Introdução
Neste exercício, implementamos o Nowcasting utilizando Modelos de Fatores Dinâmicos (Dynamic Factor Models) em Python, com o objetivo de prever o PIB dos EUA com base nos dados dos conjuntos FRED-MD e FRED-QD.
De forma simplificada, o nowcasting é uma técnica que permite prever o presente, ou até mesmo o futuro ou passado muito recente. A principal meta aqui é identificar um conjunto de variáveis capaz de captar a dinâmica da série de interesse, conforme ela ocorre.
No entanto, esse conjunto de variáveis pode ser bastante extenso, envolvendo dezenas, centenas ou até milhares de variáveis. Quando o número de variáveis excede o número de observações, não é possível estimar coeficientes em modelos paramétricos tradicionais, como a Regressão Linear (OLS). Mesmo que seja possível estimar esses coeficientes, incluir um grande número de variáveis no modelo pode resultar em overfitting, o que tende a gerar previsões imprecisas.
Para contornar esse problema, uma abordagem comum é o uso de modelos com fatores. Essencialmente, um fator permite reduzir o conjunto de variáveis a uma única fonte de variação comum entre elas, que geralmente é não-observável. A ideia é usar um conjunto de variáveis relacionadas a essa fonte e, ao extrair o componente comum de variação, obter uma aproximação dessa fonte não observada.
Para ilustrar, imagine que desejamos acompanhar em "tempo real" a evolução da atividade econômica. Sabemos que várias variáveis são afetadas ou afetam a atividade econômica, embora em direções e magnitudes diferentes, como a utilização de energia elétrica, a produção industrial e a confiança dos consumidores. Ao extrair o componente comum entre essas variáveis, podemos obter uma medida indireta da atividade econômica. Se tivermos essas informações disponíveis no instante t, também poderemos prever a atividade econômica em t — um Nowcast.
*O código deste exercício é baseado em Fulton (2020).*
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Quer aprender a como criar modelos de série econômicas brasileiras usando Machine Learning e IA Generativa? Veja nosso curso IA para previsão Macroeconômica usando Python.
Dynamic Factor Model
Apresentamos aqui o modelo de fator dinâmico, que pode ser encontrado na classe `DynamicFactorMQ`, que faz parte do componente de análise de séries temporais (especificamente no subcomponente de modelos de espaço de estados) da biblioteca `statsmodels`.
Modelo estatístico:
O modelo estatístico e o algoritmo EM usados para a estimativa dos parâmetros são descritos em Bańbura e Modugno (2014) e Bańbura et al. (2011).
Como nestes artigos, a especificação básica parte da "forma estática" típica do modelo de fator dinâmico:
![\[\begin{aligned} y_t & = \Lambda f_t + \epsilon_t \\ f_t & = A_1 f_{t-1} + \dots + A_p f_{t-p} + u_t \end{aligned}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-59535b287e7a0239400d514ff852ebf8_l3.png "Rendered by QuickLaTeX.com")
A classe `DynamicFactorMQ` permite as generalizações do modelo descritas nas referências acima, incluindo:
- Limitar blocos de fatores a carregar apenas em certas variáveis observadas
- Dados de frequência mista mensal e trimestral, conforme descrito por Mariano e Murasawa (2010)
- Permitir autocorrelação (via especificações AR(1)) nos distúrbios idiossincráticos 
- Entradas ausentes nas variáveis observadas 
Atenção: *O código deste exercício foi gerado utilizando o pandas na versão 1.5.3. O motivo é que a classe `DynamicFactorMQ` não foi atualizada para versões recentes do pandas, gerando erros. Há um pull request no repositório do Github para a atualização da classe, entretanto, ainda não implementada no statsmodels.*
Estimativa de parâmetros
Quando há um grande número de variáveis observadas , pode haver centenas ou até milhares de parâmetros a serem estimados. Nessa situação, pode ser extremamente difícil para os métodos típicos encontrar os parâmetros que maximizam a função de verossimilhança. Como esse modelo foi projetado para suportar um grande painel de variáveis observadas, o algoritmo EM é utilizado, pois pode ser mais robusto.
Em particular, o modelo acima está na forma de espaço de estados e, portanto, o módulo do statsmodels, statespace, pode ser usada para aplicar as rotinas do filtro de Kalman e suavização, que são necessárias para a estimativa.
Previsão e interpolação
Como o modelo está na forma de espaço de estados, uma vez que os parâmetros são estimados, é simples produzir previsões de qualquer uma das variáveis observadas .
Além disso, para quaisquer entradas ausentes nas variáveis observadas , também é simples produzir estimativas dessas entradas com base nos fatores extraídos de todo o conjunto de dados observados (estimativas "suavizadas" dos fatores). Em um modelo de frequência mista mensal/trimestral, isso pode ser usado para interpolar valores mensais para variáveis trimestrais.
Nowcasting, atualização de previsões e computação das "news"
Ao incluir tanto variáveis mensais quanto trimestrais, este modelo pode ser usado para produzir "nowcasts" de uma variável trimestral antes de sua publicação, com base nos dados mensais daquele trimestre. Por exemplo, a estimativa preliminar do PIB do primeiro trimestre (EUA) é tipicamente divulgada em abril, mas este modelo poderia produzir uma estimativa em março baseada em dados até fevereiro.
Muitos exercícios de previsão e nowcasting são atualizados frequentemente, em "tempo real", e é, portanto, importante que novos pontos de dados possam ser facilmente adicionados conforme chegam. Como esses novos pontos de dados fornecem novas informações, a previsão/nowcast do modelo mudará com novos dados, e também é importante que seja possível decompor facilmente essas mudanças em contribuições de cada série atualizada para as mudanças na previsão. Ambos os passos são suportados por todos os modelos de espaço de estados no Statsmodels – incluindo o modelo `DynamicFactorMQ` – como mostramos a seguir.
Dataset
Data vintage
Transformações de dados
Outliers
Modelo Nowcasting
Multiplicidades dos Fatores
Resumo do Modelo Nowcasting
Como esses modelos podem ser um tanto complexos para configurar, pode ser útil verificar os resultados do método `summary` do modelo. Esse método produz três tabelas.
1. Especificação do Modelo: a primeira tabela mostra informações gerais sobre o modelo selecionado, a amostra, a configuração dos fatores e outras opções.
2. Variáveis Observadas / Cargas dos Fatores: a segunda tabela mostra quais fatores carregam em quais variáveis observadas. Essa tabela deve ser verificada para garantir que os argumentos `factors` e `factor_multiplicities` foram especificados conforme desejado.
3. Ordens dos Blocos de Fatores: a última tabela mostra os blocos de fatores (os fatores dentro de cada bloco evoluem conjuntamente, enquanto entre blocos os fatores são independentes) e a ordem da autoregressão (vetorial).
| Model: | Dynamic Factor Model | # of monthly variables: | 127 |
|---|---|---|---|
| + 10 factors in 9 blocks | # of quarterly variables: | 1 | |
| + Mixed frequency (M/Q) | # of factor blocks: | 9 | |
| + AR(1) idiosyncratic | Idiosyncratic disturbances: | AR(1) | |
| Sample: | 2000-01 | Standardize variables: | True |
| - 2020-01 |
| Dep. variable | Global.1 | Global.2 | Output and Income | Labor Market | Housing | Consumption, orders, and inventories | Money and credit | Interest and exchange rates | Prices | Stock market |
|---|---|---|---|---|---|---|---|---|---|---|
| Real Personal Income | X | X | X | |||||||
| Real personal income ex ... | X | X | X | |||||||
| IP Index | X | X | X | |||||||
| IP: Final Products and N... | X | X | X | |||||||
| IP: Final Products (Mark... | X | X | X | |||||||
| IP: Consumer Goods | X | X | X | |||||||
| IP: Durable Consumer Goo... | X | X | X | |||||||
| IP: Nondurable Consumer ... | X | X | X | |||||||
| IP: Business Equipment | X | X | X | |||||||
| IP: Materials | X | X | X | |||||||
| IP: Durable Materials | X | X | X | |||||||
| IP: Nondurable Materials | X | X | X | |||||||
| IP: Manufacturing (SIC) | X | X | X | |||||||
| IP: Residential Utilitie... | X | X | X | |||||||
| IP: Fuels | X | X | X | |||||||
| Capacity Utilization: Ma... | X | X | X | |||||||
| Help-Wanted Index for Un... | X | X | X | |||||||
| Ratio of Help Wanted/No.... | X | X | X | |||||||
| Civilian Labor Force | X | X | X | |||||||
| Civilian Employment | X | X | X | |||||||
| Civilian Unemployment Ra... | X | X | X | |||||||
| Average Duration of Unem... | X | X | X | |||||||
| Civilians Unemployed - L... | X | X | X | |||||||
| Civilians Unemployed for... | X | X | X | |||||||
| Civilians Unemployed - 1... | X | X | X | |||||||
| Civilians Unemployed for... | X | X | X | |||||||
| Civilians Unemployed for... | X | X | X | |||||||
| Initial Claims | X | X | X | |||||||
| All Employees: Total non... | X | X | X | |||||||
| All Employees: Goods-Pro... | X | X | X | |||||||
| All Employees: Mining an... | X | X | X | |||||||
| All Employees: Construct... | X | X | X | |||||||
| All Employees: Manufactu... | X | X | X | |||||||
| All Employees: Durable g... | X | X | X | |||||||
| All Employees: Nondurabl... | X | X | X | |||||||
| All Employees: Service-P... | X | X | X | |||||||
| All Employees: Trade, Tr... | X | X | X | |||||||
| All Employees: Wholesale... | X | X | X | |||||||
| All Employees: Retail Tr... | X | X | X | |||||||
| All Employees: Financial... | X | X | X | |||||||
| All Employees: Governmen... | X | X | X | |||||||
| Avg Weekly Hours : Goods... | X | X | X | |||||||
| Avg Weekly Overtime Hour... | X | X | X | |||||||
| Avg Weekly Hours : Manuf... | X | X | X | |||||||
| Avg Hourly Earnings : Go... | X | X | X | |||||||
| Avg Hourly Earnings : Co... | X | X | X | |||||||
| Avg Hourly Earnings : Ma... | X | X | X | |||||||
| Housing Starts: Total Ne... | X | X | X | |||||||
| Housing Starts, Northeas... | X | X | X | |||||||
| Housing Starts, Midwest | X | X | X | |||||||
| Housing Starts, South | X | X | X | |||||||
| Housing Starts, West | X | X | X | |||||||
| New Private Housing Perm... | X | X | X | |||||||
| New Private Housing Perm... | X | X | X | |||||||
| New Private Housing Perm... | X | X | X | |||||||
| New Private Housing Perm... | X | X | X | |||||||
| New Private Housing Perm... | X | X | X | |||||||
| Real personal consumptio... | X | X | X | |||||||
| Real Manu. and Trade Ind... | X | X | X | |||||||
| Retail and Food Services... | X | X | X | |||||||
| New Orders for Consumer ... | X | X | X | |||||||
| New Orders for Durable G... | X | X | X | |||||||
| New Orders for Nondefens... | X | X | X | |||||||
| Unfilled Orders for Dura... | X | X | X | |||||||
| Total Business Inventori... | X | X | X | |||||||
| Total Business: Inventor... | X | X | X | |||||||
| Consumer Sentiment Index | X | X | X | |||||||
| M1 Money Stock | X | X | X | |||||||
| M2 Money Stock | X | X | X | |||||||
| Real M2 Money Stock | X | X | X | |||||||
| Monetary Base | X | X | X | |||||||
| Total Reserves of Deposi... | X | X | X | |||||||
| Reserves Of Depository I... | X | X | X | |||||||
| Commercial and Industria... | X | X | X | |||||||
| Real Estate Loans at All... | X | X | X | |||||||
| Total Nonrevolving Credi... | X | X | X | |||||||
| Nonrevolving consumer cr... | X | X | X | |||||||
| MZM Money Stock | X | X | X | |||||||
| Consumer Motor Vehicle L... | X | X | X | |||||||
| Total Consumer Loans and... | X | X | X | |||||||
| Securities in Bank Credi... | X | X | X | |||||||
| Effective Federal Funds ... | X | X | X | |||||||
| 3-Month AA Financial Com... | X | X | X | |||||||
| 3-Month Treasury Bill: | X | X | X | |||||||
| 6-Month Treasury Bill: | X | X | X | |||||||
| 1-Year Treasury Rate | X | X | X | |||||||
| 5-Year Treasury Rate | X | X | X | |||||||
| 10-Year Treasury Rate | X | X | X | |||||||
| Moody’s Seasoned Aaa Cor... | X | X | X | |||||||
| Moody’s Seasoned Baa Cor... | X | X | X | |||||||
| 3-Month Commercial Paper... | X | X | X | |||||||
| 3-Month Treasury C Minus... | X | X | X | |||||||
| 6-Month Treasury C Minus... | X | X | X | |||||||
| 1-Year Treasury C Minus ... | X | X | X | |||||||
| 5-Year Treasury C Minus ... | X | X | X | |||||||
| 10-Year Treasury C Minus... | X | X | X | |||||||
| Moody’s Aaa Corporate Bo... | X | X | X | |||||||
| Moody’s Baa Corporate Bo... | X | X | X | |||||||
| Trade Weighted U.S. Doll... | X | X | X | |||||||
| Switzerland / U.S. Forei... | X | X | X | |||||||
| Japan / U.S. Foreign Exc... | X | X | X | |||||||
| U.S. / U.K. Foreign Exch... | X | X | X | |||||||
| Canada / U.S. Foreign Ex... | X | X | X | |||||||
| PPI: Finished Goods | X | X | X | |||||||
| PPI: Finished Consumer G... | X | X | X | |||||||
| PPI: Intermediate Materi... | X | X | X | |||||||
| PPI: Crude Materials | X | X | X | |||||||
| Crude Oil, spliced WTI a... | X | X | X | |||||||
| PPI: Metals and metal pr... | X | X | X | |||||||
| CPI : All Items | X | X | X | |||||||
| CPI : Apparel | X | X | X | |||||||
| CPI : Transportation | X | X | X | |||||||
| CPI : Medical Care | X | X | X | |||||||
| CPI : Commodities | X | X | X | |||||||
| CPI : Durables | X | X | X | |||||||
| CPI : Services | X | X | X | |||||||
| CPI : All Items Less Foo... | X | X | X | |||||||
| CPI : All items less she... | X | X | X | |||||||
| CPI : All items less med... | X | X | X | |||||||
| Personal Cons. Expend.: ... | X | X | X | |||||||
| Personal Cons. Exp: Dura... | X | X | X | |||||||
| Personal Cons. Exp: Nond... | X | X | X | |||||||
| Personal Cons. Exp: Serv... | X | X | X | |||||||
| S&P’s Common Stock Price... | X | X | X | |||||||
| S&P’s Composite Common S... | X | X | X | |||||||
| S&P’s Composite Common S... | X | X | X | |||||||
| VXO | X | X | X | |||||||
| Real Gross Domestic Prod... | X | X | X |
| block | order |
|---|---|
| Global.1, Global.2 | 4 |
| Output and Income | 1 |
| Labor Market | 1 |
| Housing | 1 |
| Consumption, orders, and inventories | 1 |
| Money and credit | 1 |
| Interest and exchange rates | 1 |
| Prices | 1 |
| Stock market | 1 |
Previsão com Nowcasting
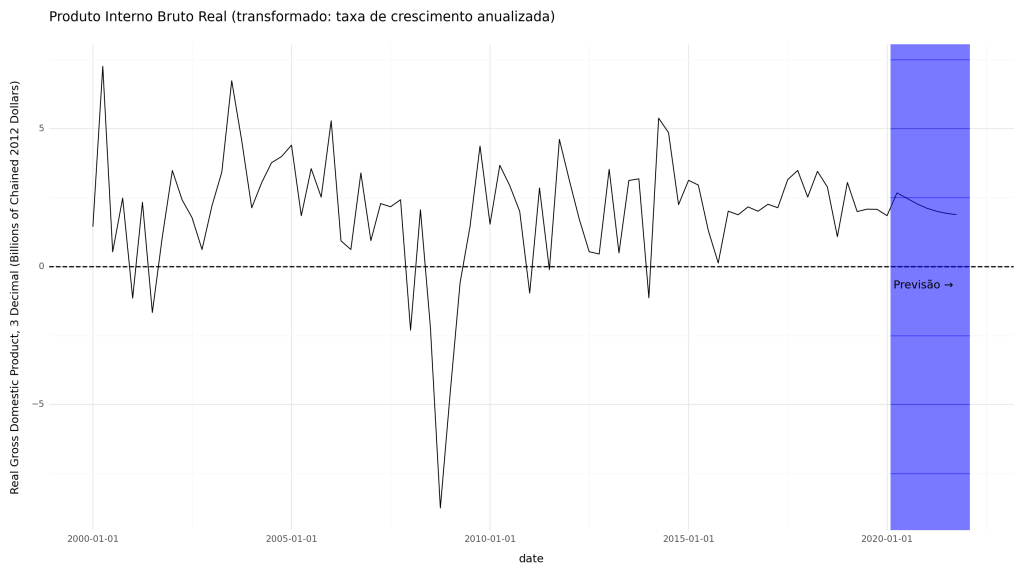
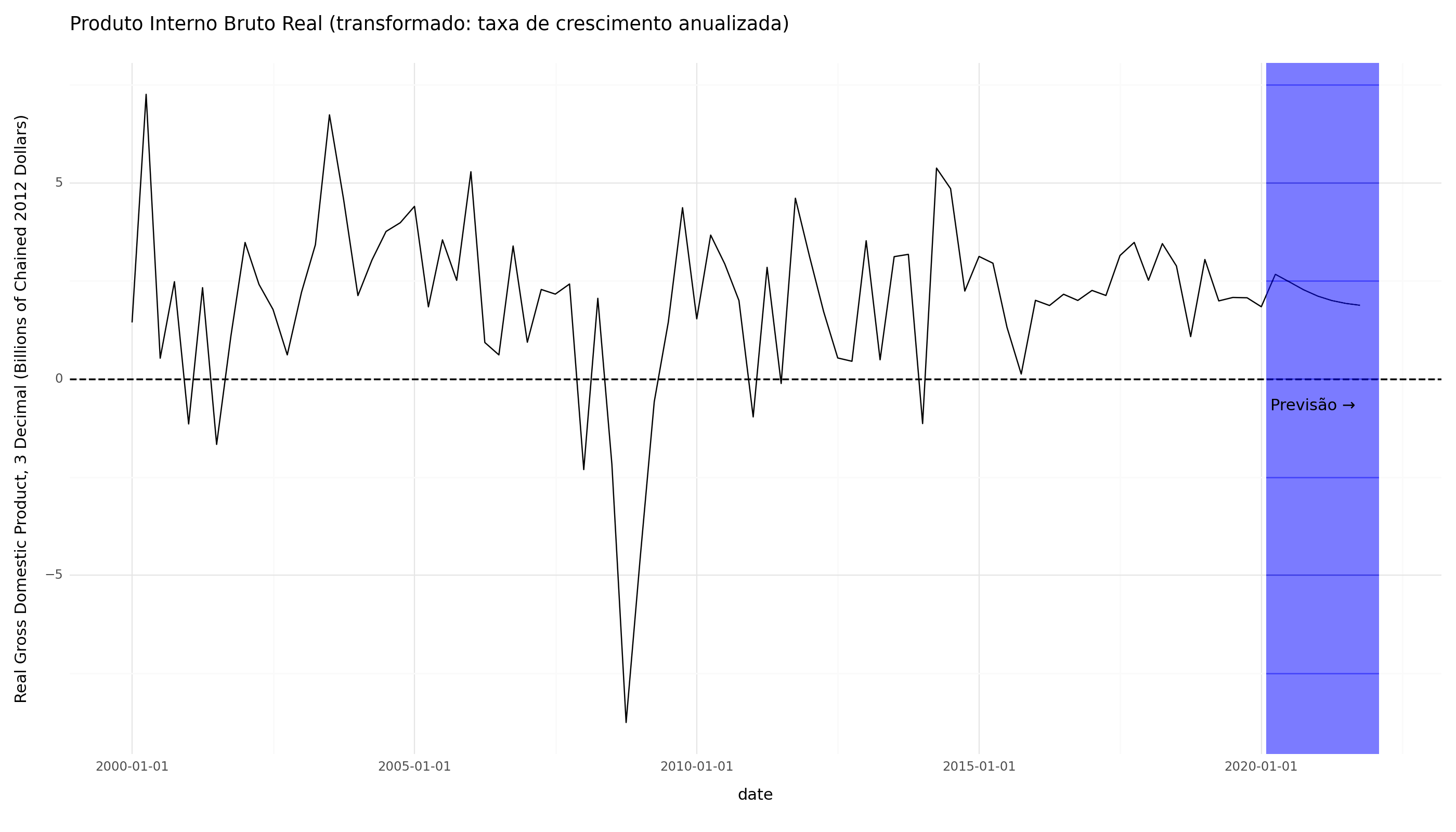
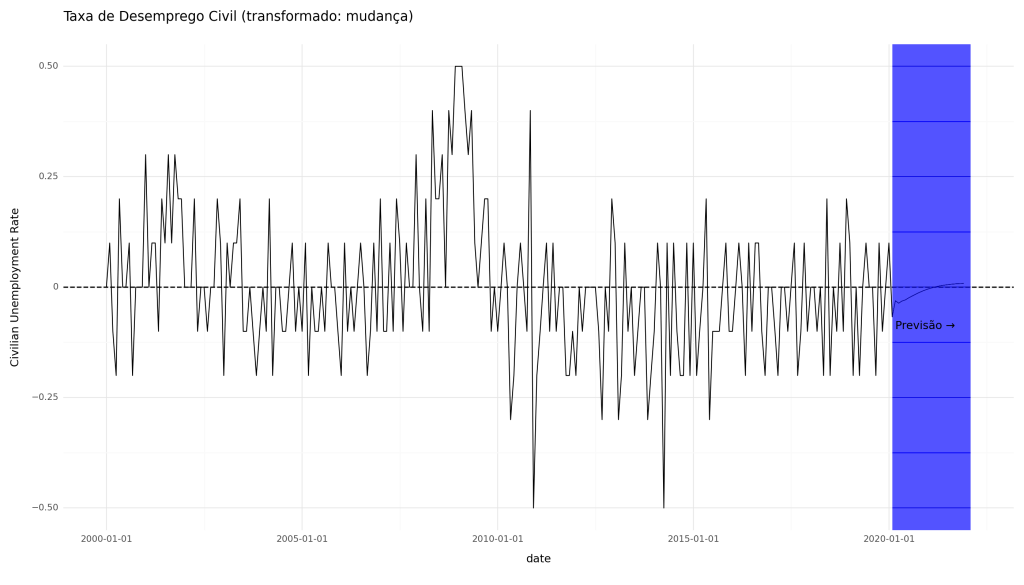
Embora os dados originais nos conjuntos de dados FRED-MD/QD para o PIB Real estejam em "Bilhões de Dólares Corrigidos de 2012", essa variável foi transformada para a taxa de crescimento anualizada trimestral (mudança percentual) para inclusão no modelo. Da mesma forma, a Taxa de Desemprego Civil estava originalmente em "Percentual", mas foi transformada na mudança de 1 mês (primeira diferença) para inclusão no modelo.
Como os dados transformados foram fornecidos ao modelo, os métodos de previsão e previsão produzirão previsões e previsões no espaço transformado. (Lembrete: a etapa de transformação, que fizemos antes de construir o modelo, é diferente da etapa de padronização, que o modelo lida automaticamente e que não precisamos reverter manualmente).
Abaixo, calculamos e plotamos as previsões diretamente do modelo associadas ao PIB Real e à taxa de desemprego.
Referências
Bańbura, Marta, and Michele Modugno. "Maximum likelihood estimation of factor models on datasets with arbitrary pattern of missing data." Journal of Applied Econometrics 29, no. 1 (2014): 133-160.
Bańbura, Marta, Domenico Giannone, and Lucrezia Reichlin. "Nowcasting." The Oxford Handbook of Economic Forecasting. July 8, 2011.
Bok, Brandyn, Daniele Caratelli, Domenico Giannone, Argia M. Sbordone, and Andrea Tambalotti. 2018. "Macroeconomic Nowcasting and Forecasting with Big Data." Annual Review of Economics 10 (1): 615-43.
Fulton, Chad. "Large dynamic factor models, forecasting, and nowcasting". (2020) Acesso em: https://www.chadfulton.com/
Mariano, Roberto S., and Yasutomo Murasawa. "A coincident index, common factors, and monthly real GDP." Oxford Bulletin of Economics and Statistics 72, no. 1 (2010): 27-46.
McCracken, Michael W., and Serena Ng. "FRED-MD: A monthly database for macroeconomic research." Journal of Business & Economic Statistics 34, no. 4 (2016): 574-589.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

