O índice de condições financeiras resume, em um único número, se o ambiente financeiro está apertando ou afrouxando a economia. Neste tutorial mostramos como reconstruir no Python o ICF do Banco Central do Brasil usando apenas dados públicos, e como decompô-lo para ver o que puxa cada movimento.
O resultado replica de perto o índice oficial: a versão que construímos tem correlação de 0,896 com o ICF divulgado pelo BCB, sem usar nenhuma base paga. A prova está no gráfico abaixo.
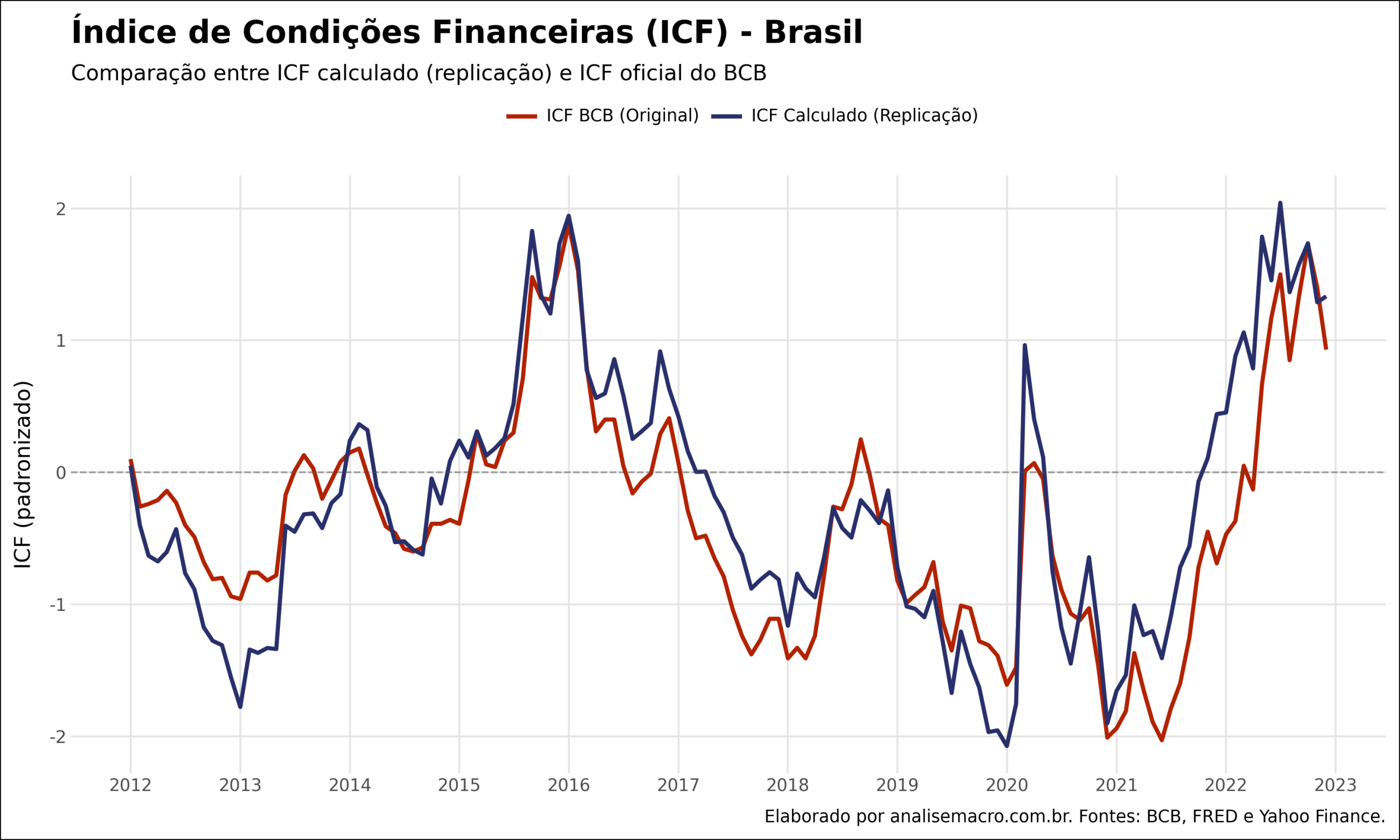
As duas linhas quase se sobrepõem em toda a amostra que o BCB publica, o que valida a metodologia. A seguir mostramos como chegar até esse resultado, passo a passo, e como abrir o índice por grupo de fatores.
Quer reproduzir este índice?
O código completo em Python (coleta das APIs do BCB, FRED e Yahoo Finance, extração dos fatores por PCA, ponderação e decomposição) vai para os assinantes do Boletim AM. Assine, é gratuito, e receba no seu e-mail o script pronto para rodar.
