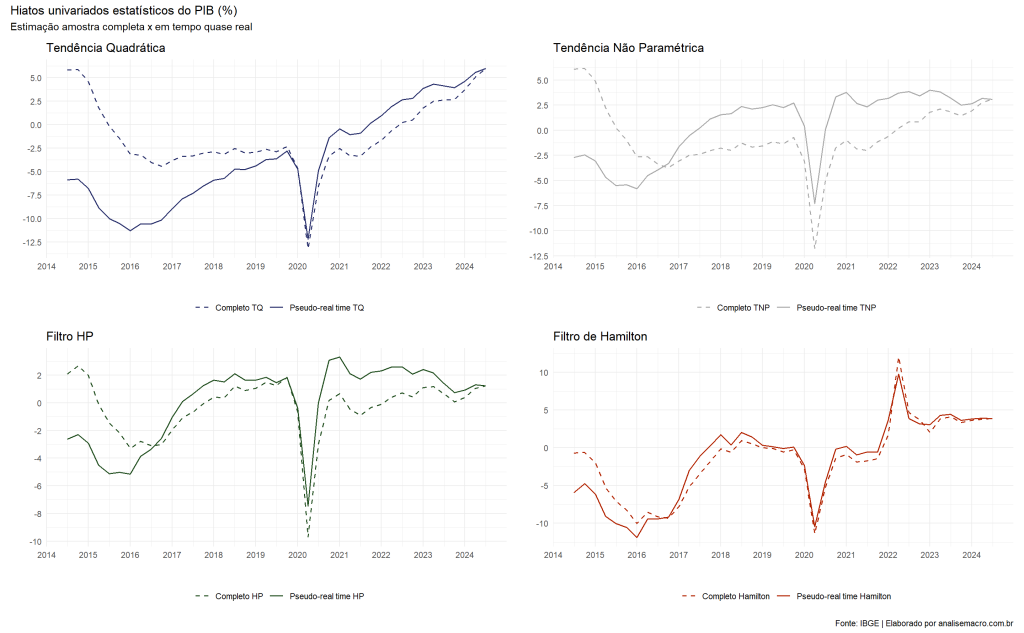
O hiato do produto mede o quanto o PIB observado está acima ou abaixo do PIB potencial, e você consegue estimá-lo por métodos diferentes com dados públicos do IBGE. Este tutorial mostra como fazer isso e, no caminho, expõe uma armadilha: a estimativa mais recente do hiato, justamente a que interessa a quem decide juros hoje, é também a menos confiável.
O motivo é o problema de fim de amostra. Comparando a estimativa feita com toda a série do PIB brasileiro (1996 a 2026) com a estimativa que um analista teria na época, trimestre a trimestre, o resultado é direto: os métodos bidirecionais revisam o hiato a cada novo dado, e a Tendência Quadrática chega a reescrevê-lo em quase 12 pontos percentuais. O Filtro de Hamilton é o que menos revisa.
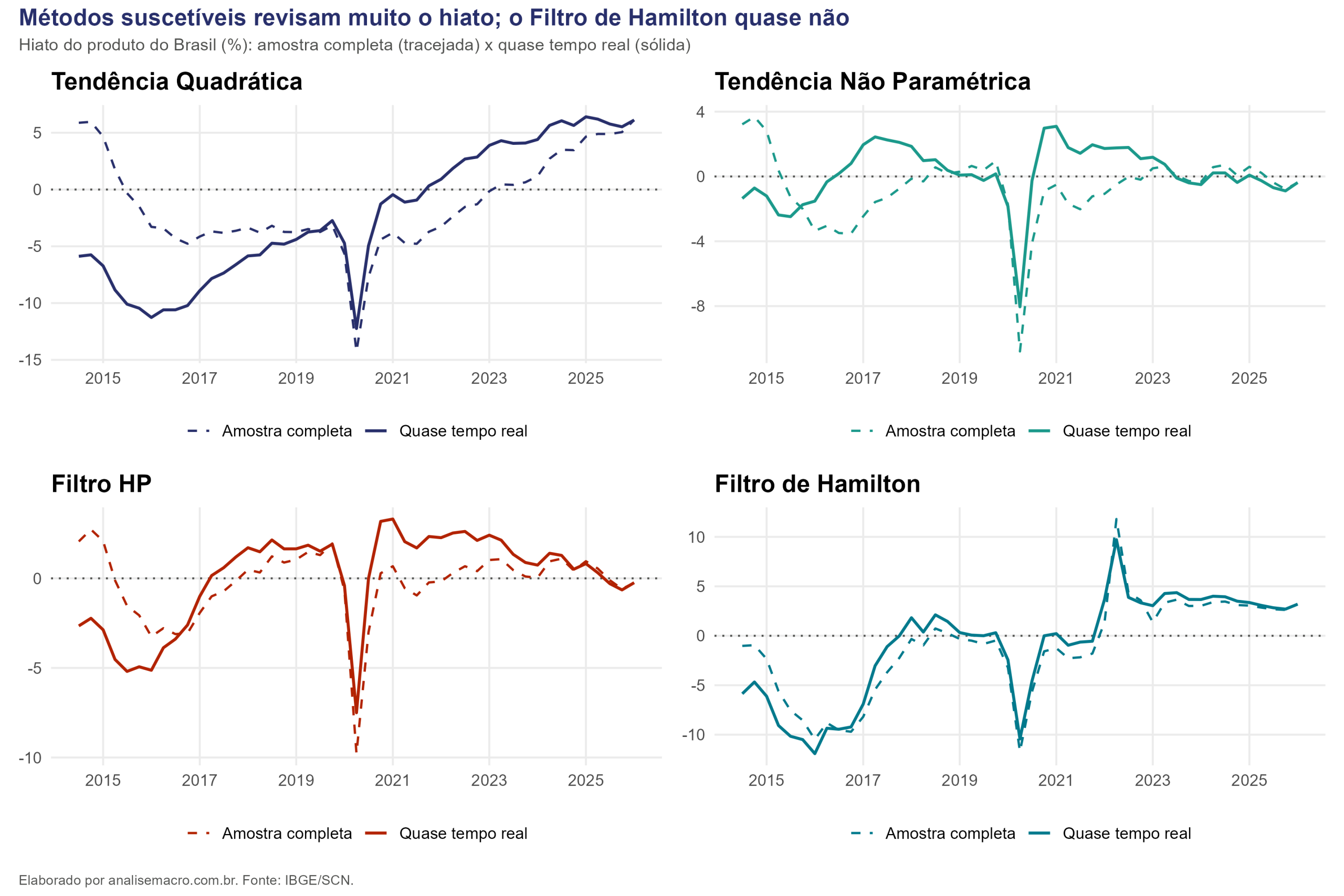
Onde as duas linhas se afastam, há revisão. Na Tendência Quadrática o descolamento é enorme; no Filtro de Hamilton, as linhas quase se sobrepõem. É essa diferença que o tutorial vai construir passo a passo.
Quer reproduzir esta análise?
O script completo em R (que baixa o PIB do SIDRA, estima os quatro métodos e monta o painel comparativo) vai para os assinantes do Boletim AM. Assine, é gratuito, e receba no seu e-mail o código pronto.
O que é o hiato do produto
O hiato do produto é a diferença entre o PIB que a economia de fato produziu e o PIB potencial, o nível de produção sustentável sem pressionar a inflação. Hiato positivo indica demanda aquecida e risco inflacionário; hiato negativo indica capacidade ociosa.
A dificuldade é que o PIB potencial não é observável. Ninguém mede diretamente quanto a economia "poderia" produzir, então esse número precisa ser estimado a partir do PIB observado, separando a tendência (o potencial) do ciclo (o hiato). Existem vários métodos para essa separação, e eles discordam entre si.
É por isso que o hiato é uma variável de referência para o Banco Central: entra na decisão de juros, mas carrega uma incerteza de estimação que raramente aparece nas manchetes. Este exercício torna essa incerteza visível.
O problema de fim de amostra, explicado
O problema de fim de amostra aparece nas pontas de uma série temporal, sobretudo no final, onde falta o "futuro". Métodos que suavizam cada ponto usando informação de toda a série ficam cegos no último trimestre: não têm a metade futura da janela que precisariam.
A consequência prática é a revisão. A cada novo trimestre divulgado, o hiato de trimestres anteriores muda, às vezes muito. Um gestor que tomou uma decisão com o hiato de um trimestre pode ver esse mesmo número reescrito meses depois, quando novos dados chegam e a estimativa se estabiliza.
Para medir esse efeito, o exercício compara dois cenários. No primeiro, o hiato é estimado com a amostra completa, todos os dados de 1996 até hoje, cada ponto cercado de passado e futuro. No segundo, a estimativa é feita em quase tempo real: a conta é refeita como se estivéssemos em cada trimestre do passado, usando apenas os dados que existiam ali. A distância entre os dois é a magnitude do problema.
O termo é "quase" tempo real porque usamos a última versão dos dados do PIB, não a versão exata de cada momento histórico. Como o IBGE revisa o PIB ao longo do tempo, isolar só o efeito da janela de dados (e não o das revisões do próprio PIB) é o que separa o "quase tempo real" do "tempo real" puro.
Como foi feito: coletar, estimar, comparar
O caminho tem três etapas. Cada uma corresponde a um pedaço do código que vai na newsletter; aqui descrevemos o método, não a sintaxe.
📥
📐
🔁
Os quatro métodos e o que cada um pressupõe
Todos são métodos univariados, ou seja, olham só para a série do PIB. Três são suscetíveis ao problema de fim de amostra por construção; o quarto foi desenhado para contorná-lo.
Tendência Quadrática
Assume que o PIB potencial cresce segundo uma parábola no tempo, ajustada por uma regressão de segundo grau. É o método mais simples, mas o mais rígido: como os coeficientes usam toda a série, um choque recente na ponta distorce a curva inteira.
Tendência Não Paramétrica
Suaviza a série com uma regressão local (LOESS), pesando mais as observações próximas de cada ponto e menos as distantes, sem impor uma forma global. É mais flexível que a parábola, mas ainda sente as extremidades, onde a janela de suavização fica truncada.
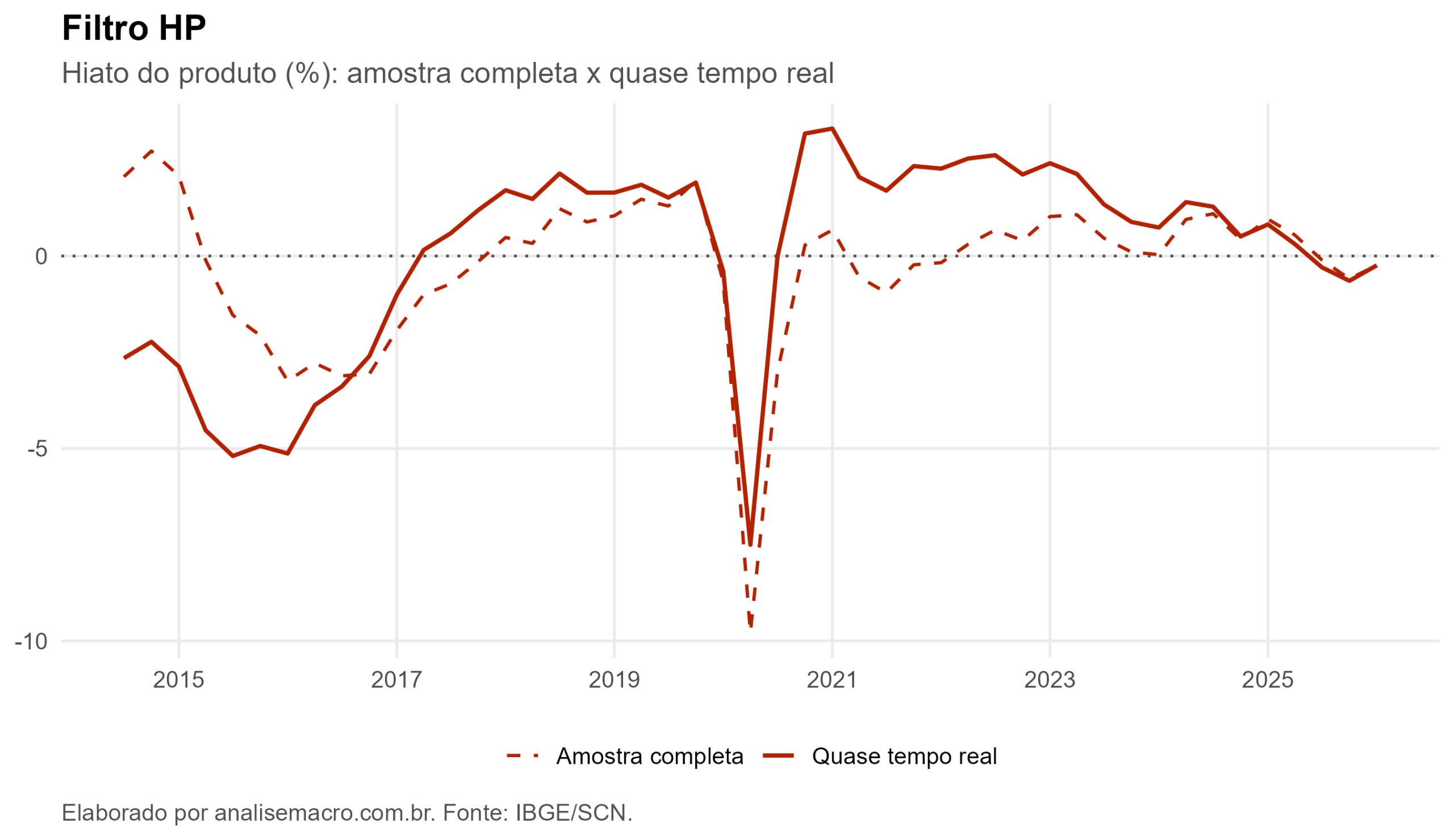
Filtro Hodrick-Prescott (HP)
O método bidirecional mais popular. Ele equilibra dois objetivos: seguir de perto o PIB e manter a tendência suave, controlados por um parâmetro de suavidade. Justamente por ser bidirecional, depende de dados futuros para suavizar cada ponto, e é o principal alvo do problema de fim de amostra. Foi essa fragilidade que motivou a crítica de Hamilton ao HP.
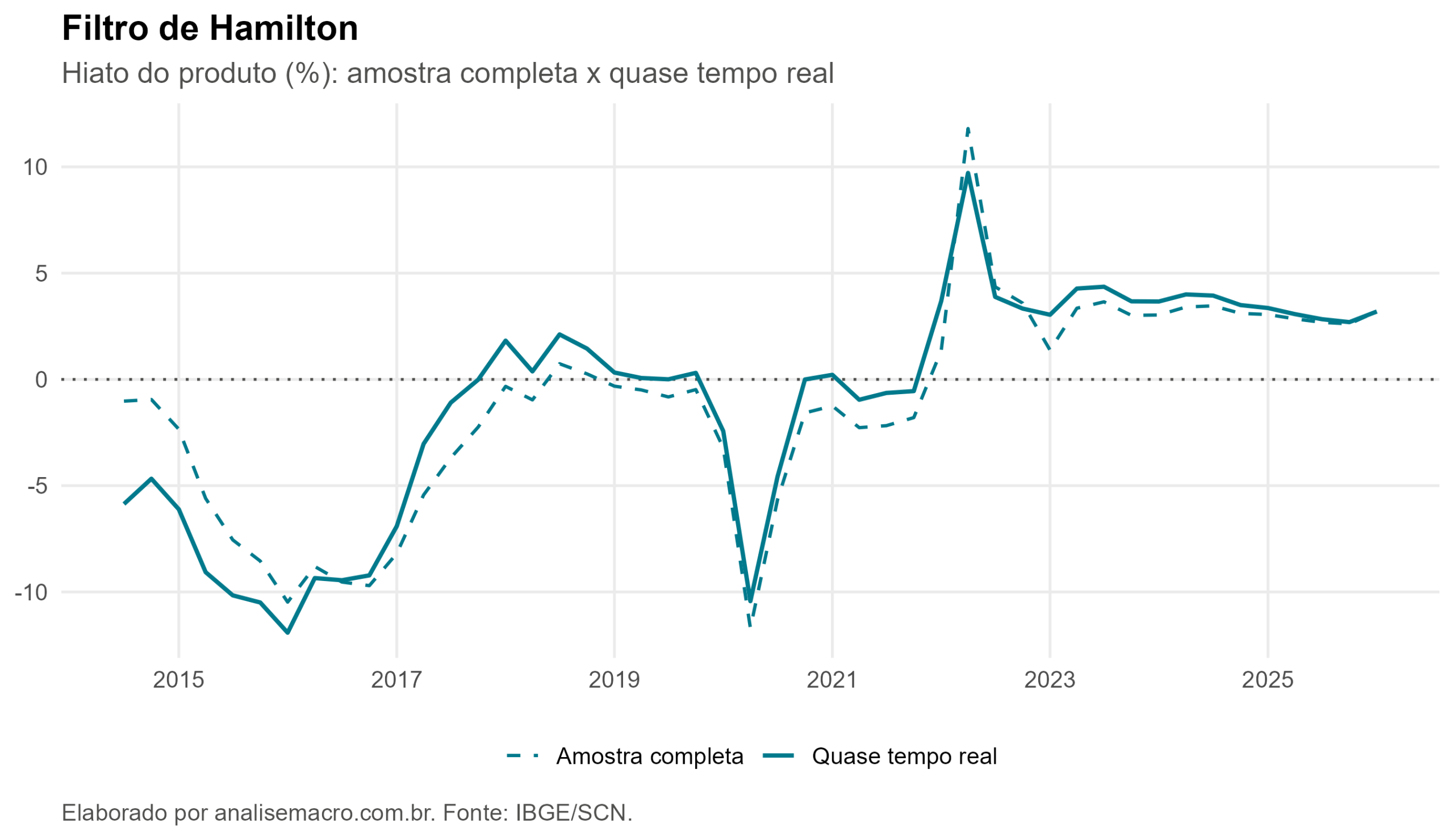
Filtro de Hamilton
Proposto como alternativa ao HP, é unidirecional: estima a tendência prevendo o PIB alguns trimestres à frente a partir de valores passados. Como usa só passado e presente, não depende de dados futuros e, por isso, não distorce nas pontas. O preço é um pequeno atraso para fechar o ciclo, uma limitação previsível, não uma distorção. A previsão da teoria, então, é que a estimativa em tempo real do Hamilton fique quase igual à da amostra completa.
Quanto cada método revisa
A tabela resume a magnitude do problema. Para cada método, ela mostra a revisão média (a diferença absoluta média, em pontos percentuais, entre o hiato final e o de quase tempo real) e a maior revisão observada na janela. Números menores significam mais estabilidade.
| Método | Revisão média (p.p.) | Maior revisão (p.p.) |
|---|---|---|
| Tendência Quadrática | 3,95 | 11,76 |
| Tendência Não Paramétrica | 1,86 | 4,58 |
| Filtro HP | 1,55 | 4,96 |
| Filtro de Hamilton | 1,33 | 4,84 |
Revisão do hiato do produto por método, na janela de 2014 a 2026. Fonte: IBGE/SCN, elaboração Análise Macro.
O Filtro de Hamilton tem a menor revisão média e a menor revisão máxima, confirmando que resiste melhor ao problema. No outro extremo, a Tendência Quadrática chega a reescrever o hiato em quase 12 pontos percentuais, uma diferença enorme para uma variável cujo valor típico fica na casa de poucos pontos. O Filtro HP e a Tendência Não Paramétrica ficam num meio-termo, com revisões médias entre 1,5 e 1,9 ponto.
As ferramentas por trás
Todo o exercício roda em R, com pacotes gratuitos que cobrem da coleta ao gráfico. Cada um resolve uma parte do problema.
Considerações finais
Este exercício expõe uma incerteza que costuma ficar escondida: ela não está só nos dados, está no próprio método de estimação. Com R e dados públicos, em poucas etapas, você reproduz uma análise que até pouco tempo dependia de rotinas fechadas de bancos e instituições, e ainda torna visível o quanto a leitura mais recente do ciclo pode mudar.
O R junta num só lugar a coleta dos dados oficiais brasileiros, os filtros econométricos e a visualização, com pacotes mantidos pela própria comunidade acadêmica. Por isso o mesmo caminho (coletar, tratar, estimar, comparar) se repete em quase todo problema de macroeconomia aplicada. O que muda é a aplicação:
- Economista: estima o hiato, o PIB potencial e outros não observáveis, e comunica a incerteza da estimativa com honestidade.
- Analista macro: monta um monitor de ciclo que se atualiza sozinho a cada divulgação do IBGE, sem planilha manual.
- Gestor e estrategista: entende por que o número mais recente é o mais frágil e evita decisões ancoradas numa leitura que ainda vai ser revisada.
- Risco e research: compara métodos, testa a sensibilidade das conclusões e documenta o processo de forma reproduzível.
Aprender R é o que abre a porta para todas essas frentes.
Você viu como funciona; aprenda a construir
Estimar o hiato do produto, tratar contas nacionais e modelar séries macro do começo ao fim é o que você domina na Formação em Análise Macroeconômica. Quem quer acesso a todas as formações tem o AM Black, a assinatura anual.
Conheça a Formação em Análise Macroeconômica →Ver o AM Black →
Leia também:

