A combinação de grandes modelos de linguagem (LLMs) com métodos de recuperação de informações (RAG) tem sido um divisor de águas
na utilização prática da inteligência artificial. Essa arquitetura permite que modelos, em vez de dependerem apenas de seu treinamento
estático, complementem respostas com documentos externos, tornando-as mais precisas e atualizadas.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Entretanto, o RAG tradicional segue um fluxo fixo: toda pergunta gera um processo de recuperação e posterior resposta. Esse mecanismo,
embora poderoso, apresenta limitações em termos de eficiência, custo computacional e adequação da resposta.
É nesse contexto que surge o Adaptive RAG (A-RAG), uma proposta que incorpora adaptação dinâmica no processo de recuperação,
otimizando recursos e elevando a qualidade das respostas.
Arquitetura do Adaptive RAG
A lógica do Adaptive RAG parte de uma premissa simples: nem todas as perguntas exigem o mesmo nível de recuperação. Assim, a
arquitetura introduz duas camadas adicionais sobre o RAG tradicional:
-
Classificação da complexidade da consulta
O sistema avalia a query de entrada e decide se ela é simples, moderada ou complexa.
Esse classificador pode ser implementado por meio de modelos leves ou heurísticas baseadas em embeddings, comprimento da
query e natureza semântica. -
Seleção adaptativa da estratégia de recuperação
-
No retrieval: consultas simples podem ser respondidas diretamente pelo LLM.
-
Single-step retrieval: perguntas moderadas são resolvidas com uma busca pontual em documentos relevantes.
-
Multi-step retrieval: para consultas complexas, aplica-se um processo iterativo de recuperação e combinação de informações
até alcançar uma resposta satisfatória.
-
O ciclo pode ser resumido como: Query → Classificação → Estratégia de Recuperação → Geração da Resposta.
Para saber mais sobre Adaptive RAG, acesse o artigo em Adaptive RAG.
O Adaptive RAG conecta-se a outras inovações recentes:
-
Self-Reflective RAG: onde o modelo revisa e avalia suas próprias respostas antes de entregá-las.
-
CRAG (Corrective RAG): que introduz mecanismos de correção automática da recuperação.
-
Graph-RAG: onde a recuperação é estruturada em forma de grafos, ideal para relacionamentos complexos.
Comparação: RAG Tradicional vs. Adaptive RAG
| Característica | RAG Tradicional | Adaptive RAG |
|---|---|---|
| Estratégia de recuperação | Sempre a mesma | Adaptativa conforme a complexidade da query |
| Eficiência | Busca sempre executada, mesmo sem necessidade | Evita buscas desnecessárias, reduzindo custos |
| Tempo de resposta | Pode ser elevado em perguntas simples | Responde rápido quando não há necessidade de busca |
| Qualidade da resposta | Homogênea, mas por vezes redundante | Ajustada ao contexto: simples, precisa ou complexa |
Exemplos de aplicação do Adaptive RAG
-
Consulta simples
-
Query: “Qual é a taxa Selic atual?”
-
Fluxo: O modelo acessa seu conhecimento interno (ou API de tempo real) e responde imediatamente, sem recuperação extensa.
-
-
Consulta moderada
-
Query: “Qual foi o impacto da taxa Selic em 2016 sobre o PIB?”
-
Fluxo: O sistema realiza uma recuperação pontual em relatórios do BCB e estudos acadêmicos, sintetizando em resposta direta.
-
-
Consulta complexa
-
Query: “Como a crise de 2008 afetou a economia brasileira e quais políticas monetárias e fiscais foram implementadas como
resposta?” -
Fluxo: O modelo ativa recuperação multi-etapas: busca relatórios históricos, dados de séries temporais (PIB, juros, crédito),
literatura econômica, e integra as fontes em uma análise detalhada.
-
Implicações para a Análise Econômica e Financeira
O Adaptive RAG oferece ganhos significativos para aplicações em economia e finanças:
-
Relatórios automatizados: permite gerar textos dinâmicos que equilibram eficiência (indicadores simples) e profundidade (análises de
políticas e choques externos). -
Pesquisa acadêmica: acelera revisões de literatura, adaptando a estratégia de busca conforme a complexidade da pergunta do
pesquisador.
