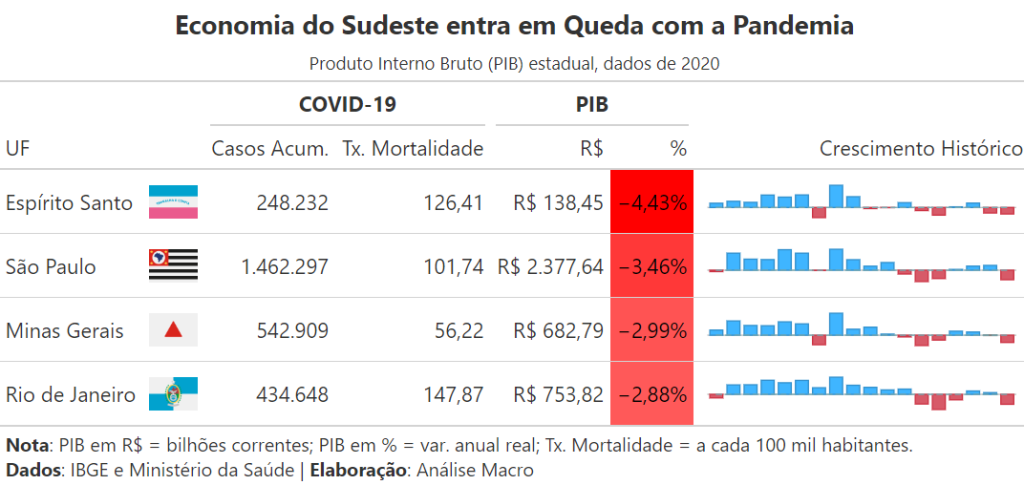
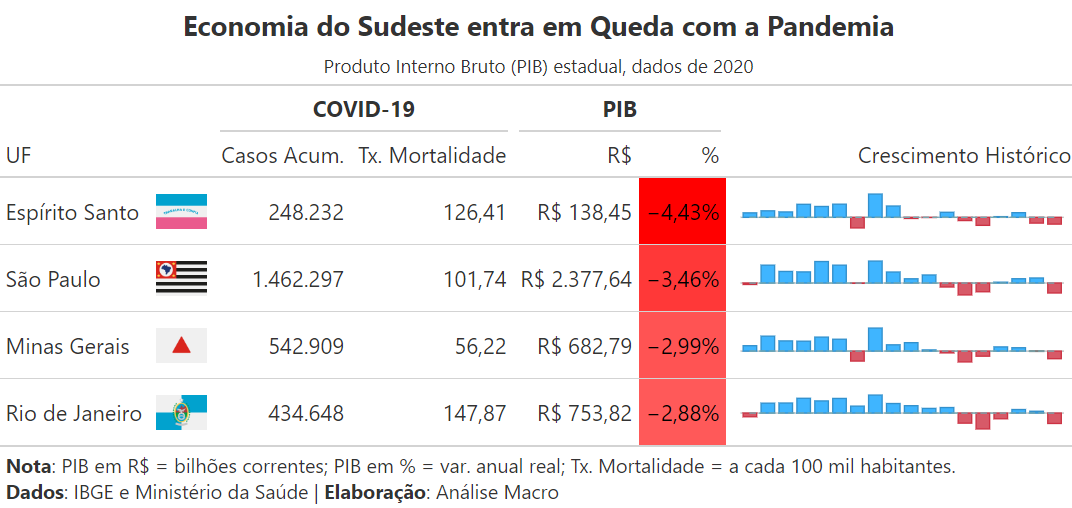
Aqui coletamos dados regionais do Produto Interno Bruto (PIB) da região Sudeste do Brasil, diretamente do Banco Central.
| % | UF | |
|---|---|---|
| Date | ||
| 2003-01-01 | 2.94 | Espírito Santo |
| 2004-01-01 | 4.27 | Espírito Santo |
| 2005-01-01 | 3.54 | Espírito Santo |
| 2006-01-01 | 8.53 | Espírito Santo |
| 2007-01-01 | 7.12 | Espírito Santo |
| ... | ... | ... |
| 2016-01-01 | -3.03 | São Paulo |
| 2017-01-01 | 0.29 | São Paulo |
| 2018-01-01 | 1.49 | São Paulo |
| 2019-01-01 | 1.75 | São Paulo |
| 2020-01-01 | -3.46 | São Paulo |
72 rows × 2 columns
Passo 03: tratamento de dados
Aqui pegamos os dados brutos que vêm do Banco Central e aplicamos uma série de tratamentos, adicionamos dados sobre a Covid-19 e ordenamos colunas e linhas para que a tabela fique pronta para ser estilizada na sequência.
| Bandeira | Casos | Mortalidade | RS | PCT | Evolucao | |
|---|---|---|---|---|---|---|
| UF | ||||||
| Espírito Santo | Espírito Santo.png | 248232 | 126.41 | 138.44592 | -4.43 | 2.94 4.27 3.54 8.53 7.12 8.62 -6.92 15.2... |
| São Paulo | São Paulo.png | 1462297 | 101.74 | 2377.63898 | -3.46 | -0.50 6.20 4.02 3.86 7.46 6.20 -0.11 7.6... |
| Minas Gerais | Minas Gerais.png | 542909 | 56.22 | 682.78612 | -2.99 | 2.13 5.89 4.02 3.91 5.52 4.68 -3.92 9.0... |
| Rio de Janeiro | Rio de Janeiro.png | 434648 | 147.87 | 753.82371 | -2.88 | -1.02 2.74 2.78 4.09 3.36 4.05 1.92 4.9... |
Passo 04: formatação da tabela
Aqui utilizamos o pacote great_table para auxiliar na contextualização dos dados. A ideia é destacar que a queda no crescimento econômico estadual está relacionada com os efeitos da pandemia da Covid-19 no período. Para ajudar nesta tarefa, utilizamos algumas das ferramentas do pacote, tais como:
fmt_*funções para formatar estilo das colunas (numéricas, percentuais, imagens, etc.)nanoplotfunção para criar mini-gráfico de evolução dos dadostab_spannerfunção para agrupar colunasdata_colorfunção para criar heatmap de valores nas colunas
Conclusão
Como contextualizar os dados com Data Storytelling quando o chefe pede uma tabela e não um gráfico? Neste artigo, mostramos um caminho para criar boas análises e visualizações de dados através de tabelas personalizadas com o Python.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

