Estimando o efeito do salário mínimo no desemprego em redes de fast food
A ausência de avaliação de impacto de programas é um desafio frequente em muitas esferas do setor público. Isso é frequentemente atribuído à predominância do senso comum e da subjetividade nas avaliações. Essa lacuna não só resulta da falta de análise de dados, mas também da realização de análises inadequadas. Pior ainda, não se faz análises prévias ou posteriores programadas. Então, como podemos realizar uma avaliação adequada de políticas/programas? Este artigo aborda essa questão, destacando o exemplo prático de como avaliar o impacto do salário mínimo no desemprego em redes de fast food, um exercício ensinado em nosso curso de Avaliação de Políticas Públicas utilizando Python.
Luiz Henrique Barbosa Filho
24 de fevereiro de 2024
09:00
A ausência de avaliação de impacto de programas é um desafio frequente em muitas esferas do setor público. Isso é frequentemente atribuído à predominância do senso comum e da subjetividade nas avaliações. Essa lacuna não só resulta da falta de análise de dados, mas também da realização de análises inadequadas. Pior ainda, não se faz análises prévias ou posteriores programadas. Então, como podemos realizar uma avaliação adequada de políticas/programas? Este artigo aborda essa questão, destacando o exemplo prático de como avaliar o impacto do salário mínimo no desemprego em redes de fast food, um exercício ensinado em nosso curso de Avaliação de Políticas Públicas utilizando Python.
Estimando o efeito do salário mínimo no desemprego em redes de fast food
Card e Krueger (1993) estimaram o efeito do aumento do salário mínimo, ocorrido em Abril de 1992, na quantidade de empregados dos restaurantes de fast food em New Jersey. Para isso, utilizaram como grupo de controle, o comportamento do emprego em lojas do estado vizinho, Pensilvânia.
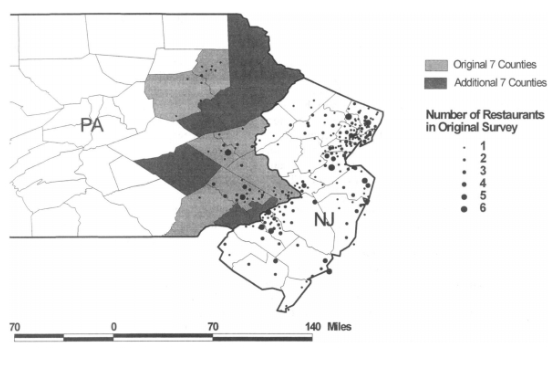
Mapa dos restaurantes presentes no estudo
A base de dados tem informações para quatro redes de fast food dividas em centenas de unidades por estado. Os dados de emprego são de Fevereiro e Novembro de 1992, ou seja, 2 meses antes e 6 meses depois da política.
Quer saber como essa análise foi construída? Seja aluno do nosso curso Avaliação de Políticas Públicas usando Python, e tenha acesso às aulas teóricas e práticas, com o código disponibilizado em Python.
loja
horas_abertas
cadeia
empresa1
empresa2
empresa3
empregos_antes
empregos_depois
estado
0
56
12.0
4
0
0
0
34.0
20.0
Pensilvânia
1
61
12.0
4
0
0
0
24.0
35.5
Pensilvânia
2
445
18.0
1
1
0
0
70.5
29.0
Pensilvânia
3
451
24.0
1
1
0
0
23.5
36.5
Pensilvânia
4
455
10.0
2
0
1
0
11.0
11.0
Pensilvânia
Estimando o Efeito
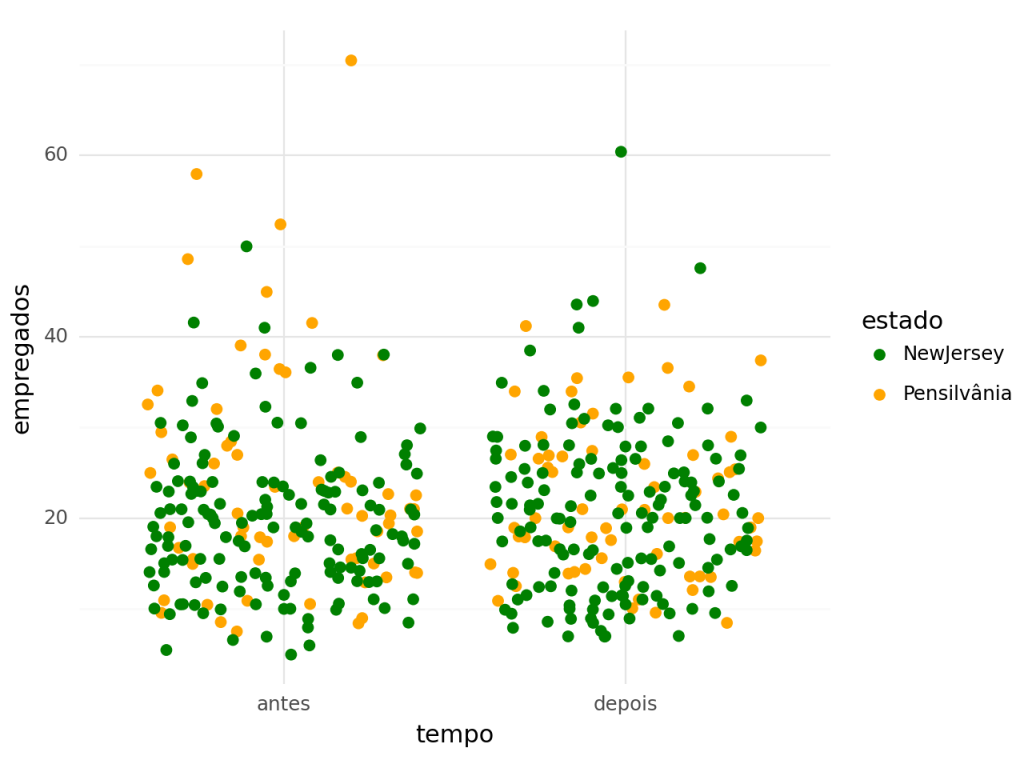
Primeiramente, vamos realizar uma análise exploratória de dados. Queremos saber se há uma mudança clara nos valores da variável de interesse (empregados) antes e depois da intervenção. Podemos realizar essa análise utilizando o gráfico de dispersão, separando o grupo de controle (Pensilvânia) e grupo de tratamento (Pensilvânia).
Como é evidenciado no gráfico acima, infelizmente, a dispersão não nos mostra muito.
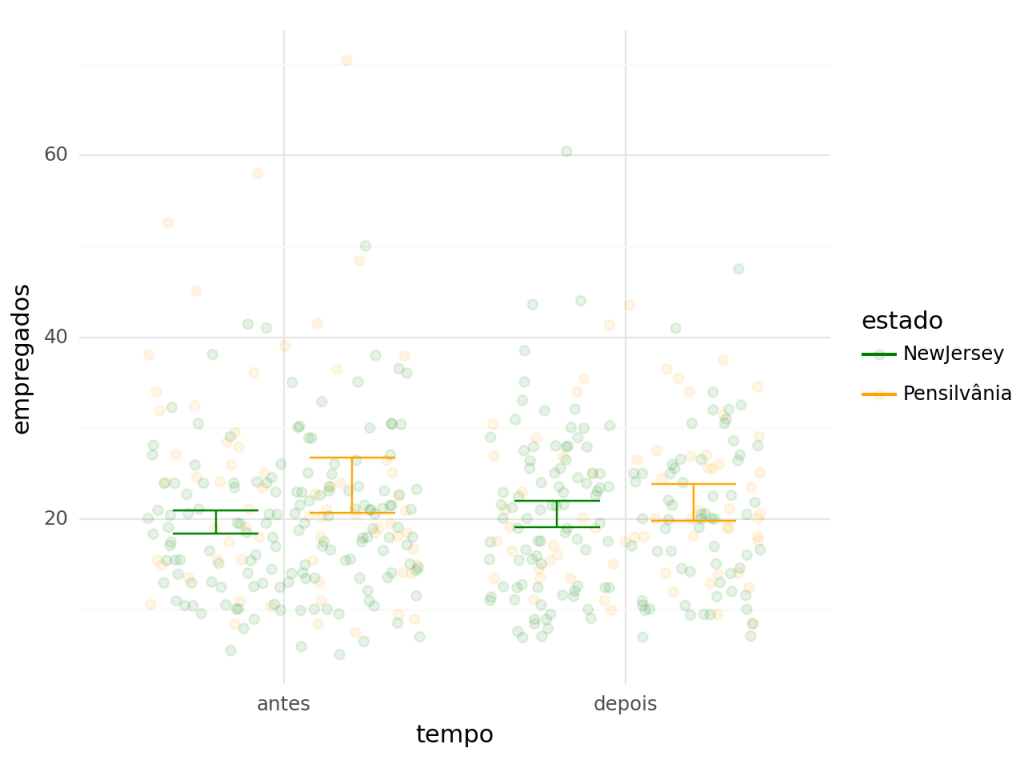
Para representar melhor a mudança, podemos verificar a diferença das médias antes e depois. Colocando uma barra com a média por grupo, podemos ver que em New Jersey aumenta um pouco o número de empregados e na Pensilvânia diminui. A diferença entre essas diferenças é o impacto da política pelo método de diff-in-diff. Ou seja, aparentemente não há diminuição no número de empregados, mas sim, aumento.
De forma mais clara, o efeito é igual a diferença entre as médias das diferenças.
Diferenças-em-Diferenças
Diferenças em Diferenças (Diff in Diff) é uma técnica estatística utilizada para avaliar o impacto causal de uma intervenção, política ou evento sobre uma variável de interesse. A ideia principal é comparar a mudança ao longo do tempo na variável de interesse entre um grupo de tratamento que foi exposto à intervenção e um grupo de controle que não foi exposto. Isso é feito subtraindo a mudança média na variável de interesse no grupo de controle da mudança média no grupo de tratamento.
A equação básica do Diff in Diff pode ser representada da seguinte forma:
Onde:
- é a variável de interesse para a unidade i no período de tempo t.
- é uma constante.
- é o efeito médio do tratamento.
- é o efeito médio do tempo após o tratamento.
- é o efeito da interação entre tratamento e tempo após o tratamento.
- é uma variável indicadora que é 1 se a unidade pertence ao grupo de tratamento e 0 caso contrário.
- é uma variável indicadora que é 1 se o período de tempo é após a implementação do tratamento e 0 caso contrário.
- refere-se às variáveis de controles que garantem a independência condicional do modelo.
- é o termo de erro.
A interpretação do coeficiente é o efeito causal do tratamento sobre a variável de interesse ao longo do tempo após o tratamento, controlando os efeitos fixos do tempo e do tratamento.
Para o nosso caso, rodamos a regressão sem e com controles. O parâmetro de interesse é a interação entre a variável binária de tempo (1: depois, 0: antes) e a variável de tratamento (1: New Jersey, 0:Pensilvânia). Verificamos os resultados abaixo (DID sem controle; DID2 com controles).
O intercepto no contexto do diff-in-diff é interpretado como o valor médio da variável dependente (neste caso, quantidade de empregados) no grupo de controle (Pensilvânia) no período de referência (2 meses antes da implementação da política).
Tempo_b:
A variável de tempo_b refere-se às mudanças ao longo do tempo (8 meses) para todos os valores da variável dependente (número de empregados, neste caso). É uma medida de como o número de empregos mudaram no grupo de tratamento e no grupo de controle ao longo do período considerado.
Tratamento:
A variável de tratamento mede o efeito médio de número de empregados que não é causado pela implementação da política. Neste contexto, seria a diferença média nos número de empregados entre o grupo de tratamento (New Jersey) e o grupo de controle (Pensilvânia) antes da implementação da política.
Tempo_b:Tratamento:
A interação entre tempo_b e tratamento é a chave no diff-in-diff. Essa variável revela a diferença média nos número de empregados causada pela implementação da política. Em outras palavras, ela captura como o efeito do tratamento varia ao longo do tempo em comparação com o grupo de controle.
Considerações
Mostramos, de forma simples, como aplicar o conhecimento de inferência causal para avaliar programas e políticas. Vimos, através do exemplo, que é necessário comparar os efeitos de uma política separando a amostra em um grupo de controle e tratamento, implicitamente, supomos que os grupos sejam comparáveis, isto é, possuam características iguais, caso essa suposição seja violada, encontramos viés na estimativa do efeito. Por suposto, podemos evitar esse problema utilizando variáveis de controle.
Referências
Card, David, e Alan B Krueger. 1993. «Minimum wages and employment: A case study of the fast food industry in New Jersey and Pennsylvania». National Bureau of Economic Research.
 De forma mais clara, o efeito é igual a diferença entre as médias das diferenças.
De forma mais clara, o efeito é igual a diferença entre as médias das diferenças.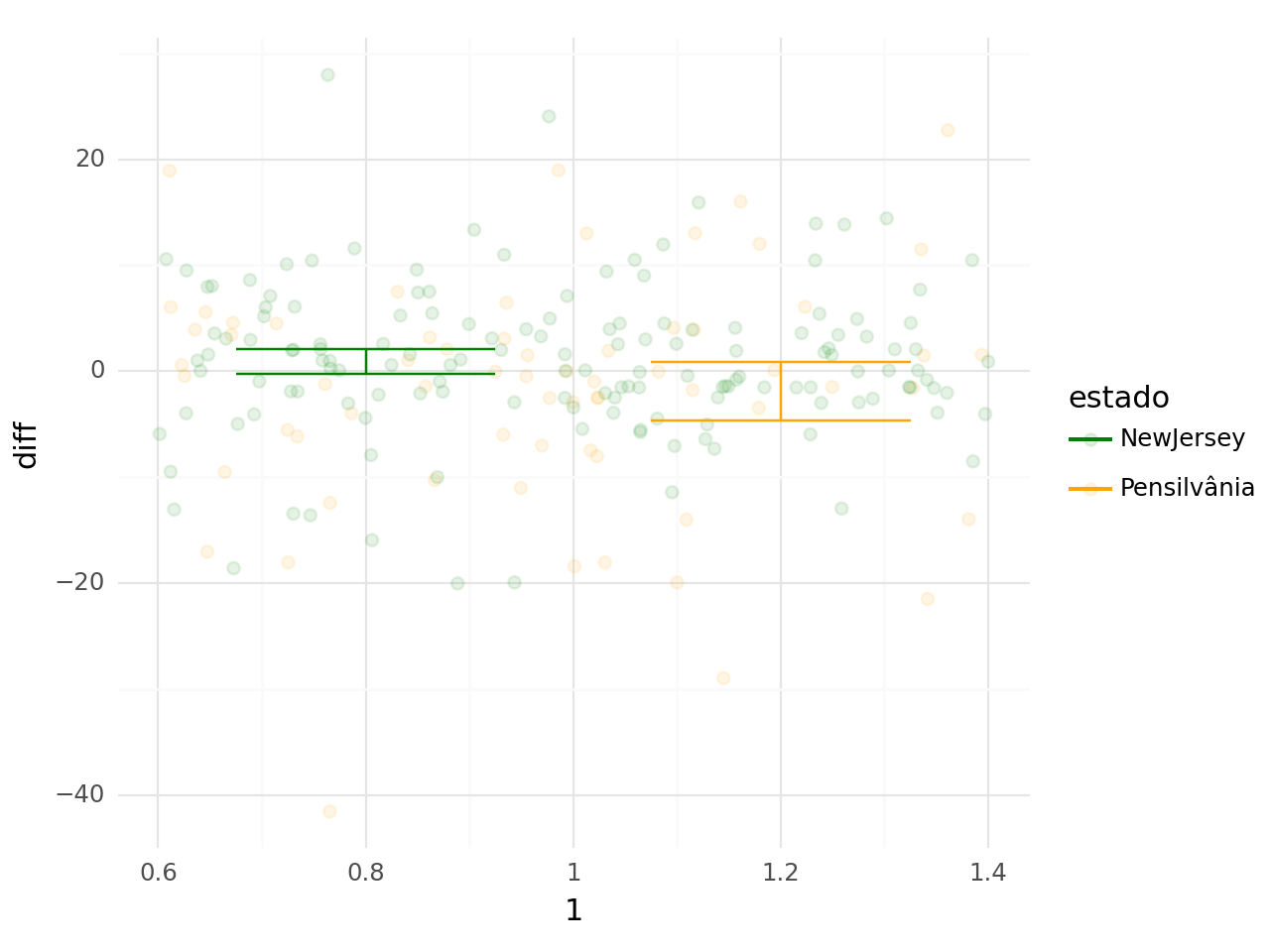
![\[Y_{it} = \alpha + \beta_1 \text{(Tratamento)}_i + \beta_2 \text{(Pós-Tratamento)}_t + \beta_3 \text{(Tratamento)}_i \times \text{(Pós-Tratamento)}_t + \text{Controles } + \epsilon_{it}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-e57920d98ca9f370dfbb8a92281aba62_l3.png "Rendered by QuickLaTeX.com")
 é a variável de interesse para a unidade i no período de tempo t.
é a variável de interesse para a unidade i no período de tempo t. é uma constante.
é uma constante. é o efeito médio do tratamento.
é o efeito médio do tratamento. é o efeito médio do tempo após o tratamento.
é o efeito médio do tempo após o tratamento. é o efeito da interação entre tratamento e tempo após o tratamento.
é o efeito da interação entre tratamento e tempo após o tratamento. é uma variável indicadora que é 1 se a unidade
é uma variável indicadora que é 1 se a unidade  pertence ao grupo de tratamento e 0 caso contrário.
pertence ao grupo de tratamento e 0 caso contrário. é uma variável indicadora que é 1 se o período de tempo
é uma variável indicadora que é 1 se o período de tempo  é após a implementação do tratamento e 0 caso contrário.
é após a implementação do tratamento e 0 caso contrário. refere-se às variáveis de controles que garantem a independência condicional do modelo.
refere-se às variáveis de controles que garantem a independência condicional do modelo. é o termo de erro.
é o termo de erro.
