Este exercício visa analisar o impacto da Lei da Transparência (LAI) na mortalidade infantil em municípios brasileiros usando a linguagem de programação R. A LAI, que entrou em vigor em 2012, garante o acesso público à informação governamental, e espera-se que sua implementação tenha contribuído para a redução da mortalidade infantil.
Para investigar essa relação, utilizaremos a técnica de Regressão Descontínua (RDD), que permite estimar o efeito causal de uma intervenção (a LAI, nesse caso) ao comparar municípios que foram “tratados” (aqueles que passaram a ter acesso à informação) com aqueles que não foram “tratados” (aqueles que não foram afetados pela LAI).
Regressão Descontínua
A Regressão Descontínua é uma técnica de inferência causal que explora a descontinuidade em uma variável de tratamento para estimar o efeito de uma intervenção. No nosso caso, a variável de tratamento é a LAI, que se aplica a municípios com mais de 10.000 habitantes. A descontinuidade ocorre nesse ponto de corte, pois municípios com mais de 10.000 habitantes são “tratados” pela LAI, enquanto aqueles com menos de 10.000 habitantes não são.
A RDD estima o efeito da LAI comparando os resultados (mortalidade infantil) de municípios que estão “próximos” ao ponto de corte, tanto acima quanto abaixo dele. A ideia é que, se a LAI realmente tem um efeito causal, veremos uma diferença significativa nos resultados entre os municípios “tratados” e “não tratados” que estão próximos ao ponto de corte.
Dados
Para realizar a análise, utilizaremos dados sobre mortalidade infantil e população de municípios brasileiros nos anos de 2010 até 2014. Os dados de mortalidade infantil incluem informações sobre a causa básica da morte, o ano do óbito, o município, a idade da criança, o sexo e a raça. Os dados de população incluem informações sobre o ano, o município, o sexo, o grupo de idade e a população total.
Modelo
A função rdplot do pacote rdrobust plota a média da variável dependente (outcome) para diferentes intervalos (ou bins) da variável de running (running variable), que é a variável que determina o ponto de corte. Ela destaca visualmente o salto ou descontinuidade na variável de resultado ao redor do ponto de corte.
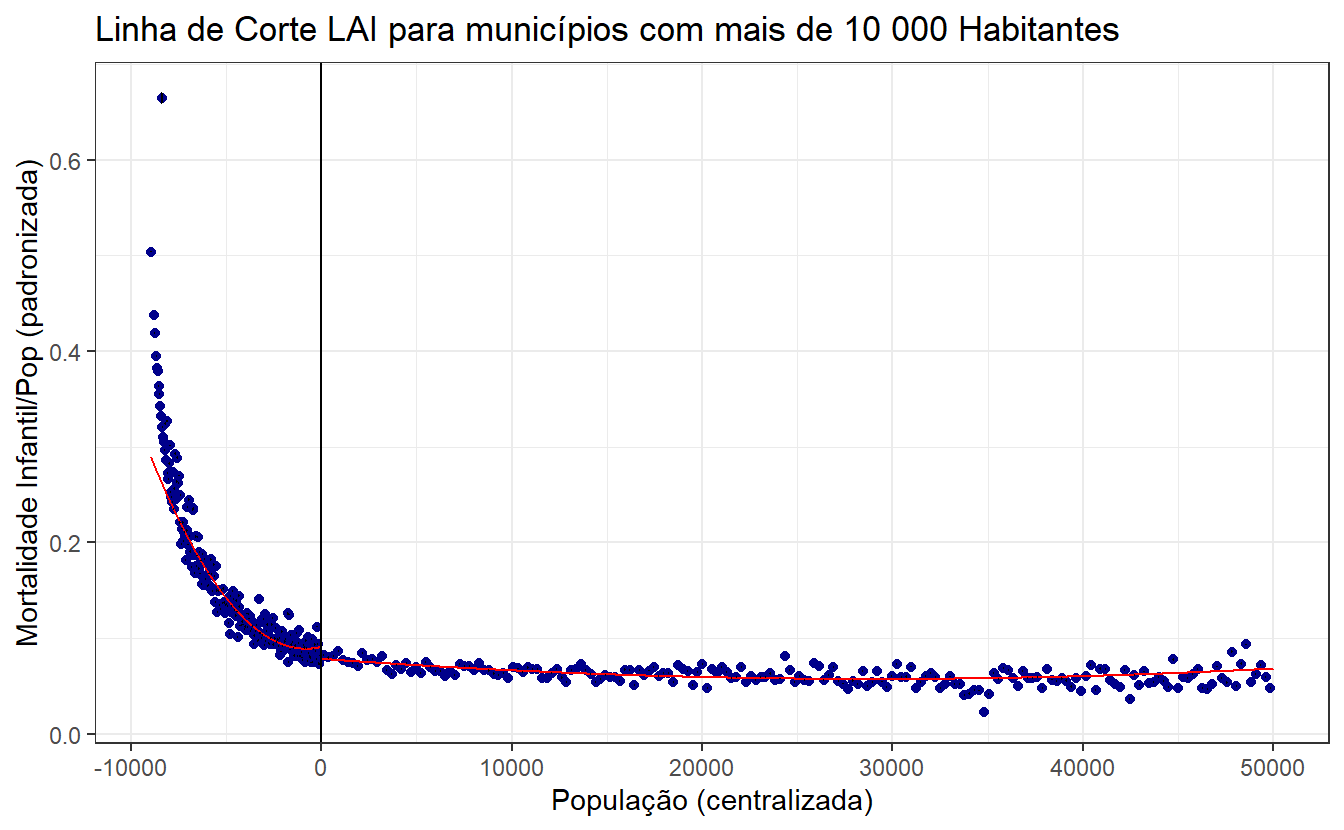
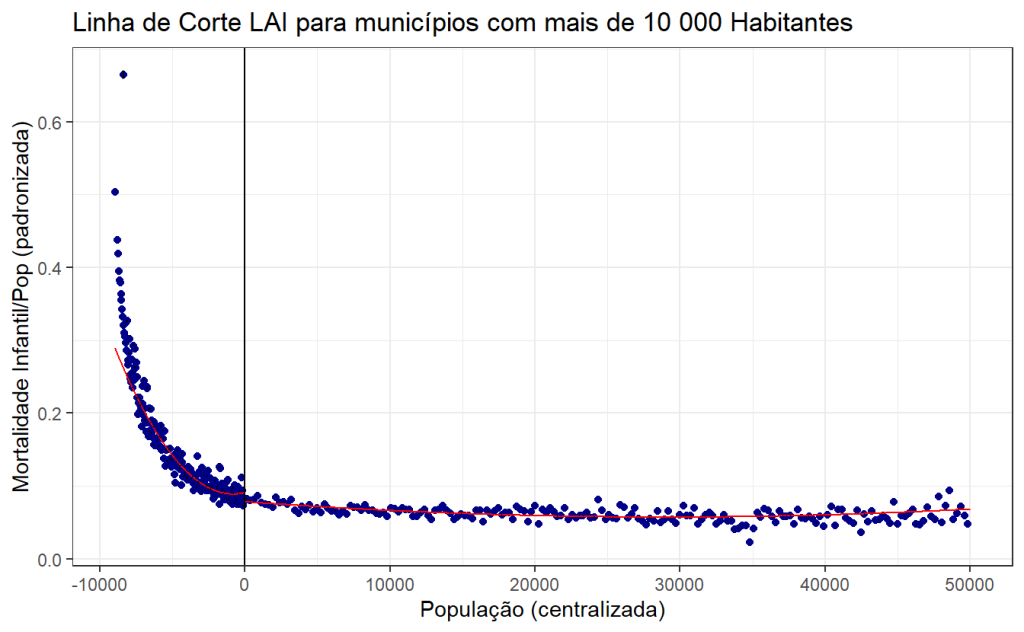
A imagem mostra o comportamento da mortalidade infantil por população padronizada em função da população centralizada (com um ponto de corte central em zero). No contexto da literatura do RDD, espera-se ver um salto ou uma mudança abrupta na média da variável dependente (Mortalidade Infantil/Pop) ao cruzar o ponto de corte, o que sugere um efeito causal da variável de interesse (possivelmente uma política que é aplicada a partir de um certo tamanho populacional).
Neste gráfico específico:
- Vertical Line at x = 0: Marca o ponto de corte (população de 10.000 habitantes), onde espera-se uma descontinuidade.
- Scatter Points: Representam a média da variável dependente para cada bin de população centralizada.
- Fitted Line (in red): Mostra as estimativas locais da regressão não-paramétrica ao redor do ponto de corte, ajustadas para capturar o efeito da intervenção/política.
Código
Call:
lm(formula = y ~ ., data = dat_step1, weights = weights)
Residuals:
Min 1Q Median 3Q Max
-0.08402 -0.03342 -0.01183 0.02200 0.86687
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.329e-01 8.115e-04 163.802 < 2e-16 ***
D -6.759e-02 9.501e-04 -71.136 < 2e-16 ***
x -2.464e-08 3.222e-09 -7.646 2.18e-14 ***
`x^2` 2.116e-15 3.484e-16 6.074 1.28e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.05327 on 17482 degrees of freedom
Multiple R-squared: 0.2391, Adjusted R-squared: 0.239
F-statistic: 1832 on 3 and 17482 DF, p-value: < 2.2e-16As funções rdd_data e rdd_reg_lm do pacote rddtools são usadas para preparar dados e estimar um modelo de regressão para análise de RDD. O modelo ajusta uma regressão polinomial nos dois lados do ponto de corte para estimar o efeito causal do tratamento atribuído pela descontinuidade na variável de running.
Os resultados mostram que o tratamento (D) tem um efeito negativo significativo na variável de resultado ao redor do ponto de corte. A regressão inclui termos lineares e quadráticos para capturar a relação entre a variável de running e o resultado, refletindo a complexidade da relação e garantindo que o efeito estimado seja atribuído ao tratamento e não a outras variações na variável de running.
Resultados
Os resultados da análise de RDD sugerem que a LAI teve um impacto positivo na redução da mortalidade infantil. No entanto, é importante lembrar que esta análise é apenas um estudo preliminar, e que mais pesquisas são necessárias para confirmar esses resultados. Além disso, é importante considerar outros fatores que podem ter influenciado a mortalidade infantil durante o período de estudo, como a qualidade dos serviços de saúde, o nível de renda e a infraestrutura do município.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