O que é um índice de condições financeiras
As condições financeiras descrevem o custo e a disponibilidade de crédito para famílias e empresas. Quando estão restritivas — juros altos, risco elevado, câmbio depreciado, bolsa em queda —, elas freiam o consumo e o investimento. Quando estão estimulativas, aceleram.
O problema é que "condições financeiras" não é uma variável observável: é um conceito que se manifesta em dezenas de preços de mercado ao mesmo tempo. O índice de condições financeiras (ICF) resolve isso agregando essas variáveis em um só indicador. Por convenção, valores positivos indicam aperto e valores negativos indicam afrouxamento.
Este exercício replica a metodologia que o Banco Central descreve no Boxe 5 do Relatório de Inflação de dezembro de 2022 e no Estudo Especial nº 76. A adaptação central é usar apenas fontes públicas e automatizáveis, o que torna o índice reproduzível de ponta a ponta no Python.
Como o índice é construído
A construção segue quatro etapas. Cada uma resolve um problema específico de juntar variáveis muito diferentes em uma medida comparável.
Os sete grupos de variáveis
As variáveis cobrem tanto o mercado local quanto o global, porque as condições financeiras no Brasil respondem às duas frentes. São eles: juros Brasil (NTN-B de 5 e 10 anos e Selic esperada), juros exterior (títulos soberanos de EUA, Alemanha, Reino Unido e Japão), risco (VIX e spread Brasil-EUA), moedas (dólar, moedas emergentes e real), petróleo (WTI e Brent), commodities (índices metálico e agropecuário do BCB) e mercado de capitais (Ibovespa, MSCI World e MSCI Emerging Markets).
O tratamento das séries
Antes de modelar, tudo passa por três ajustes. Primeiro, a frequência: as séries diárias viram mensais, por média ou último valor do mês. Segundo, a remoção de tendência: variáveis com tendência de longo prazo, como índices de bolsa e commodities, têm a tendência linear subtraída, para que o índice capte oscilação e não nível. Terceiro, a padronização por z-score, que coloca todas na mesma escala (média zero, desvio-padrão um) — sem isso, uma variável com números grandes dominaria o resultado só pela unidade.
A extração de fatores com PCA
A Análise de Componentes Principais (PCA) é a peça central. Ela encontra, dentro de cada grupo, a combinação das variáveis que captura a maior parte da variação conjunta. Essa combinação — a primeira componente principal — é o "fator comum" do grupo. Se as taxas de 5 e 10 anos e a Selic esperada sobem juntas, esse fator sobe com elas e passa a resumir, em uma série só, o nível de juros. Reduzir cada grupo a um fator evita contar duas vezes variáveis que andam juntas.
Há um detalhe técnico que faz diferença no resultado: o sinal de uma componente principal é indeterminado. Matematicamente, o fator e o seu negativo explicam a mesma variação, e o algoritmo pode devolver qualquer um dos dois. Para o índice ter interpretação estável, ancoramos o sinal de cada subíndice em uma variável de referência — a NTN-B nos juros, o VIX no risco, o Ibovespa na bolsa — de modo que subíndice maior signifique sempre condições mais restritivas.
A ponderação pela relevância econômica
Os sete subíndices não pesam igual. Para definir o peso de cada um, mede-se sua relevância econômica por uma regressão contra a variação futura do IBC-Br, a proxy mensal do PIB. Quanto mais um grupo se relaciona com a atividade seis meses à frente, maior seu peso no índice. O ICF final é a soma ponderada dos subíndices, padronizada. A tabela abaixo mostra o peso de cada grupo.
| Grupo de fatores | Peso no índice |
|---|---|
| Risco | 26,3% |
| Moedas | 16,9% |
| Juros Brasil | 16,6% |
| Mercado de Capitais | 14,8% |
| Commodities | 10,5% |
| Juros Exterior | 8,3% |
| Petróleo | 6,5% |
Peso de cada grupo no ICF, pela relevância econômica frente à atividade futura. Fonte: elaboração própria.
Risco, moedas e juros locais concentram quase 60% do índice — coerente com o que costuma mover as condições financeiras de uma economia emergente.
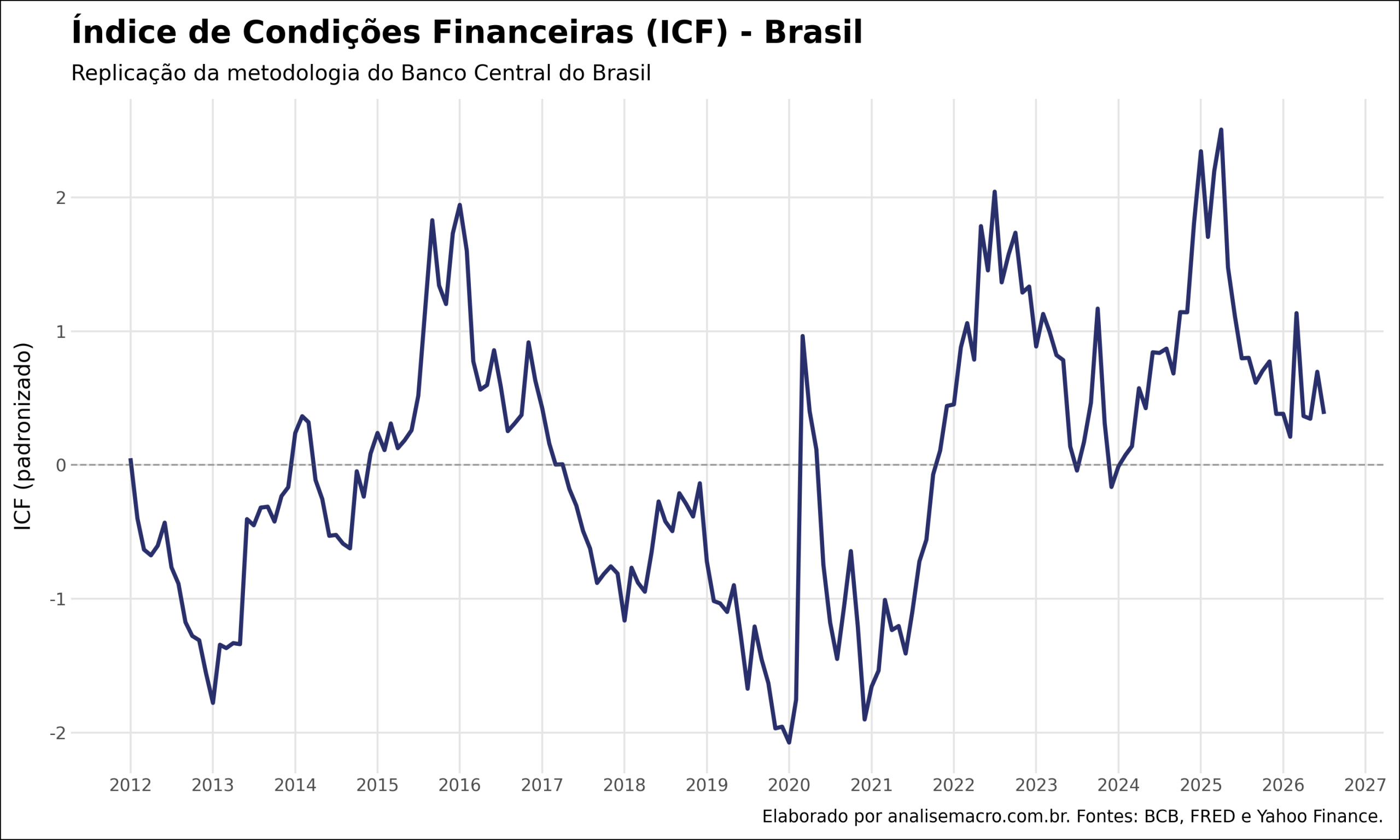
O índice até o dado mais recente
Validada a replicação contra o BCB, o mesmo índice pode ser estendido até o dado mais recente, já que todas as fontes são de acesso contínuo. O gráfico abaixo traz a série completa.
Abrindo o índice: a decomposição
Como o ICF é uma soma ponderada dos subíndices, ele pode ser aberto para revelar quanto cada grupo contribuiu em cada mês. Essa é a decomposição: a leitura mais útil do índice, porque separa um aperto vindo de juros de um aperto vindo de câmbio ou de risco global.
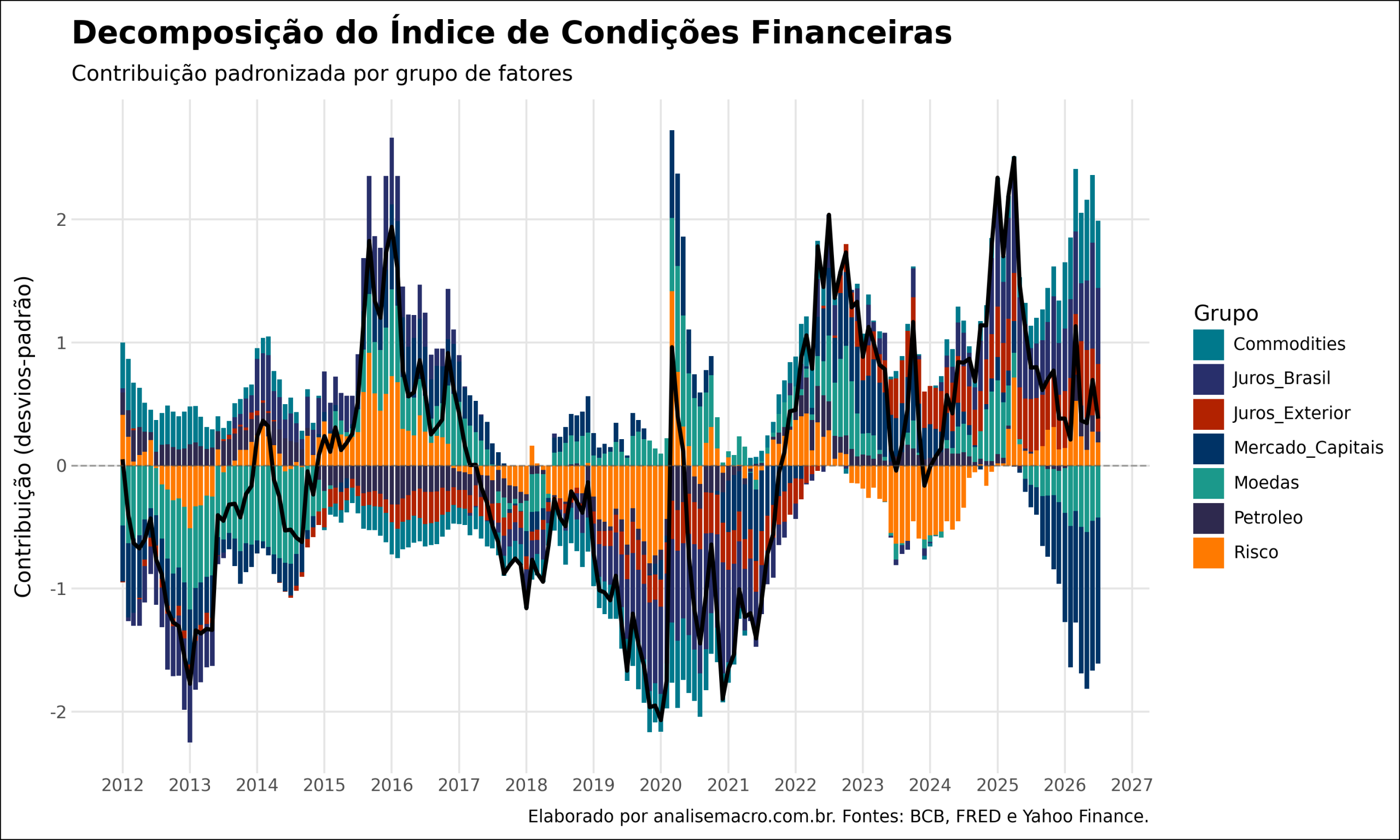
Cada barra soma as contribuições dos grupos naquele mês, e a linha preta é o índice resultante. A leitura fica direta: nos episódios de aperto, dá para ver se o empurrão veio dos juros locais, do risco global ou do câmbio — informação que o índice agregado, sozinho, esconde.
As ferramentas por trás
pandas, scikit-learn (PCA e regressão) e plotnine para os gráficos.python-bcb.pandas-datareader e yfinance.
Considerações finais
Este exercício mostra algo que era, até pouco tempo, restrito a mesas de análise: reconstruir um indicador oficial do Banco Central com dados públicos e poucas etapas de código, chegando a uma correlação de quase 0,90 com a série original.
O Python é a ferramenta certa para isso porque reúne, num só ambiente, a coleta das APIs, o tratamento das séries, a modelagem estatística (PCA e regressão) e a visualização. O mesmo caminho — coletar, tratar, modelar, visualizar — se repete em quase todo problema de análise macrofinanceira. O que muda é a aplicação:
- Economistas: monitorar o aperto ou afrouxamento das condições financeiras como leitura complementar à política monetária.
- Analistas de mercado: antecipar inflexões do ciclo, já que condições financeiras costumam anteceder a atividade.
- Gestores e traders: ler o ambiente de risco de forma sintética e decompô-lo por fator para entender de onde vem o estresse.
- Risco e research: construir indicadores próprios, calibrados à carteira ou ao mandato, em vez de depender de um número fechado.
Aprender a linguagem é o que abre a porta para todas essas frentes: com o método na mão, o mesmo pipeline vira dezenas de indicadores.
Você viu como funciona. Aprenda a construir do zero
Coletar dados de APIs públicas, tratar séries temporais, aplicar PCA e regressão e montar gráficos: é exatamente o que você pratica, do zero e sem pré-requisito, na formação Do Zero à Análise de Dados Econômicos e Financeiros usando Python e IA. Quem quer acesso a todas as formações tem o AM Black, a assinatura anual.
Leia também: