Um SVAR (Vetor Autoregressivo Estrutural) é o modelo que isola um choque econômico com significado, como um aperto de juros, e mostra como cada variável da economia reage a ele ao longo do tempo. Neste tutorial você vai ver como construir um SVAR no Python, passo a passo, com dados reais da economia brasileira: atividade, inflação, juros e commodities, coletados direto da API do Banco Central.
Um aviso sobre o objetivo: este é um tutorial de método. A meta é ensinar como se monta, se estima e se lê um SVAR, não entregar o modelo definitivo da política monetária brasileira. Por isso vamos deixar o modelo tropeçar num problema clássico da literatura, entender por que isso acontece e testar um caminho de correção. O modelo final continua imperfeito, e mostrar onde ele falha ensina mais do que esconder o problema.
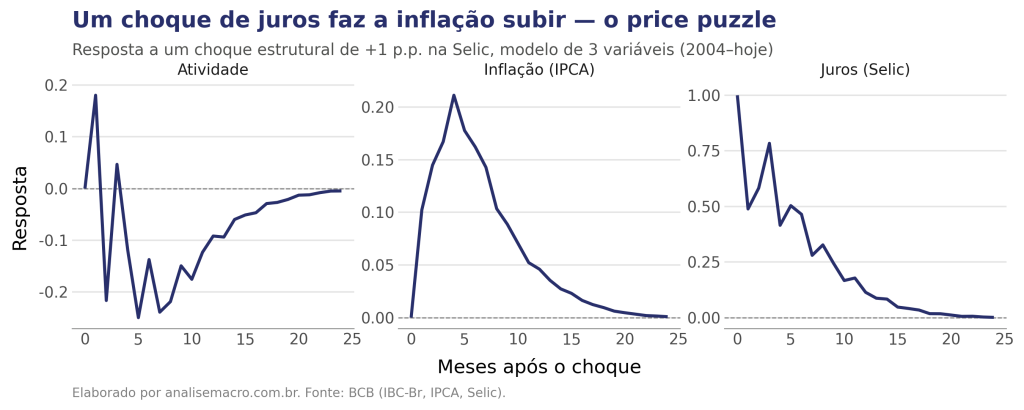
O gráfico acima é a saída principal de um SVAR, chamada de função de impulso-resposta. Ela responde a uma pergunta direta: o que acontece com a inflação, mês a mês, depois que o Banco Central aumenta os juros em 1 ponto percentual? O eixo horizontal são os meses após esse aumento; a linha mostra como a inflação reage a cada mês.
E aqui aparece algo curioso. A teoria diz que subir os juros deveria reduzir a inflação, mas as duas linhas sobem: no modelo, apertar os juros parece aumentar a inflação. Esse resultado torto tem nome, o price puzzle, e é o fio que conduz este tutorial. As duas linhas são duas versões do modelo, e a diferença entre elas é o primeiro passo para entender o problema. O tutorial abaixo mostra como se chega até esse gráfico e o que fazer com ele.
Quer o código completo deste SVAR?
O script em Python (coleta na API do BCB, teste de estacionariedade, estimação do SVAR, impulso-resposta e decomposição de variância) vai para os assinantes do Boletim AM, pronto para rodar. Assine, é gratuito, e receba no e-mail.
O que o SVAR faz que um VAR comum não faz
Um VAR (Vetor Autoregressivo) descreve várias séries em que cada uma depende das defasagens de todas as outras. Ele é ótimo para previsão, mas cego para a causalidade contemporânea: não sabe dizer quem afeta quem dentro do mesmo mês.
O problema mora nos resíduos. Se o choque não observado que mexe na inflação hoje anda junto com o que mexe nos juros hoje, os resíduos das duas equações ficam correlacionados. E com resíduos correlacionados é impossível afirmar "isolei um choque de juros puro".
O SVAR resolve isso impondo uma teoria econômica sobre as relações do mesmo mês. A ideia central: existem choques estruturais genuinamente independentes (um choque de política monetária, um de oferta) e o que observamos é uma mistura deles. O modelo estima a receita dessa mistura, guardada numa matriz que os econometristas chamam de matriz de impacto contemporâneo.
