Introdução
Se você acompanha o mundo da inteligência artificial, provavelmente já ouviu falar dos Transformers. Essa arquitetura, que surgiu no campo do Processamento de Linguagem Natural (NLP), não só revolucionou a forma como as máquinas entendem e geram texto, mas também está, silenciosamente, redefinindo os limites da análise de áreas como finanças e economia.
Para obter o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Objetivo
Nosso objetivo é que, ao final da leitura, você tenha uma compreensão clara e prática sobre o tema:
- Uma Explicação Didática sobre Transformers: Vamos desmontar a arquitetura do zero, explicando conceitos como self-attention, positional encoding e a estrutura de encoder-decoder de uma forma intuitiva.
O que é o Transformer?
Introdução
O Transformer foi introduzido em 2017 por pesquisadores do Google no famoso artigo “Attention Is All You Need”. Sua proposta era radical: substituir completamente as camadas de recorrência (o “coração” das LSTMs) por um mecanismo chamado auto-atenção (self-attention). A arquitetura foi originalmente projetada para tradução automática e é composta por duas partes principais: o Encoder e o Decoder.
Encoder (Codificador)
Pense no Encoder como o “leitor” do modelo. Sua função é processar toda a sequência de entrada (seja uma frase em português ou uma série de dados de inflação) e construir uma representação numérica rica em contexto para cada ponto da sequência. Ele lê a frase inteira para entender as relações entre todas as palavras antes de passar a informação adiante.
Decoder (Decodificador)
O Decoder é o “escritor”. Ele recebe a representação contextualizada do Encoder e gera a sequência de saída, um item de cada vez. No caso da tradução, ele gera a frase em outro idioma, palavra por palavra. Para séries temporais, ele gera a previsão, ponto a ponto no futuro.
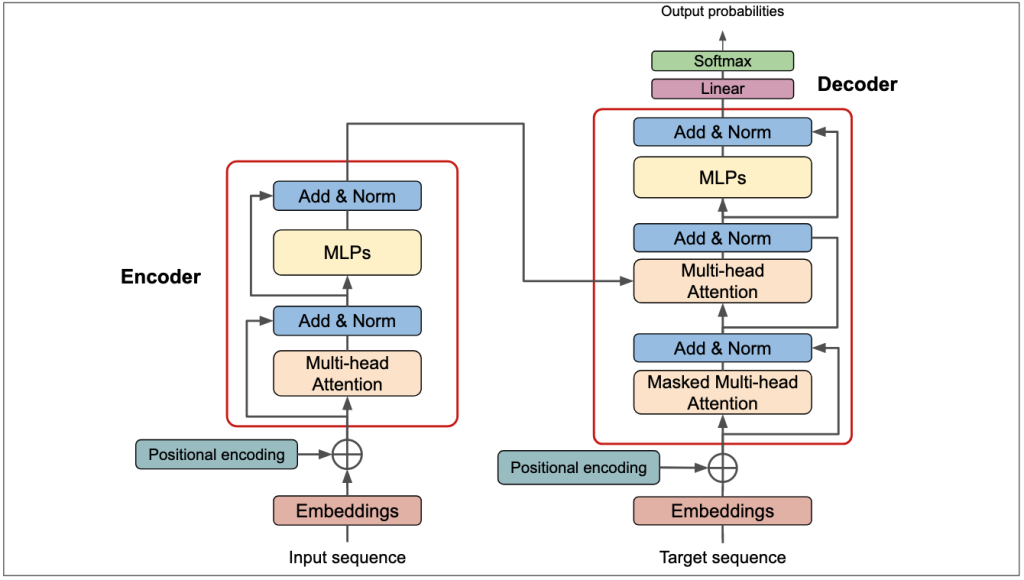
Enconder-Decoder
A imagem abaixo demonstra o funcionamento completo da arquitetura do Transformer, separando os blocos do Encoder e Decoder.
A Arquitetura do Transformer
Esses modelos são compostos por uma série de blocos Transformer, que se repetem diversas vezes — desde cerca de seis blocos no artigo original de Vaswani et al. (2017), até mais de cem em grandes modelos modernos. Cada bloco recebe uma entrada, realiza o processamento das informações e passa o resultado para o próximo bloco, formando uma cadeia de camadas empilhadas.
A primeira etapa do processo envolve a tokenização e a criação dos embeddings. Nessa fase, o texto é dividido em pequenas unidades chamadas tokens (palavras ou pedaços de palavras), que são convertidas em vetores numéricos. Esse passo é fundamental para que a máquina consiga “ler” e representar a linguagem humana em formato matemático.
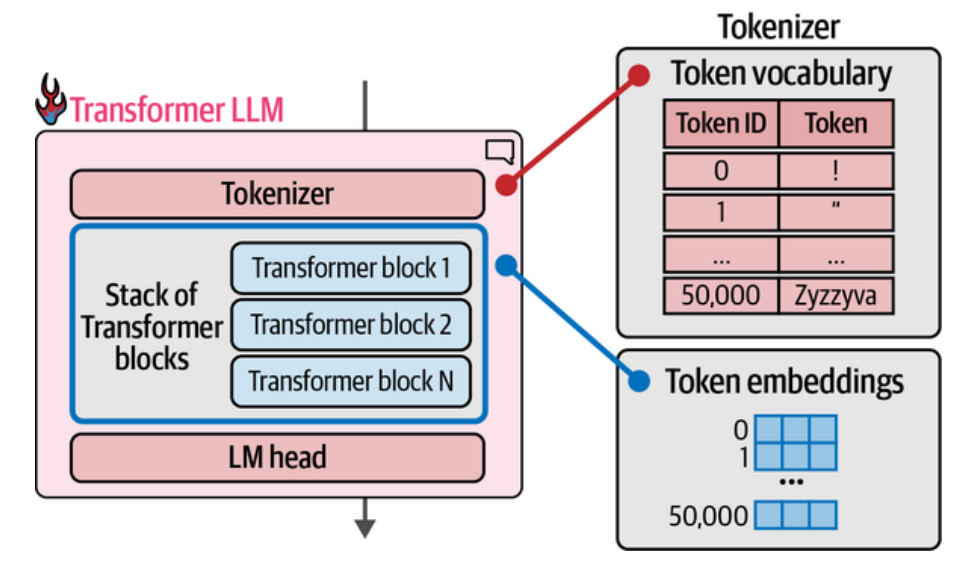
Em seguida, cada bloco Transformer é composto por dois componentes principais:
- Camada de Atenção (Attention Layer)
Essa camada é responsável por identificar e incorporar informações relevantes de outros tokens na sequência. Em outras palavras, ela permite que o modelo entenda quais palavras estão relacionadas entre si, mesmo que distantes no texto. É nessa etapa que o modelo “presta atenção” nas partes mais importantes do contexto. - Camada Feedforward (Feedforward Layer ou MLPs)
Após o mecanismo de atenção, os vetores passam por uma rede neural do tipo MLP (Multi-Layer Perceptron). Essa é a parte onde ocorre a maior capacidade de processamento do modelo, responsável por combinar, transformar e refinar as representações numéricas criadas pela atenção.
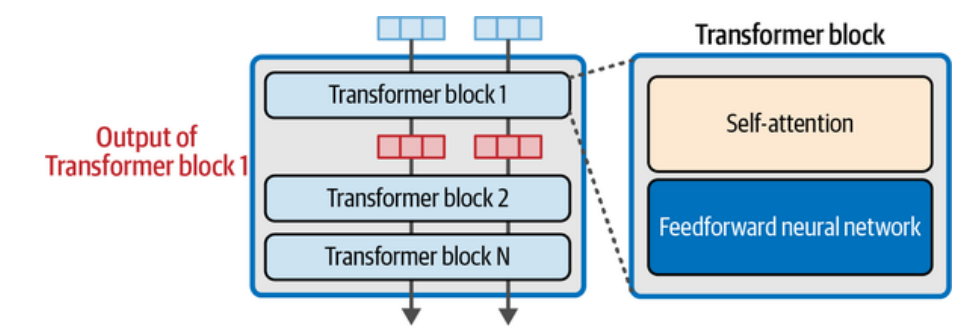
Por fim, após passarem por todos os blocos e suas transformações, os vetores numéricos finais (output vectors) são enviados ao LM Head (Language Model Head) — uma camada de saída que converte esses vetores em probabilidades sobre o próximo token da sequência, gerando assim o texto final.
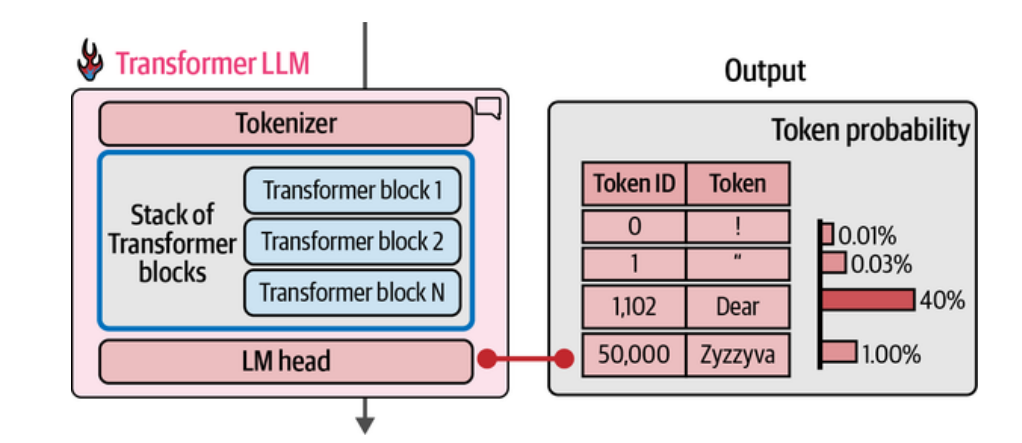
1. Tokenização e Embedding
Tudo começa com a entrada de dados (input sequence), seja um texto, uma sequência de preços ou um áudio. O modelo precisa converter isso em algo que ele entenda — números.
- Tokenização é o primeiro passo. No caso de textos, o modelo quebra as frases em pequenas unidades chamadas tokens — que podem ser palavras, subpalavras ou até caracteres. Já em séries temporais, cada observação em um ponto no tempo (como o preço de fechamento diário de uma ação) funciona como um token.
- Embedding vem em seguida. Cada token é transformado em um vetor numérico de alta dimensão, o chamado embedding. Esse vetor captura as relações semânticas (no caso de texto) ou as características estatísticas (no caso de séries). Por exemplo, embeddings próximos no espaço vetorial indicam tokens que possuem significados semelhantes ou comportamentos parecidos.
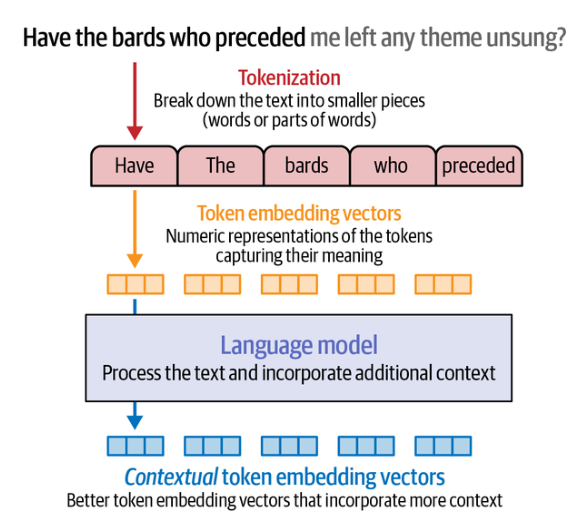
A imagem acima mostra o processo de tokenização e embedding: o texto “Have The Bards who Preceded” é separado em cinco tokens, nesse caso, em um padrão de separação por palavra (método de tokenização por Word).
Em seguida, é passado pela fase de embedding, e é transformado em cinco vetores distintos, cada um representando um token. São esses vetores que são passaos pelo modelos de linguagem, que processa o texto e incorpora contexto adicional para produzir a previsão dos próximos Tokens (aqui, uma sequência de palavras).
No caso de séries temporais, imagine um gráfico de preços diários onde cada ponto é convertido em um vetor que codifica não só o valor, mas também o contexto da série.
2. Self-Attention
Depois que cada token é convertido em um vetor, o modelo precisa entender como cada um se relaciona com os outros. É nesse ponto que entra o mecanismo de atenção (attention mechanism) — o verdadeiro núcleo do Transformer.
O self-attention permite que o modelo observe todos os tokens de uma sequência simultaneamente e identifique quais são mais importantes para compreender o contexto de cada um.
Considere o exemplo:
“The dog chased the squirrel because it…”
Para prever o que vem depois de “it”, o modelo precisa saber a quem esse pronome se refere: ao dog ou ao squirrel?
O mecanismo de atenção resolve essa ambiguidade ao incorporar informações contextuais diretamente na representação do token “it”. O modelo faz isso com base nos padrões aprendidos durante o treinamento. Se, em frases anteriores, o texto se referiu ao cachorro como “she”, por exemplo, o modelo pode inferir que “it” se refere ao squirrel.
Visualmente, o mecanismo de atenção mostra várias posições de tokens sendo processadas, e a posição atual (marcada pela seta rosa) recebe informações relevantes do restante do contexto. Ele combina essas informações para gerar um novo vetor de saída que representa melhor o significado daquele token no contexto da frase.
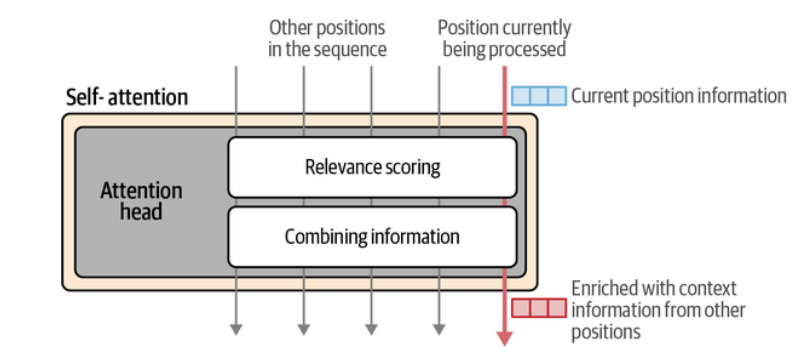
O funcionamento da atenção envolve duas etapas principais:
- Atribuir pesos de relevância a cada token anterior em relação ao token atual;
- Combinar as informações ponderadas desses tokens para formar um novo vetor de saída.
Para ampliar essa capacidade, o Transformer executa várias atenções em paralelo — um processo chamado de multi-head attention. Cada head aprende a capturar padrões diferentes do texto, como dependências gramaticais, relações semânticas ou referências a longo prazo. Isso permite que o modelo compreenda aspectos distintos da mesma sequência simultaneamente.
Dentro de uma attention head, o cálculo começa com a criação de três vetores derivados de cada embedding:
- Query (Q) – representa o token que “pergunta” quais outros tokens são relevantes para ele;
- Key (K) – descreve o conteúdo de cada token, como se dissesse “eu represento esta informação”;
- Value (V) – contém a informação que será usada caso a Key seja considerada relevante.
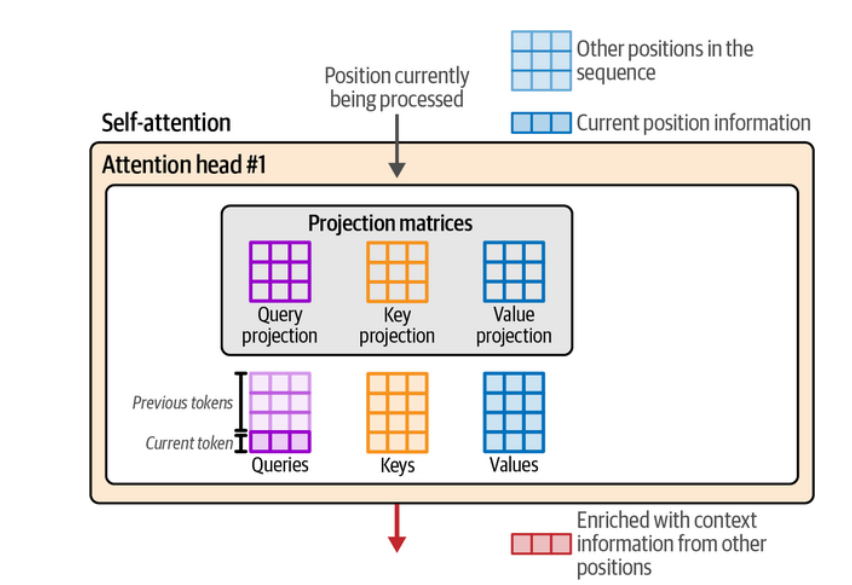
Esses três vetores projetam os tokens para diferentes espaços vetoriais, permitindo realizar as duas etapas do mecanismo de atenção: medir relevância e combinar informações. A partir deles, o modelo calcula a atenção para o token atual (a última linha das matrizes), levando em conta todas as posições anteriores, e produz uma nova representação contextualizada.
O cálculo da atenção é feito em duas etapas principais.
Primeiro, o modelo mede quanto cada token deve prestar atenção aos outros, comparando Queries e Keys. Isso é feito multiplicando Q por K transposta:

Essas pontuações indicam o grau de relação entre os tokens.
Por exemplo, se o token atual for “gato”, ele pode ter alta pontuação com “dorme” e baixa com “o”.\
Para evitar valores excessivamente grandes, o resultado é escalonado pela raiz quadrada da dimensão dos vetores de Key  :
:

Em seguida, aplica-se a função Softmax para transformar essas pontuações em pesos normalizados, que somam 1:

Esses pesos determinam a importância de cada token para o token atual.
Quanto maior o valor, mais relevante é o token no contexto da sequência.
Por fim, o modelo multiplica esses pesos pelos vetores Value (V), combinando as informações ponderadas e produzindo uma nova representação contextualizada:

O resultado é um vetor que carrega não apenas o significado original do token, mas também o contexto fornecido pelos outros tokens da sequência.
3. Positional Encoding
Um problema do self-attention é que ele não entende a ordem natural dos tokens. Para o modelo, “o gato dorme” e “dorme o gato” são tecnicamente a mesma coisa, pois a relação de atenção entre as palavras é a mesma. Isso acontece porque o mecanismo de atenção, por si só, é invariante à posição — ele apenas mede relações entre tokens, sem saber onde cada um está na sequência.
Para resolver esse problema, o Transformer adiciona o Positional Encoding (PE), um vetor que representa a posição de cada token na sequência. Esses vetores são somados diretamente aos embeddings das palavras antes de entrarem no mecanismo de atenção, de modo que cada posição carregue uma assinatura numérica única.
Esses valores de posição não são aprendidos, mas gerados por funções matemáticas periódicas — seno e cosseno — que criam padrões regulares e diferentes para cada índice da sequência. O cálculo é feito da seguinte forma:
 \
\

onde  indica a posição do token na sequência,
indica a posição do token na sequência,  é o índice da dimensão do embedding e
é o índice da dimensão do embedding e  é o tamanho total do vetor de embedding.
é o tamanho total do vetor de embedding.
As dimensões pares usam seno, e as ímpares usam cosseno.

A figura ilustra como o Positional Encoding (PE) é calculado e aplicado a cada token de uma sequência de entrada, como na frase “I am enjoying this tutorial”.
Cada palavra é associada a um vetor de posição ( , que é obtido aplicando funções seno e cosseno em diferentes frequências. Essas funções são parametrizadas pela posição do token () e pela dimensão do embedding (), criando valores periódicos e únicos para cada posição.
, que é obtido aplicando funções seno e cosseno em diferentes frequências. Essas funções são parametrizadas pela posição do token () e pela dimensão do embedding (), criando valores periódicos e únicos para cada posição.
Dessa forma, cada vetor posicional carrega informações que permitem ao modelo distinguir a posição relativa das palavras — algo que o self-attention, sozinho, não consegue fazer.
O quadro vermelho mostra o cálculo detalhado dessas posições.
Para cada dimensão par do vetor, aplica-se a função seno, e para cada dimensão ímpar, a função cosseno.
No exemplo, o vetor de posição  , correspondente à palavra enjoying, é formado pelos valores (
, correspondente à palavra enjoying, é formado pelos valores ( ).
).
Essa combinação gera um padrão numérico contínuo e distinto para cada token, permitindo que o modelo reconheça tanto a identidade da palavra (via embedding) quanto sua posição na sequência (via PE).
Quando esses vetores são somados aos embeddings originais, o Transformer passa a compreender não apenas o significado das palavras, mas também a estrutura sequencial da frase.
4. Feed-Forward Network
Após as camadas de atenção e codificação posicional, cada token passa por uma rede neural feed-forward, aplicada individualmente a cada posição.
Essa etapa é responsável por transformar as representações produzidas pela atenção em informações mais abstratas e não lineares. Ela ajuda o modelo a captar padrões complexos e a ajustar as relações aprendidas nas camadas anteriores.
É como se, depois de olhar o contexto global, o modelo refinasse localmente o entendimento de cada token — adicionando nuances e captando interações sutis.
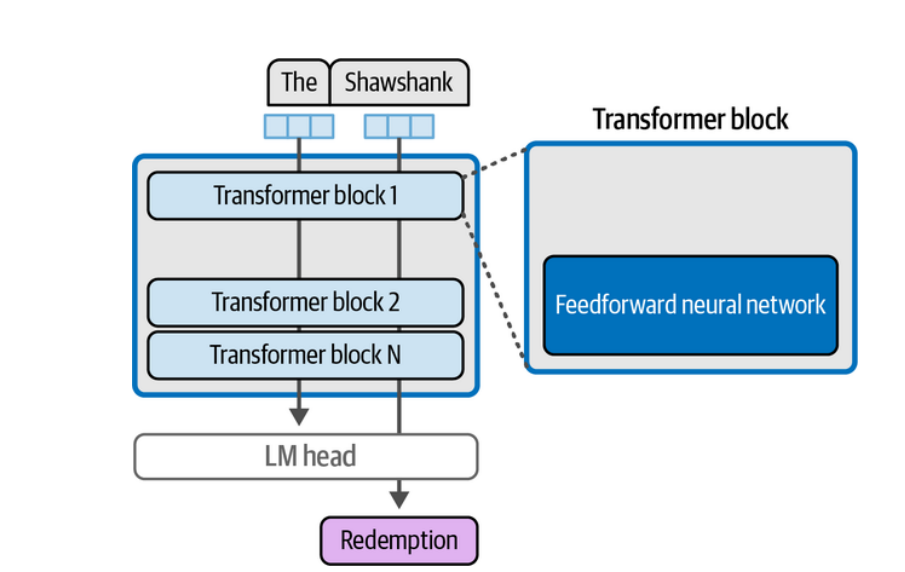
Por exemplo, ao receber a entrada “The Shawshank”, espera-se que o modelo gere “Redemption” como a palavra mais provável seguinte. Essa capacidade vem justamente das redes feed-forward presentes em todas as camadas do modelo. Durante o treinamento em grandes volumes de texto, o modelo aprende e armazena associações desse tipo, internalizando padrões linguísticos e contextuais.
Contudo, o aprendizado não se limita à memorização. O papel fundamental dessas redes é permitir que o modelo generalize — ou seja, consiga reconhecer e gerar respostas coerentes mesmo para sequências que não estavam presentes em seu conjunto de treinamento.
5. Multi-Head Attention: múltiplas perspectivas, um mesmo contexto
Fazer o processo de atenção uma única vez já permite que o modelo entenda como as palavras se relacionam entre si. No entanto, a linguagem — e o mundo — são complexos demais para serem compreendidos por apenas uma “visão”. É por isso que o Transformer usa o conceito de múltiplas cabeças de atenção (multi-head attention).
Cada cabeça funciona como um especialista observando a mesma frase sob um ângulo diferente.
Por exemplo:
- uma cabeça pode focar em relações de curto prazo, como “o gato” → “dorme”;
- outra pode buscar relações de longo prazo, como “ela” → “Maria”, mesmo que as palavras estejam distantes na frase.
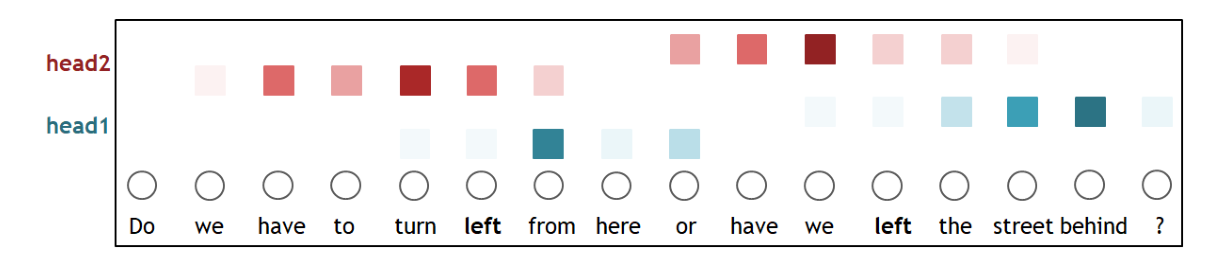
A imagem acima mostra duas cabeças de atenção operando sobre a mesma frase. Cada cor representa uma cabeça focada em um tipo de relação e os pesos que elas dão a determinado token, que no caso da imagem, é representado por “left”. Juntas, elas constroem uma compreensão multidimensional do contexto.
As cabeças processam a sequência em paralelo, cada uma com seu próprio conjunto de parâmetros — as chamadas matrizes de Query (Q), Key (K) e Value (V). Isso significa que cada cabeça aprende a olhar para diferentes tipos de conexões entre os tokens.
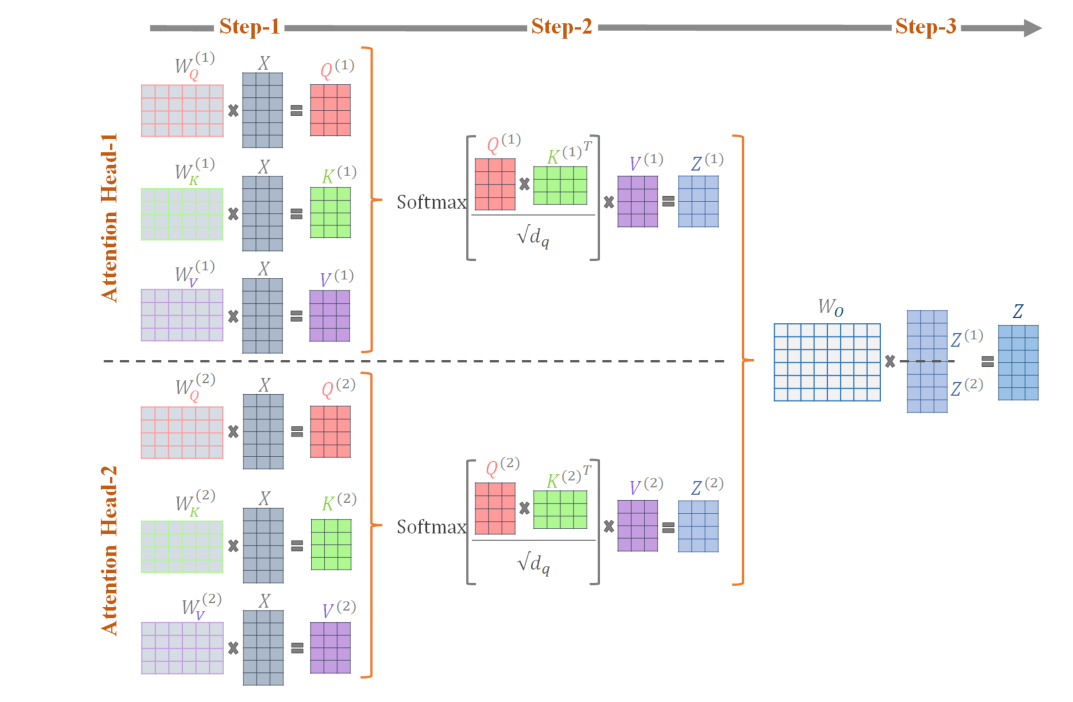
Matematicamente, o processo ocorre em três etapas principais:
- Geração dos vetores Q, K e V para cada cabeça
Se o modelo tiver, por exemplo, 8 cabeças, ele criará 8 conjuntos diferentes de matrizes de pesos ( ). Cada conjunto gera vetores de consulta (Q), chave (K) e valor (V) distintos para os mesmos tokens de entrada.
). Cada conjunto gera vetores de consulta (Q), chave (K) e valor (V) distintos para os mesmos tokens de entrada. - Cálculo da atenção em paralelo
Cada cabeça aplica a fórmula de self-attention separadamente: Essa etapa calcula quanto cada token deve “olhar” para os outros, resultando em diferentes representações contextuais — uma por cabeça.
Essa etapa calcula quanto cada token deve “olhar” para os outros, resultando em diferentes representações contextuais — uma por cabeça. - Combinação das saídas
Depois que cada cabeça gera sua saída, todas são concatenadas e combinadas linearmente por uma nova matriz de pesos ( ).
).
O resultado é um vetor que reúne várias perspectivas sobre o mesmo texto, mantendo a mesma dimensão da entrada.
 ). Cada conjunto gera vetores de consulta (Q), chave (K) e valor (V) distintos para os mesmos tokens de entrada.
). Cada conjunto gera vetores de consulta (Q), chave (K) e valor (V) distintos para os mesmos tokens de entrada. Essa etapa calcula quanto cada token deve “olhar” para os outros, resultando em diferentes representações contextuais — uma por cabeça.
Essa etapa calcula quanto cada token deve “olhar” para os outros, resultando em diferentes representações contextuais — uma por cabeça. ).
).
Essa arquitetura permite que o Transformer capture simultaneamente diferentes tipos de dependências — sintáticas, semânticas e de contexto mais amplo. É um pouco como em uma rede neural convolucional (CNN), onde cada filtro aprende a detectar um tipo diferente de padrão.
No caso do Transformer, cada cabeça de atenção aprende um padrão diferente nas relações entre palavras. Por isso, quando todas trabalham juntas, o modelo constrói uma compreensão muito mais rica e profunda do contexto, essencial para gerar texto coerente, traduzir frases ou responder perguntas de forma precisa.
Conectando Tudo: O Fluxo de Dados no Transformer
Agora que conhecemos as peças, vamos montar o quebra-cabeça. A imagem mostra a arquitetura completa do Transformer. Vamos seguir o fluxo de dados da entrada à saída.
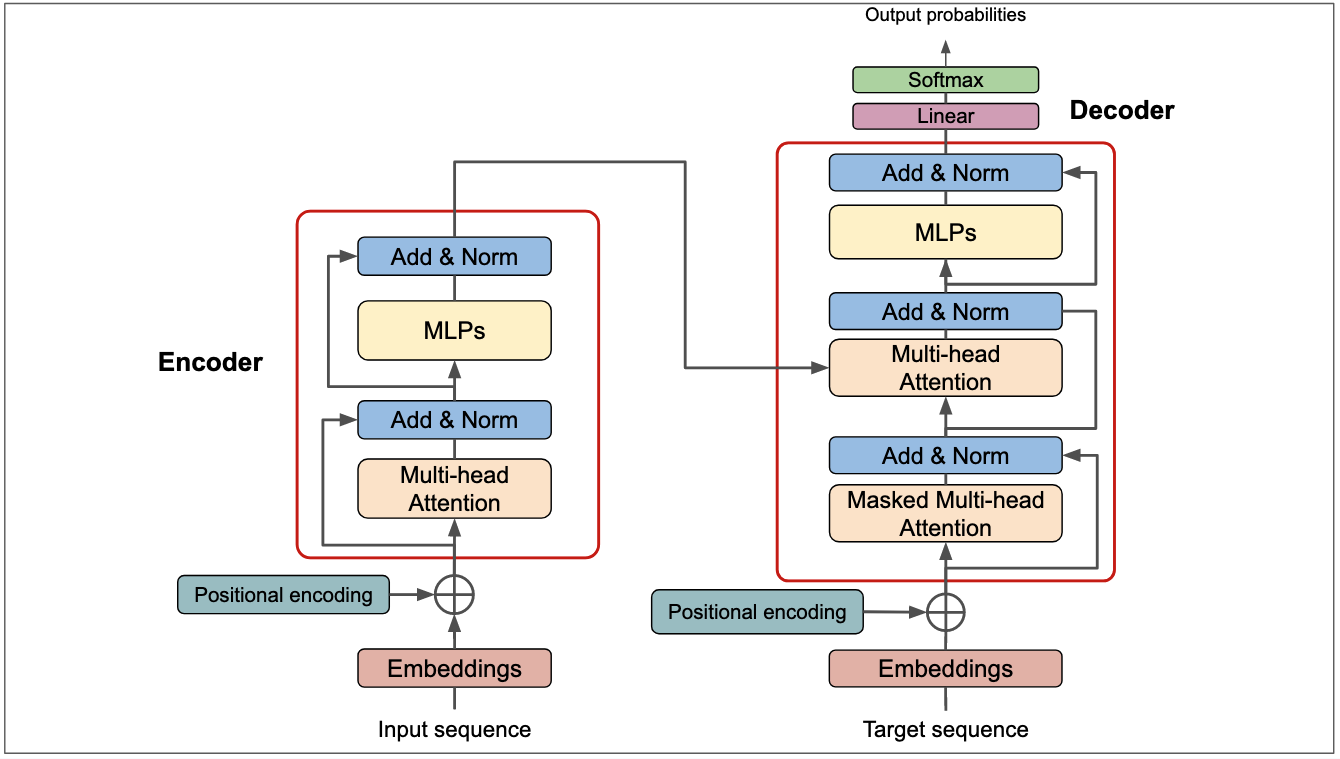
O Lado do Encoder (O Leitor)
A função do Encoder é ler a sequência de entrada e criar uma representação rica em contexto.
- Entrada: A Input sequence é convertida em Embeddings e somada ao Positional Encoding para adicionar o contexto de ordem.
- Atenção e Processamento: O resultado passa por um bloco que contém:
- Uma camada de Multi-Head Attention para que os tokens troquem informações entre si.
- Uma camada Add & Norm. O “Add” é uma conexão residual (soma da entrada com a saída da atenção) que estabiliza o treinamento. O “Norm” é uma normalização de camada que mantém os valores em uma escala controlada.
- Uma rede Feed-Forward (MLPs) para processamento adicional.
- Outra camada Add & Norm para finalizar o bloco.
Este bloco pode ser empilhado várias vezes. A saída final do Encoder é uma memória contextualizada de toda a entrada, que é enviada ao Decoder na forma dos vetores Key (K) e Value (V).
O Lado do Decoder (O Escritor)
A função do Decoder é gerar a sequência de saída, um token por vez, usando o contexto do Encoder.
- Entrada: O Decoder recebe a Target sequence (a saída esperada), que também passa por Embeddings e Positional Encoding.
- Atenção Mascarada: A primeira camada de atenção é uma Masked Multi-Head Attention. A “máscara” impede que o modelo espie os tokens futuros da sequência ao prever o token atual, garantindo que ele não “trapaceie”.
- Atenção Encoder-Decoder: Após uma camada Add & Norm, vem o passo crucial. Uma segunda camada de Multi-Head Attention recebe:
- Query (Q) do próprio Decoder.
- Key (K) e Value (V) da saída do Encoder. É aqui que o Decoder consulta a memória da entrada para decidir qual token gerar.
- Processamento Final: O restante do bloco é igual ao do Encoder: uma camada Add & Norm, uma rede Feed-Forward (MLPs) e uma última camada Add & Norm.
A Saída Final
- Linear: A saída do último bloco Decoder passa por uma camada Linear, que a transforma em um grande vetor de scores, um para cada palavra possível no vocabulário.
- Softmax: A função Softmax converte esses scores em probabilidades.
O token com a maior probabilidade é escolhido como a previsão final do modelo, e o processo se repete para gerar o próximo token.
Transformers em Séries Temporais: Como é Possível?
A transição dos Transformers do texto para as séries temporais é conceitualmente direta. Em NLP, um Transformer trata cada palavra (ou “token”) em uma frase como uma unidade. Em uma série temporal, cada observação (ex: o valor diário do câmbio) é tratada como um “token”.
A sequência de valores ao longo do tempo se torna uma “frase”, e o Transformer aprende a gramática e o contexto dessa “frase” temporal.
# Exemplo simbólico: sequência temporal como "frases"
# Cada valor é um "token" que o Transformer analisa em relação aos outros.
serie_juros = [12.50, 12.75, 13.25, 13.75, 13.75, 13.25, 12.75]
# O Transformer pode aprender que a primeira ocorrência de 12.75,
# mesmo distante, é um forte indicador para a ocorrência futura de 13.25,
# ignorando os valores intermediários se não forem relevantes.Adaptar uma arquitetura de texto para números ordenados no tempo parece um salto, mas a analogia é direta: uma série temporal é tratada como uma frase, onde cada observação é uma palavra. No entanto, essa adaptação traz desafios, vantagens e desvantagens.
Os Desafios e as Soluções
- Problema: Falta de Noção de Ordem. Como mencionado, o self-attention é invariante à permutação.
- Solução: O Positional Encoding é crucial. Ele injeta a informação temporal diretamente nos dados de entrada, permitindo que o modelo aprenda a importância da ordem.
- Problema: Complexidade Quadrática. O self-attention compara cada ponto com todos os outros. Para uma série com
Npontos, isso exigeN²cálculos. Para séries temporais muito longas (milhares ou milhões de pontos), isso se torna computacionalmente inviável.- Solução: Pesquisas recentes criaram variações mais eficientes, como o Informer e o LogSparse Transformer, que usam mecanismos de atenção “esparsos”, focando apenas nos pontos mais relevantes e reduzindo drasticamente a complexidade.
- Problema: Dados Contínuos vs. Discretos. Texto é formado por tokens discretos (palavras). Séries temporais são contínuas.
- Solução: Tratamos cada ponto de observação como um token discreto e o transformamos em um embedding, permitindo que o modelo opere sobre eles da mesma forma que faria com palavras.
Vantagens
- Captura de Dependências de Longo Prazo: Esta é a maior vantagem sobre LSTMs. Um Transformer pode, teoricamente, conectar um evento de hoje (ex: uma queda na bolsa) a uma crise financeira ocorrida há vários anos, simplesmente porque o mecanismo de atenção pode criar uma ligação direta entre esses dois pontos no tempo, sem que a informação se degrade ao longo do caminho.
- Paralelização: Ao contrário das RNNs, que precisam processar os dados sequencialmente, o Transformer processa a série inteira de uma vez. Isso o torna muito mais rápido para treinar em hardware moderno (GPUs/TPUs).
- Interpretabilidade: Os mapas de atenção podem ser visualizados, permitindo entender em quais pontos do passado o modelo está “prestando mais atenção” para fazer uma previsão, o que ajuda a abrir a “caixa-preta”.
Desvantagens
- Exigência de Dados: Transformers são modelos grandes com milhões de parâmetros. Eles precisam de grandes volumes de dados para serem treinados de forma eficaz e evitar o superajuste (overfitting).
- Complexidade (fora da caixa): Como mencionado, a complexidade quadrática torna o Transformer “vanilla” inadequado para séries temporais muito longas. É necessário recorrer a variantes mais complexas e recentes.
- Menos “Viés Indutivo” para o Tempo: RNNs são construídas com a premissa de sequencialidade. Transformers não têm essa premissa e dependem inteiramente do Positional Encoding para aprender a ordem. Em conjuntos de dados menores, essa falta de um viés estrutural pode levar a um desempenho inferior.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.
Referências
AHMED, Sabeen; NIELSEN, Ian E.; TRIPATHI, Aakash; SIDDIQUI, Shamoon; RAMACHANDRAN, Ravi P.; RASOOL, Ghulam. Transformers in Time-Series Analysis: A Tutorial. Circuits, Systems, and Signal Processing, v. 42, n. 12, p. 7433-7466, 2023. Disponível em: https://researchwithrowan.com.
ALAMMAR, Jay; GROOTENDORST, Maarten. Hands-On Large Language Models: Language Understanding and Generation. Sebastopol: O’Reilly Media, 2024.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” arXiv Preprint arXiv:1706.03762.

