A coleta de dados é uma etapa bastante suscetível a erros, presente em toda análise de dados ou modelo preditivo. Devido a isso e sua importância, muitas pessoas ficam “travadas” quando aparece uma mensagem de erro. Neste exercício mostramos como resolver esse problema usando programação.
Exemplo prático: coleta de dados do Banco Central
Para exemplificar, utilizaremos a API do Banco Central para coletar dados online. O Sistema Gerenciador de Séries Temporais é uma API da instituição que, conhecidamente, apresenta erros rotineiros (infelizmente). Para economistas e analistas que precisam destes dados diariamente, “rezar” para que a coleta de dados funcione de primeira não é uma opção. É necessário uma solução mais robusta.
Uma solução simples e eficiente para erros de coleta de dados online é o uso de estruturas de repetição no Python para que o código “retente” coletar os dados em caso de falha na tentativa anterior. Em termos de código, podemos usar o while em conjunto com o try e except do Python. Ou seja, enquanto um dado número de tentativas de coletar os dados não for atingido, o Python vai tentar rodar um código de coleta e retornar a tabela em caso de sucesso ou ir para a próxima tentativa em caso de falha.
Em termos práticos, primeiro definimos uma função genérica para ler aquivos CSV, pois é este o formato retornado pela API:
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Em seguida, definimos uma função que estrutura a URL parametrizável da API do Banco Central e usa esta URL na função de leitura de CSV:
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Com apenas estas duas funções já temos tudo pronto para coletar dados do Banco Central de forma mais robusta, basta testar:
Coletando a série 433| data | valor | |
|---|---|---|
| 0 | 2000-01-01 | 0.62 |
| 1 | 2000-02-01 | 0.13 |
| 2 | 2000-03-01 | 0.22 |
| 3 | 2000-04-01 | 0.42 |
| 4 | 2000-05-01 | 0.01 |
| ... | ... | ... |
| 295 | 2024-08-01 | -0.02 |
| 296 | 2024-09-01 | 0.44 |
| 297 | 2024-10-01 | 0.56 |
| 298 | 2024-11-01 | 0.39 |
| 299 | 2024-12-01 | 0.52 |
300 rows × 2 columns
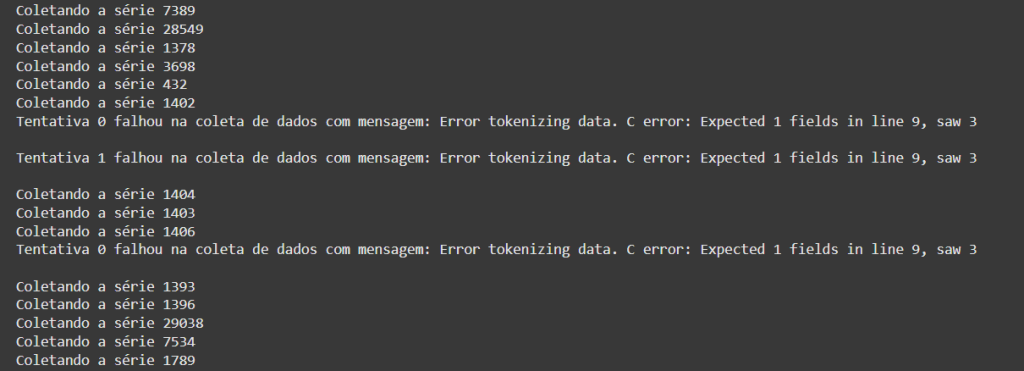
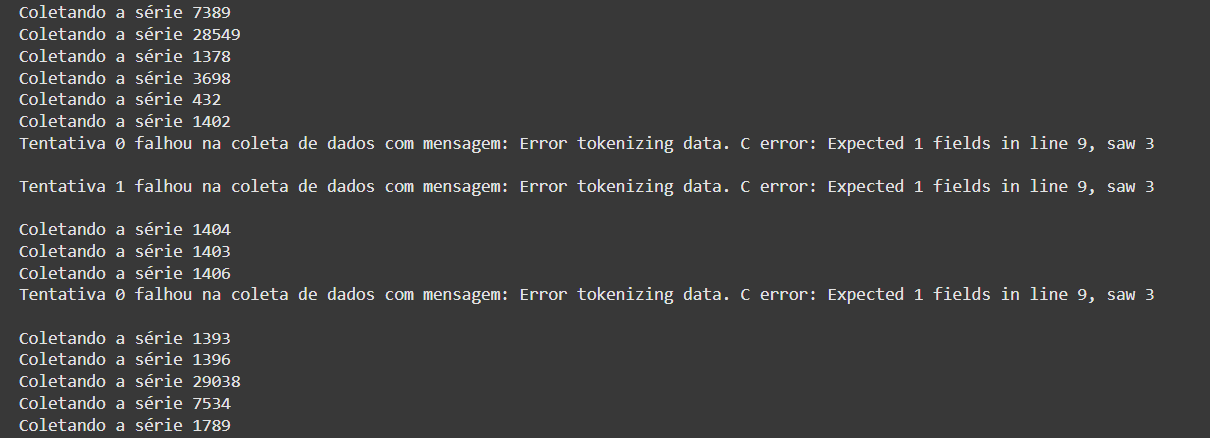
Erros ainda podem acontecer, mas sucessivas retentativas serão executadas. Em últimos casos, se a API estiver fora do ar, não há o que fazer a não ser “rezar” mesmo para que volte a funcionar! =D
Conclusão
A coleta de dados é uma etapa bastante suscetível a erros, presente em toda análise de dados ou modelo preditivo. Devido a isso e sua importância, muitas pessoas ficam “travadas” quando aparece uma mensagem de erro. Neste exercício mostramos como resolver esse problema usando programação.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