As quatro variáveis e por que cada uma entra
O exercício usa quatro séries mensais da economia brasileira, todas públicas e coletadas na API do Sistema Gerenciador de Séries Temporais (SGS) do Banco Central — sem cadastro, sem chave de API. Cada uma tem um papel econômico claro:
Estacionariedade: o passo que decide se o modelo faz sentido
Antes de estimar qualquer VAR, é preciso garantir que as séries são estacionárias: com média e variância estáveis no tempo. Rodar o modelo em séries de nível com tendência produz regressões espúrias e impulsos-resposta sem sentido.
O diagnóstico é o teste ADF (Augmented Dickey-Fuller). Ele testa se a série tem raiz unitária, ou seja, se não é estacionária. No exercício, três das quatro séries reprovam no teste em nível e precisam de transformação: o IBC-Br e o IC-Br viram variação percentual mensal, e a Selic vira primeira diferença. Só o IPCA, que já é uma variação de preços, passa direto. Depois de transformar, todas ficam estacionárias.
A escolha da transformação não é aleatória: cada tipo tem um custo. A tabela abaixo resume as opções e quando usar cada uma:
| Transformação | O que faz | Quando usar |
|---|---|---|
| Nível bruto | Preserva o longo prazo, mas viola a estacionariedade | Só sob cointegração (aí o modelo é VECM, não VAR) |
| Log do nível | Estabiliza a variância; continua não-estacionário | Passo intermediário, não resolve sozinho |
| Primeira diferença | Remove tendência, mantém a escala original | Taxas persistentes (a Selic) |
| Log-diferença (variação %) | Remove tendência e estabiliza variância | Índices multiplicativos (IBC-Br, IC-Br) |
As opções de transformação para tornar uma série estacionária, com o trade-off de cada uma.
Não existe transformação certa universal: a escolha segue a pergunta. Como aqui queremos o efeito de um choque mês a mês, usamos a variação mensal. Quem quiser a relação de médio prazo entre a tendência do IC-Br e a inflação usaria a variação interanual (contra o mesmo mês do ano anterior), que é como o mercado acompanha esses índices. E quem estudasse o equilíbrio de longo prazo entre os níveis partiria para um teste de cointegração. Cada caminho responde a uma pergunta diferente.
O tempo da economia: quando cada choque faz efeito
Um ponto que decide como o modelo é lido: a frequência com que o dado é medido não é a mesma com que a economia reage.
O efeito da política monetária é lento. Quando o Banco Central sobe a Selic, a economia real não esfria no mês seguinte: o canal de demanda leva de dois a quatro trimestres para o efeito pleno, e o impacto sobre a inflação se completa perto de um ano depois. É por isso que o BC decide olhando vários trimestres à frente, não o próximo IPCA.
O repasse do câmbio aos preços também é gradual. A pressão de uma alta do dólar se distribui por até quatro trimestres, embora tenha ficado mais rápida depois de 2009. E há um descompasso a mais: o Copom decide a cada 45 dias, em oito reuniões por ano, mas o dado mensal da Selic "achata" esse calendário, com meses que contêm uma decisão e meses que não contêm nenhuma.
A consequência prática aparece na leitura dos resultados: o horizonte do impulso-resposta precisa ser longo o bastante para o efeito completar a propagação. Por isso o exercício usa 24 meses. Um gráfico de 3 ou 6 meses cortaria a história justamente no ponto em que a política monetária começa a agir.
Identificação: a matriz que codifica a economia
O coração do SVAR é a identificação: escolher restrições que permitam separar os choques estruturais. A abordagem mais transparente é a identificação recursiva, em que se impõe uma ordem causal contemporânea entre as variáveis.
A lógica econômica é a velocidade de ajuste. A atividade e a inflação são rígidas no curtíssimo prazo e não reagem aos juros dentro do mesmo mês, porque o efeito da política monetária leva trimestres. Os juros, ao contrário, respondem à atividade e à inflação no próprio mês, porque é isso que o Banco Central faz ao seguir uma regra de Taylor. Por isso os juros entram por último na ordem: o BC reage a tudo, mas nada reage aos juros contemporaneamente.
Cada restrição imposta é uma hipótese econômica, e você pode discuti-la e testá-la. O VAR comum não traduz teoria em estrutura; o SVAR faz isso, e por isso consegue isolar um choque com significado econômico.
