Em previsão, há uma infinidade de modelos que podem ser usados. O processo de escolha do(s) modelo(s) deve ser empírico-científico, usando métodos que visem avaliar a generalização dos algoritmos para dados novos. Neste artigo, mostramos como implementar a metodologia de validação cruzada com algoritmos de machine learning no Python, exemplificando para a previsão do IPCA.
O que é validação cruzada?
A validação cruzada é um processo iterativo que testa um conjunto de modelos para subamostras de dados, obtendo ajustes e efetuando previsões para dados não vistos. Ao final, calcula-se o erro de previsão de todas as iterações e obtém-se um medida global da generalização de cada modelo.
Aplicando validação cruzada no Python
Aqui vamos demonstrar a aplicação de uma validação cruzada para séries temporais usando Python e tomando como exemplo a tarefa de previsão do indicador IPCA da economia brasileira.
Em primeiro lugar, carregamos as bibliotecas necessárias e os dados pré selecionados para previsão:
ipca ibc_br ... inpc ipca_15
data ...
2004-01-01 0.76 -0.011597 ... 0.83 0.68
2004-02-01 0.61 0.008685 ... 0.39 0.90
2004-03-01 0.47 0.118665 ... 0.57 0.40
2004-04-01 0.37 -0.042133 ... 0.41 0.21
2004-05-01 0.51 -0.012466 ... 0.40 0.54
[5 rows x 93 columns]Em seguida, definimos parâmetros de validação cruzada, como o horizonte de previsão de 12 meses, a semente de reprodução, o tamanho de amostras iniciais para os algoritmos e etc.
Janela inicial: 125A seguir, iremos comparar modelos de machine learning com um modelo baseline SARIMA. Para a escolha dos hiperparâmetros do SARIMA, usamos Grid Search para buscar os valores ótimos entre modelos candidatos, minimizando a métrica MSE:
params ... trend
28 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... None
24 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... None
33 {'order': (1, 0, 0), 'seasonal_order': (0, 0, ... ... c
29 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... c
25 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... c
35 {'order': (1, 0, 0), 'seasonal_order': (0, 0, ... ... ct
30 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... t
26 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... t
34 {'order': (1, 0, 0), 'seasonal_order': (0, 0, ... ... t
31 {'order': (1, 0, 0), 'seasonal_order': (0, 1, ... ... ct
[10 rows x 5 columns]Agora, implementamos a validação cruzada de diversos modelos de machine learning usando o sklearn e skforecast.
0%| | 0/11 [00:00<?, ?it/s]
18%|#8 | 2/11 [00:00<00:00, 9.12it/s]
27%|##7 | 3/11 [00:00<00:01, 5.90it/s]
36%|###6 | 4/11 [00:00<00:01, 3.59it/s]
45%|####5 | 5/11 [00:01<00:02, 2.51it/s]
55%|#####4 | 6/11 [00:02<00:03, 1.60it/s]
64%|######3 | 7/11 [00:03<00:02, 1.34it/s]
73%|#######2 | 8/11 [00:03<00:01, 1.65it/s]
82%|########1 | 9/11 [00:04<00:01, 1.93it/s]
91%|######### | 10/11 [00:04<00:00, 1.94it/s]
100%|##########| 11/11 [00:05<00:00, 1.86it/s]
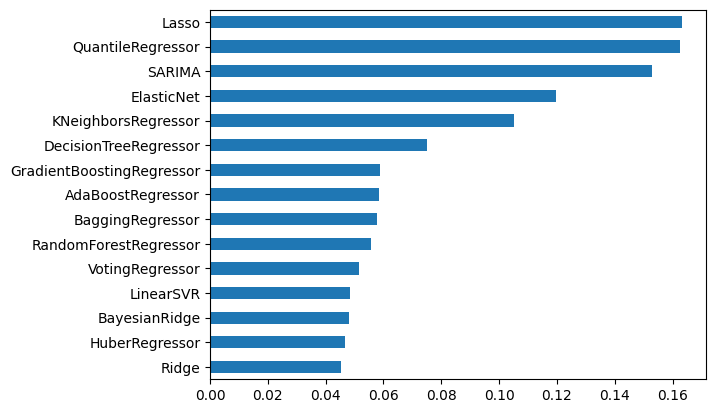
100%|##########| 11/11 [00:05<00:00, 2.05it/s]Por fim, analisamos os resultados pontuais da métrica MSE de validação cruzada de todos os modelos:
Ridge 0.045289
HuberRegressor 0.046737
BayesianRidge 0.048182
LinearSVR 0.048575
VotingRegressor 0.051962
RandomForestRegressor 0.055748
AdaBoostRegressor 0.056882
BaggingRegressor 0.057830
GradientBoostingRegressor 0.058908
DecisionTreeRegressor 0.073417
KNeighborsRegressor 0.105314
ElasticNet 0.119613
SARIMA 0.152752
QuantileRegressor 0.162507
Lasso 0.163402
dtype: float64

Pode-se verificar que o melhor modelo encontrado foi, em média, a regressão Ridge.
Conclusão
Em previsão, há uma infinidade de modelos que podem ser usados. O processo de escolha do(s) modelo(s) deve ser empírico-científico, usando métodos que visem avaliar a generalização dos algoritmos para dados novos. Neste artigo, mostramos como implementar a metodologia de validação cruzada com algoritmos de machine learning no Python, exemplificando para a previsão do IPCA.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, conheça o Clube AM clicando aqui.