Aplicação em Python com Adaptive RAG e LangGraph
A aplicação foi construída em Python utilizando as bibliotecas LangChain, LangGraph e ChromaDB, com foco em textos econômicos – especificamente, as atas do COPOM publicadas pelo Banco Central. O objetivo foi implementar um Adaptive RAG capaz de decidir dinamicamente entre usar documentos internos (vectorstore) ou realizar buscas externas (web search).
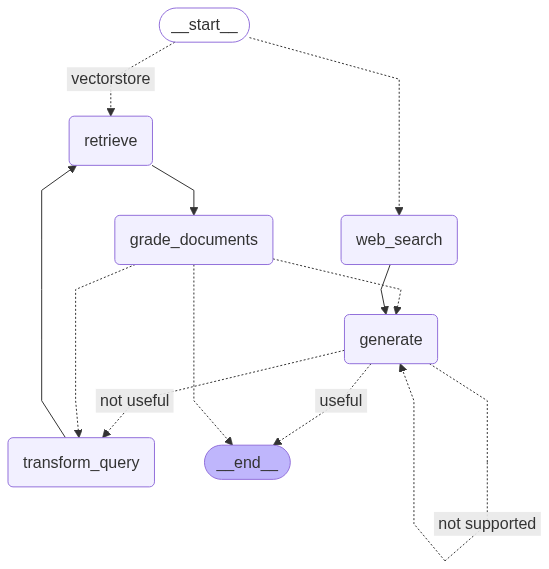
Etapas da implementação do Adaptive RAG
-
Coleta e processamento de dados
-
As atas mais recentes do COPOM foram baixadas diretamente da API do Banco Central.
-
Os PDFs foram processados com
PyPDFLoader, transformados em objetosDocumente armazenados em uma base vetorial. -
Cada ata foi dividida em chunks de 2.000 caracteres com sobreposição de 200, preservando o contexto.
-
-
Construção da base vetorial
-
Os textos processados foram transformados em embeddings usando o modelo GoogleGenerativeAIEmbeddings.
-
A indexação foi feita com ChromaDB, permitindo recuperação eficiente baseada em similaridade semântica.
-
Um retriever foi criado com busca MMR (Maximal Marginal Relevance) para equilibrar relevância e diversidade dos trechos retornados.
-
-
Configuração do LLM
-
Foi utilizado o modelo Gemini 2.0 Flash, integrado via
ChatGoogleGenerativeAI, configurado com temperatura zero para garantir respostas determinísticas.
-
-
Adaptive RAG com LangGraph
O fluxo adaptativo foi montado como um grafo de estados, no qual cada nó representa uma etapa do processo:-
Route Question: decide se a query deve ser respondida pelo vectorstore ou via busca na web (DuckDuckGo).
-
Retrieve: busca documentos relevantes na base vetorial.
-
Grade Documents: filtra documentos avaliando sua relevância em relação à pergunta.
-
Transform Query: reformula a pergunta caso nenhum documento relevante seja encontrado.
-
Generate: gera a resposta com base no contexto recuperado.
-
Grade Generation: avalia se a resposta está fundamentada nos documentos e se atende à pergunta, evitando alucinações.
Caso a geração não seja satisfatória, o grafo redireciona o fluxo para nova reformulação ou nova busca, até produzir uma resposta consistente.
-
-
Exemplo de execução
Ao perguntar: “Qual foi a avaliação do COPOM em julho de 2025 sobre o cenário inflacionário global?”, o sistema:-
Classificou a query como dependente de documentos externos.
-
Recuperou atas e notícias relevantes sobre a reunião de julho.
-
Filtrou trechos específicos sobre o cenário internacional.
-
Gerou uma resposta concisa: “O Copom avaliou que o cenário externo estava mais adverso e incerto.”
-
Considerações Finais
A aplicação demonstra como o Adaptive RAG pode ser implementado de forma prática para textos econômicos, ajustando dinamicamente o processo de recuperação conforme a complexidade da pergunta. Isso permite respostas rápidas em consultas simples e análises detalhadas em investigações complexas, equilibrando eficiência computacional e profundidade analítica.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