O price puzzle aparece — e o que ele significa
Com o modelo de três variáveis estimado, o impulso-resposta a um choque de juros deveria mostrar a inflação caindo. Não é o que acontece.
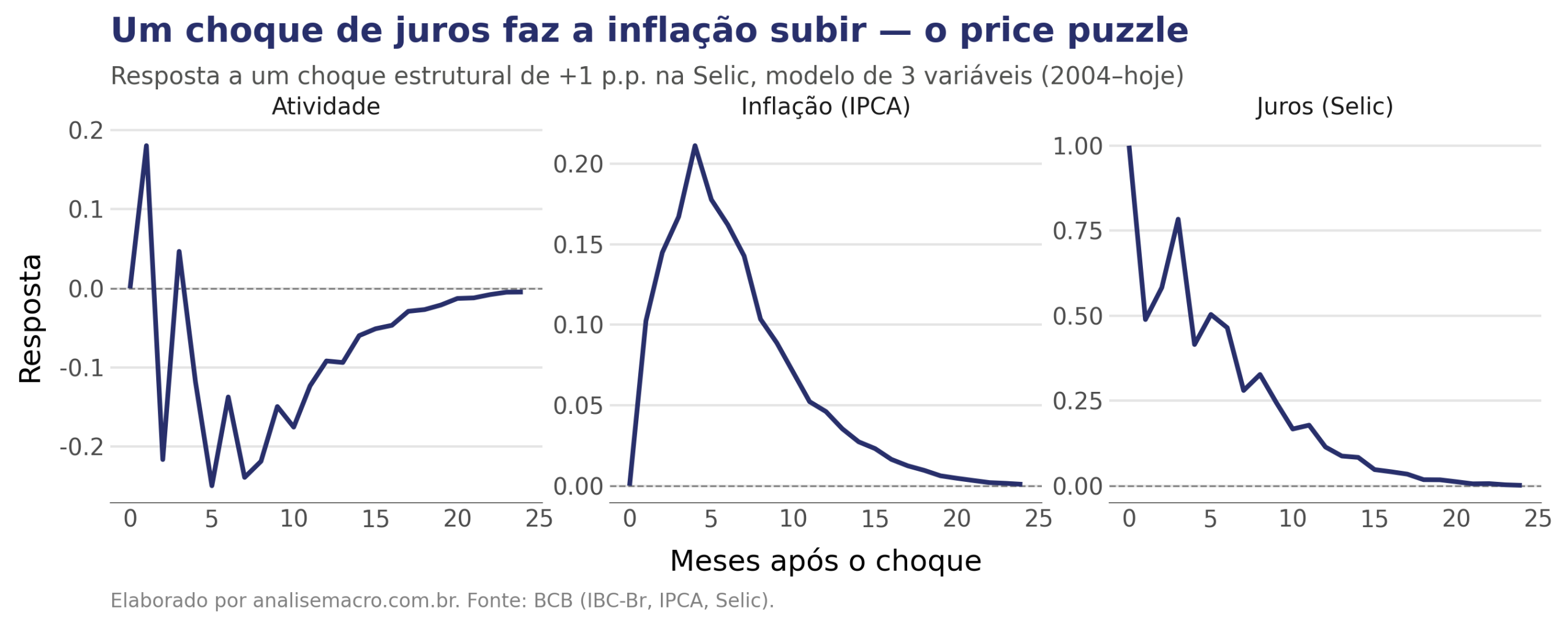
A atividade recua ao longo dos meses, com alguma oscilação no início, coerente com um aperto monetário. Mas a inflação sobe, com pico de cerca de +0,21 p.p. no quarto mês. Esse é o price puzzle, documentado por Christopher Sims em 1992: apertar os juros parece aumentar a inflação.
A causa está na forma como o choque é identificado. O Banco Central tem mais informação que o modelo. Quando ele antecipa uma pressão de custos futura, como uma alta de commodities ou uma depreciação cambial, sobe os juros preventivamente. Meses depois, o choque de custos chega e a inflação sobe. O modelo, cego para o custo, credita a alta dos preços aos juros. O choque rotulado de "monetário" carrega a reação do BC a uma pressão que ele já via chegando.
A correção: dar ao modelo o que o Banco Central enxerga
A solução padrão é incluir a variável omitida. O IC-Br em reais é ideal: capta o custo externo das commodities e o repasse cambial num único canal, e entra como a série mais exógena do sistema, já que os preços globais não reagem à economia brasileira dentro do mês.
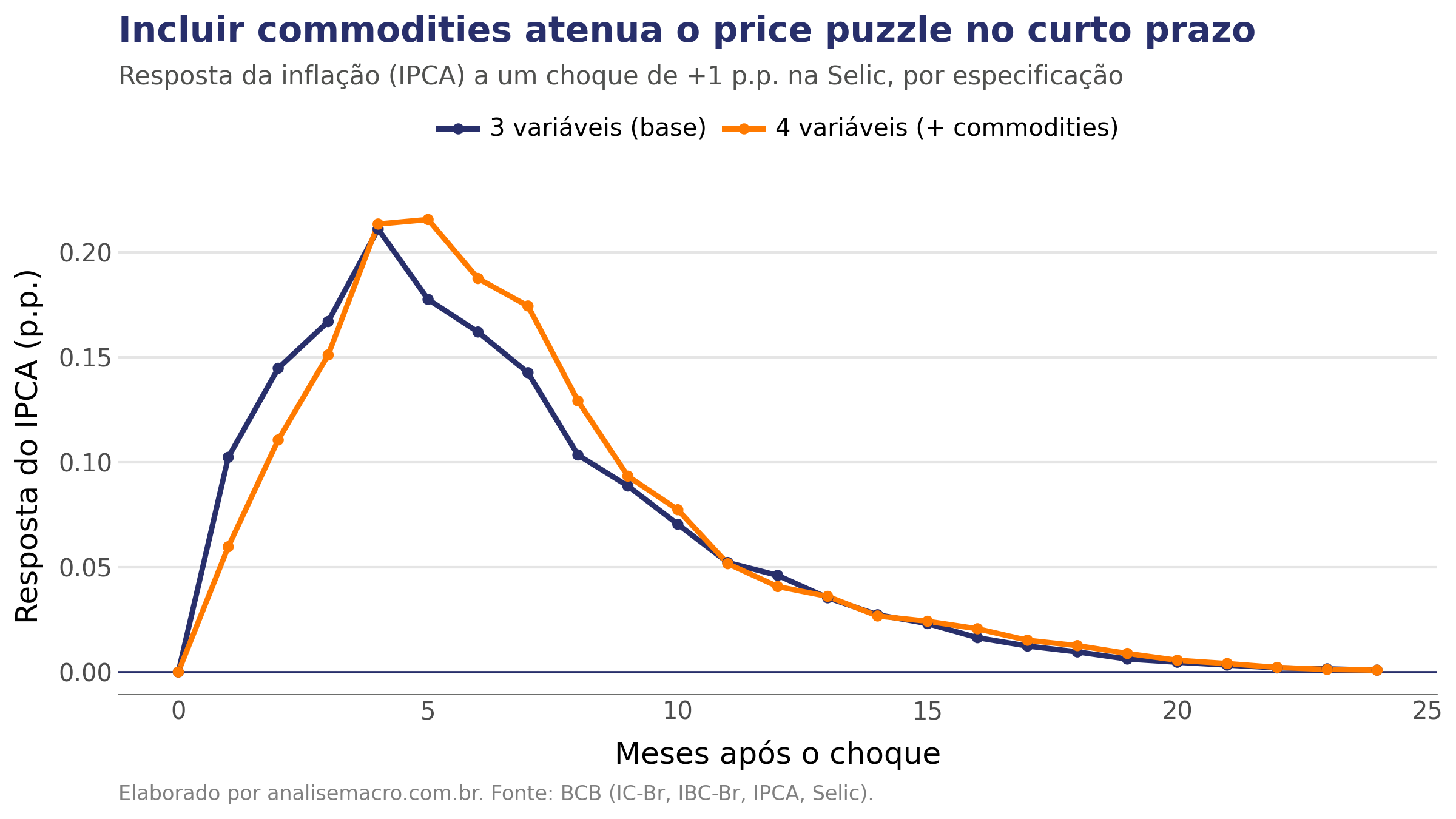
Incluir commodities atenua o puzzle nos dois primeiros meses: a resposta da inflação cai de +0,10 para +0,06 no primeiro mês e de +0,14 para +0,11 no segundo. Parte da alta era o choque de commodities disfarçado. O pico, porém, não desaparece nesta amostra: adicionar uma variável reduziu o puzzle, não o eliminou. Uma única série de commodities não cobre toda a informação que o Banco Central usa ao decidir.
Para ir além, a literatura aponta caminhos que fogem ao escopo de um tutorial: incluir uma medida de expectativas de inflação (como o Boletim Focus), trocar a identificação recursiva por restrições de sinal, recortar uma subamostra sem crises, ou usar métodos que dispensam a ordenação das variáveis. Cada um é um exercício em si. O que fica é a leitura certa de um impulso-resposta: ele depende sempre das hipóteses de identificação, e conhecer os limites do modelo é parte de saber usá-lo.
| Meses após o choque | 3 variáveis (p.p.) | 4 variáveis (p.p.) |
|---|---|---|
| 1 | +0,10 | +0,06 |
| 2 | +0,14 | +0,11 |
| 3 | +0,17 | +0,15 |
| 4 | +0,21 | +0,21 |
| 5 | +0,18 | +0,22 |
Resposta da inflação ao choque de juros, por modelo. A inclusão de commodities reduz o efeito nos primeiros meses. Fonte: BCB.
Quem manda na inflação: a decomposição de variância
A decomposição de variância (FEVD) responde a uma pergunta prática: de toda a incerteza sobre a inflação nos próximos meses, quanto vem de cada choque?
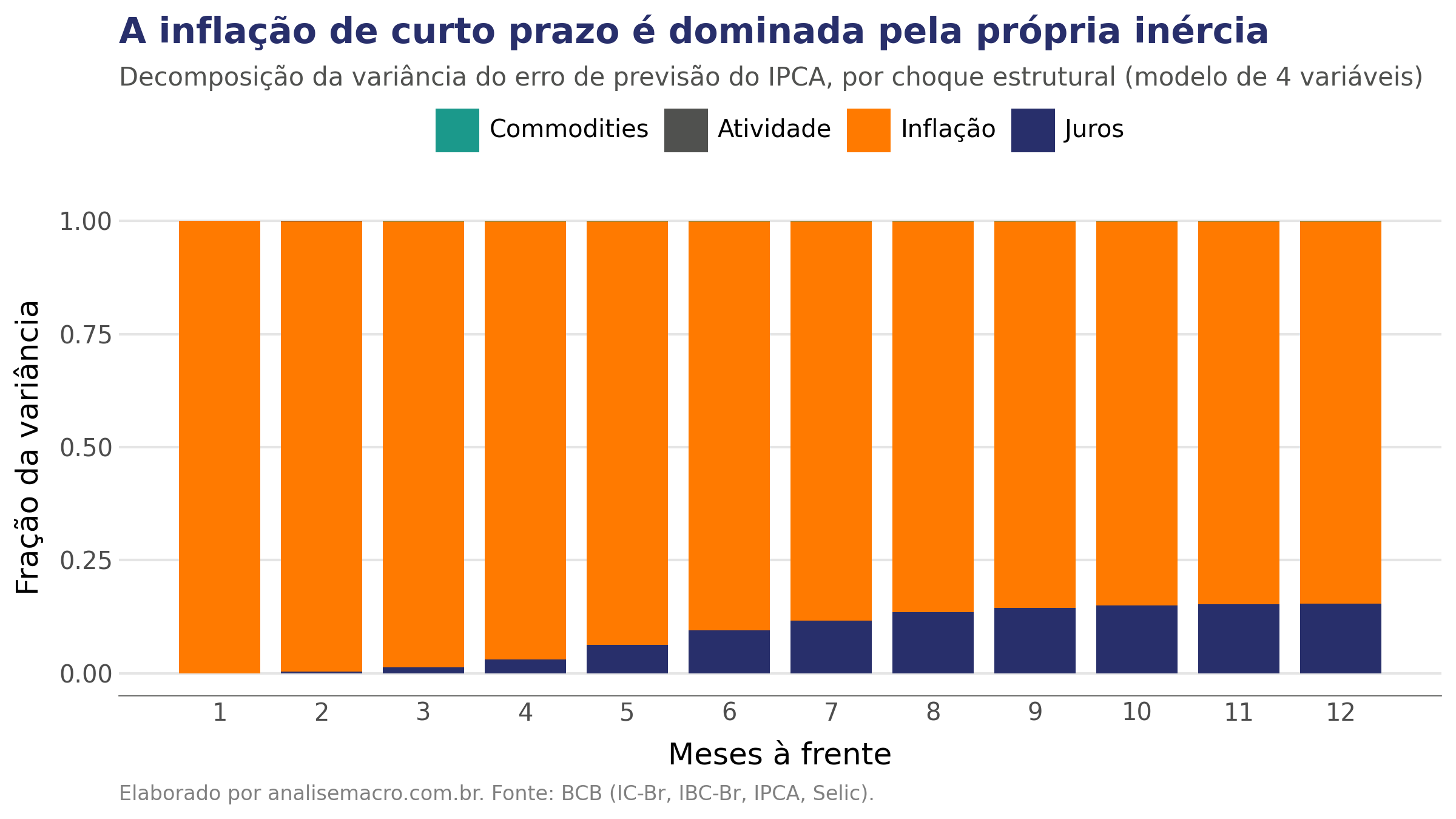
No curtíssimo prazo, a inflação é explicada quase inteiramente pela própria inércia, um traço conhecido da economia brasileira, com seus contratos e reajustes indexados. A contribuição dos juros só ganha peso com o tempo, chegando a cerca de 15% no décimo segundo mês. A política monetária importa, mas seu efeito sobre a variância da inflação se acumula, não age de imediato.
As ferramentas por trás
statsmodels traz a classe SVAR, que estima o modelo estrutural, os impulsos-resposta e os testes de diagnóstico.
Considerações finais
Este exercício mostra o que a linguagem torna possível: reproduzir, com dados públicos e poucas dezenas de linhas, uma análise de política monetária que até pouco tempo era território exclusivo de bancos centrais e departamentos de pesquisa. Mais do que isso, ensina a interpretar quando um modelo entrega um resultado estranho: o price puzzle parece um erro à primeira vista, mas revela como as hipóteses de identificação moldam tudo o que o modelo responde.
O Python é a ferramenta certa para isso porque reúne, num só lugar, a coleta dos dados, a modelagem econométrica e a visualização, com bibliotecas maduras para séries temporais e acesso direto às fontes brasileiras. O caminho que você viu aqui (coletar, testar, transformar, identificar, estimar, diagnosticar) se repete em quase todo problema de macroeconometria. O que muda é a aplicação:
- Economista e analista macro: avaliar o efeito de choques de juros, câmbio ou fiscais sobre atividade e inflação, e construir cenários.
- Analista de investimentos e estrategista: antecipar como a economia reage a decisões do Copom e posicionar carteiras conforme o ciclo.
- Gestor de risco e atuário: modelar a dinâmica conjunta de variáveis macro para estressar cenários e projetar passivos.
- Pesquisador e servidor público: testar hipóteses de política econômica com evidência empírica e dados oficiais.
Dominar a linguagem abre a porta para todas essas frentes.
Você viu como funciona. Aprenda a construir.
Modelos VAR e SVAR, séries temporais e análise de política monetária com dados brasileiros são parte da Formação em Análise Macroeconômica da Análise Macro, que parte da teoria e chega à aplicação com dados reais. Quem quer acesso a todas as formações tem o AM Black, a assinatura anual.
Referências
- Blanchard, O. J.; Quah, D. (1989). The Dynamic Effects of Aggregate Demand and Supply Disturbances. American Economic Review, 79(4), 655–673.
- Sims, C. A. (1992). Interpreting the macroeconomic time series facts: The effects of monetary policy. European Economic Review, 36(5), 975–1000.
- Lütkepohl, H. (2005). New Introduction to Multiple Time Series Analysis. Springer.
- Uhlig, H. (2005). What are the effects of monetary policy on output? Results from an agnostic identification procedure. Journal of Monetary Economics, 52(2), 381–419.
- Enders, W. (2014). Applied Econometric Time Series. 4ª ed. Wiley.
- Documentação do statsmodels — Vector Autoregressions.
Leia também:

