Tradicionalmente, dashboards econômicos são produzidos com a compilação dos dados mais recentes dos principais indicadores econômicos. Gráficos e tabelas costumam ser adicionados e alguns campos de filtros possibilitam customizar a análise. No final, o usuário tem um monte de dados na tela para analisar, muitas vezes sem nenhum contexto.
Será que esta é a melhor experiência/produto que pode ser entregue ao usuário final? Será que uma dashboard com um monte de dados jogados é capaz de responder todas as perguntas que podem surgir? Será que este tipo de dashboard será realmente utilizada?
Podemos tentar mudar o jeito tradicional de produzir dashboards tomando proveito de novas tecnologias emergentes, como a Inteligência Artificial. Ao aplicar IA Generativa, podemos criar uma experiência de análise de dados interativa entre o usuário e a dashboard, sem a necessidade de interferência humana. Isso traz mais agilidade e produtividade para as equipes de análise de dados, além de melhorar a experiência do usuário.
Neste exercício mostramos um exemplo integrando um modelo de IA generativa em uma dashboard de demonstrativos financeiros feita em Python com Shiny.
O código em Python completo deste exercício está disponível para os membros do Clube AM.
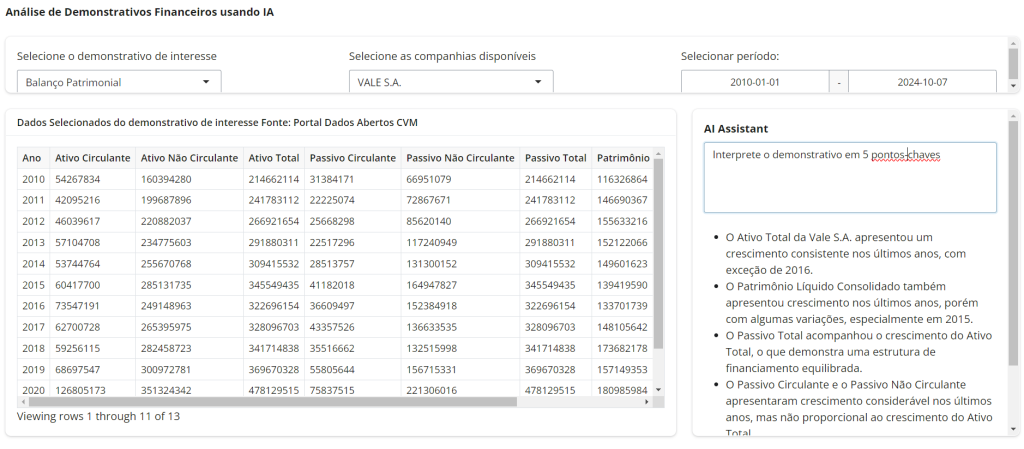
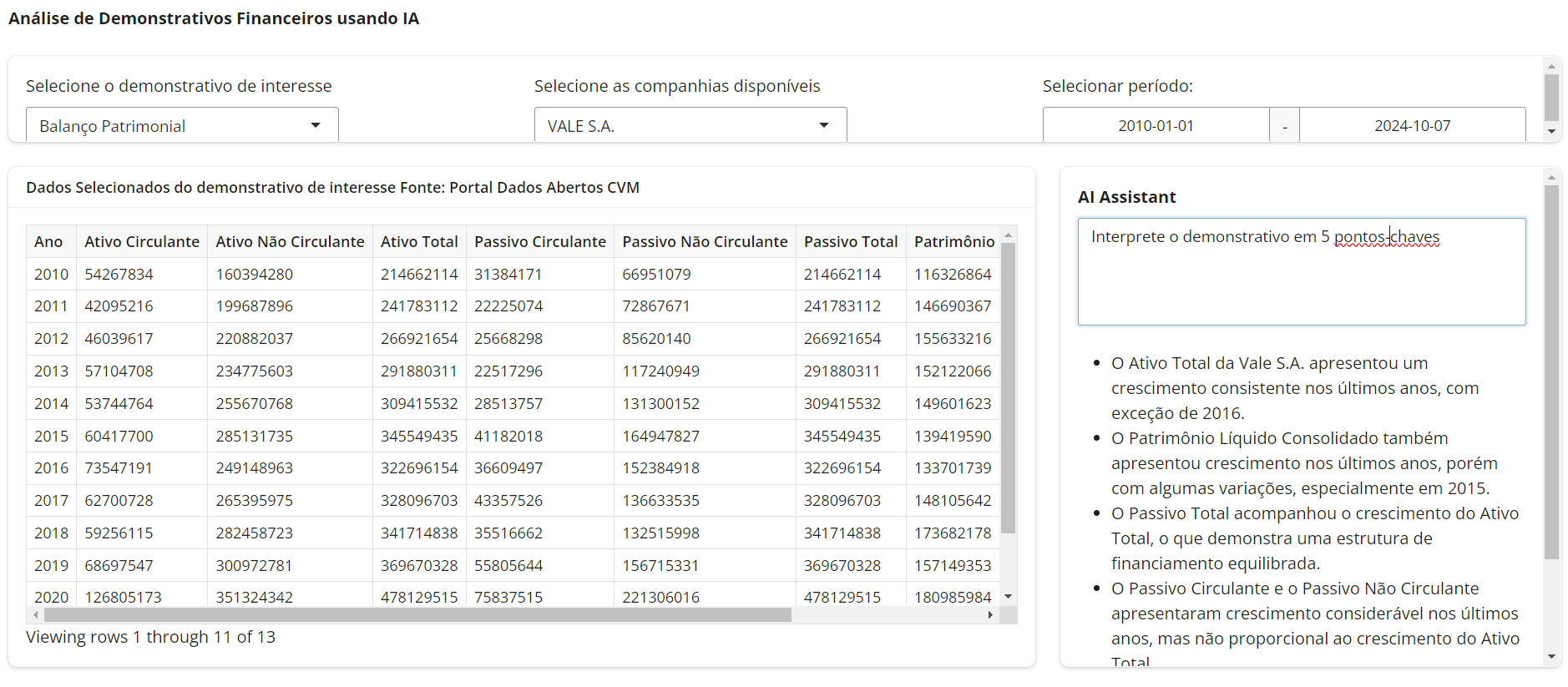
Dashboard de Demonstrativos Financeiros com AI Assistant
Para produzir um dashboard voltado à análise de dados financeiros, seguimos as etapas clássicas do ciclo de análise de dados: coleta, tratamento e visualização.
A coleta de dados dos demonstrativos financeiros é realizada a partir das Demonstrações Financeiras Padronizadas (DFP), que são conjuntos de informações contábeis obrigatórios para empresas de capital aberto. Essas empresas devem enviar os dados à CVM por meio de um formulário eletrônico padronizado.
Os dados da DFP são disponibilizados pela CVM, com a série histórica começando em 2010. Desenvolvemos um código em Python para automatizar a coleta dessas informações.
Na etapa de tratamento de dados, filtramos as observações relevantes, ajustamos os nomes de colunas, categorizamos as informações e selecionamos as contas contábeis mais importantes. O resultado são três demonstrativos principais (balanço patrimonial, demonstração de resultados e fluxo de caixa), com um conjunto selecionado de contas, evitando um dataframe excessivamente extenso.
A visualização dos dados é feita por meio de uma tabela onde cada coluna representa uma conta contábil, e cada linha corresponde a um período, permitindo uma análise clara ao longo do tempo.
Utilizando o Shiny para criar o dashboard, implementamos regras que permitem selecionar o tipo de demonstrativo, a empresa de interesse e o intervalo temporal, proporcionando flexibilidade na análise dos dados.
Além disso, integramos um código de IA Assistant com Gemini, configurado para analisar e comparar os dados contábeis exibidos no dashboard, ampliando as capacidades analíticas da ferramenta.
A imagem abaixo ilustra o resultado final do dashboard criado.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

