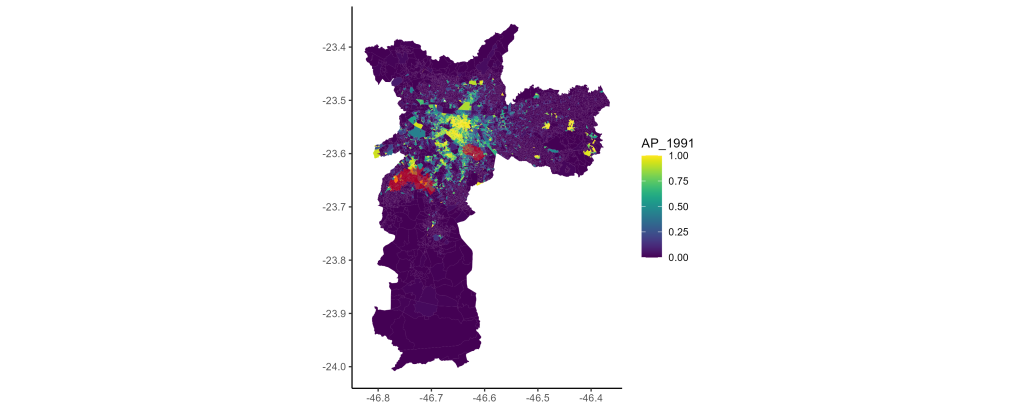
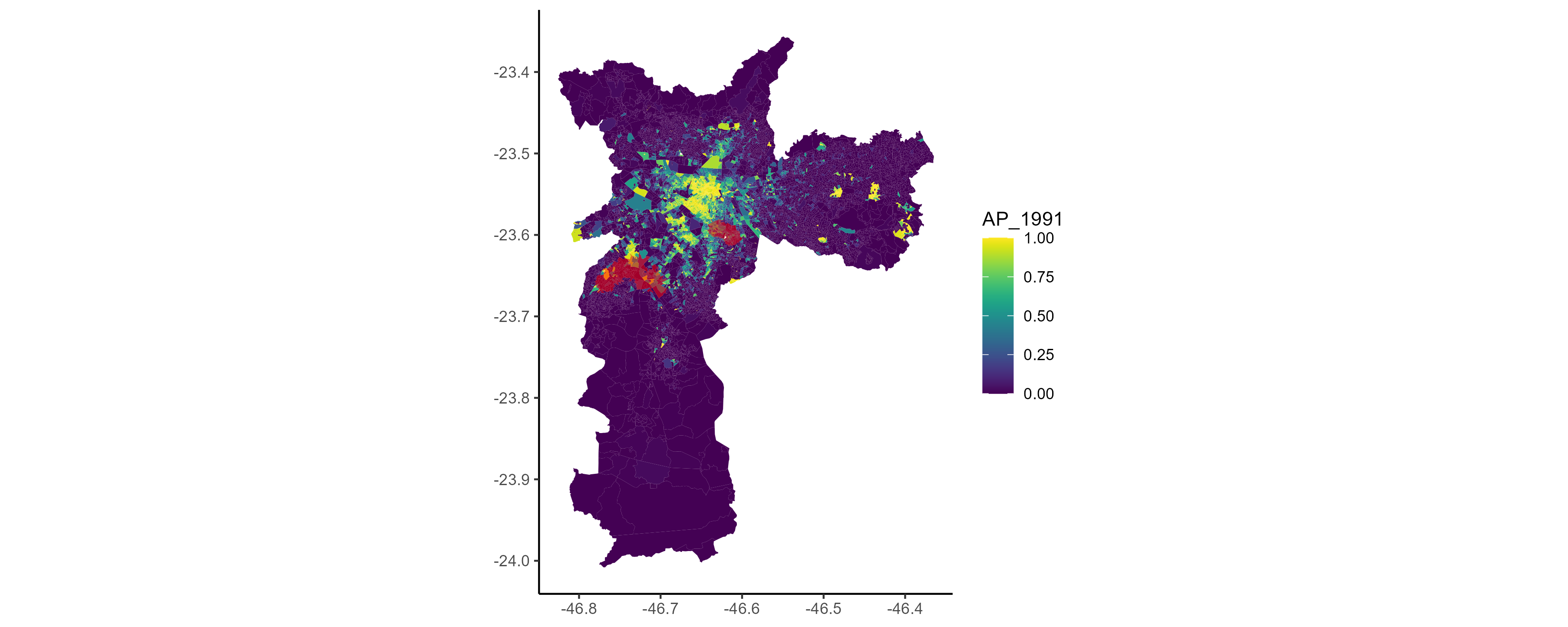
Quando comparamos a distribuição da verticalização entre estes dois grupos (tratados (1) e restantes (0)) isso fica mais claro.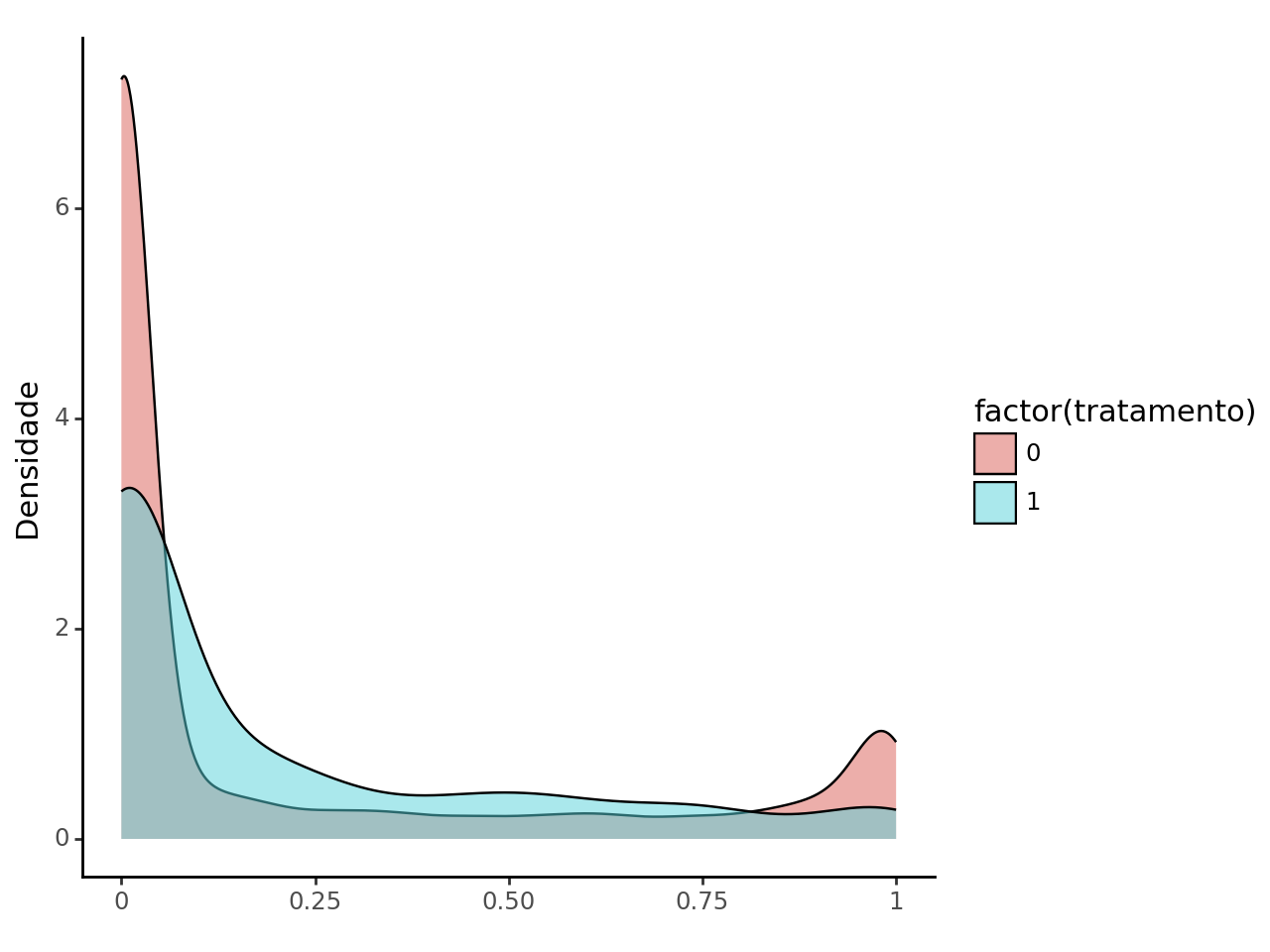
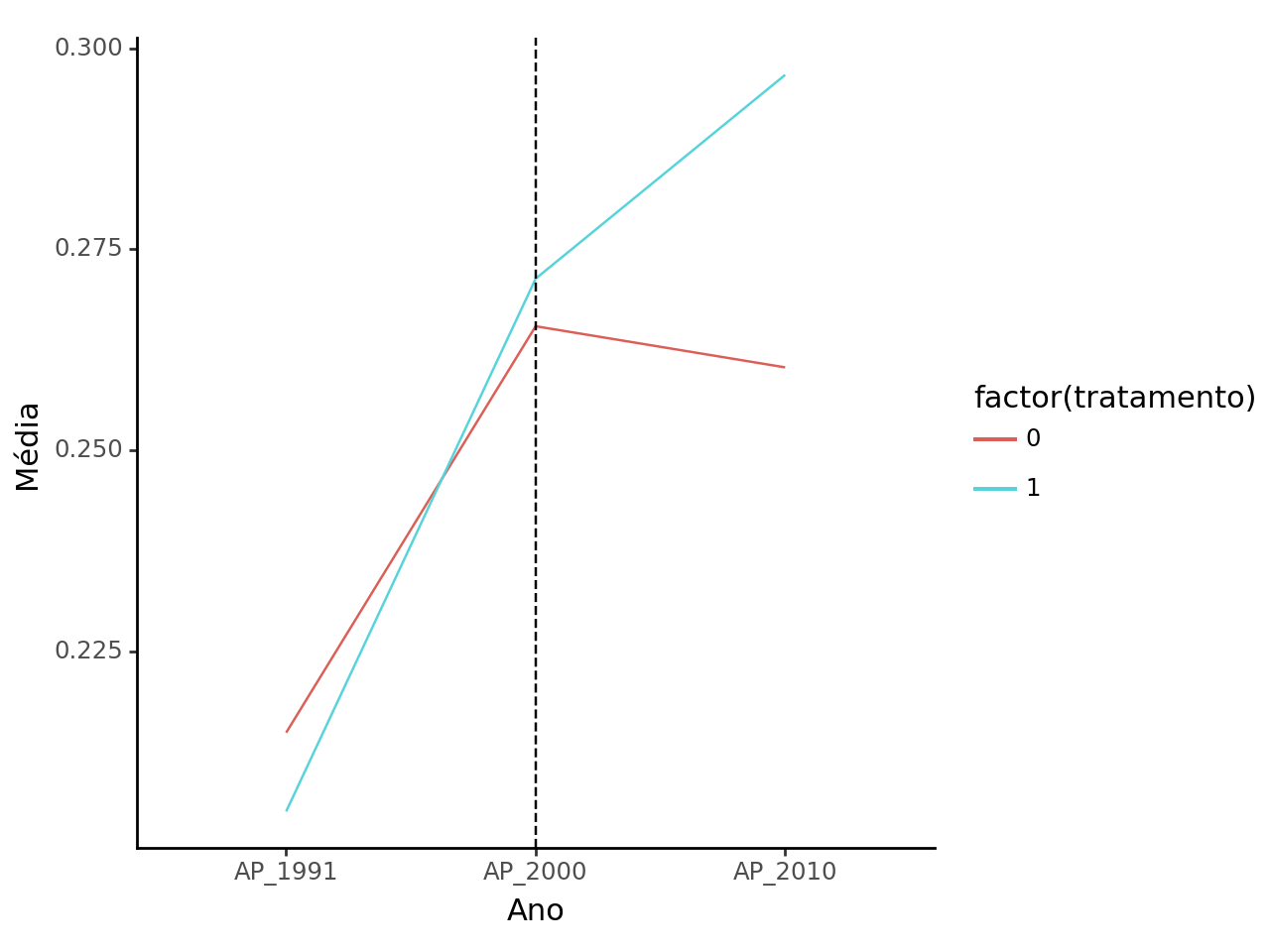
Veja que se formos estimar o modelo de diferenças-em-diferenças, nós precisamos adequar o grupo de controle para que as tendências fiquem paralelas.

Assim, para avaliar o efeito, é preciso tornar esses grupos semelhantes. Para isso, utilizaremos o pareamento, que permite selecionar setores de dentro do grupo restante para formar um grupo de controle parecido com o grupo de tratamento. Vamos empregar o método de pareamento por vizinhos mais próximos.
Além da variável de verticalização, também utilizamos a renda domiciliar per capita, a proporção de pessoas com ensino superior, a proporção de domicílios que são alugados e a proporção de jovens adultos (25-34 anos) entre os moradores do setor censitário.
Após o uso do pareamento, aparentemente não tivemos sucesso em tornar parecidas as distribuições.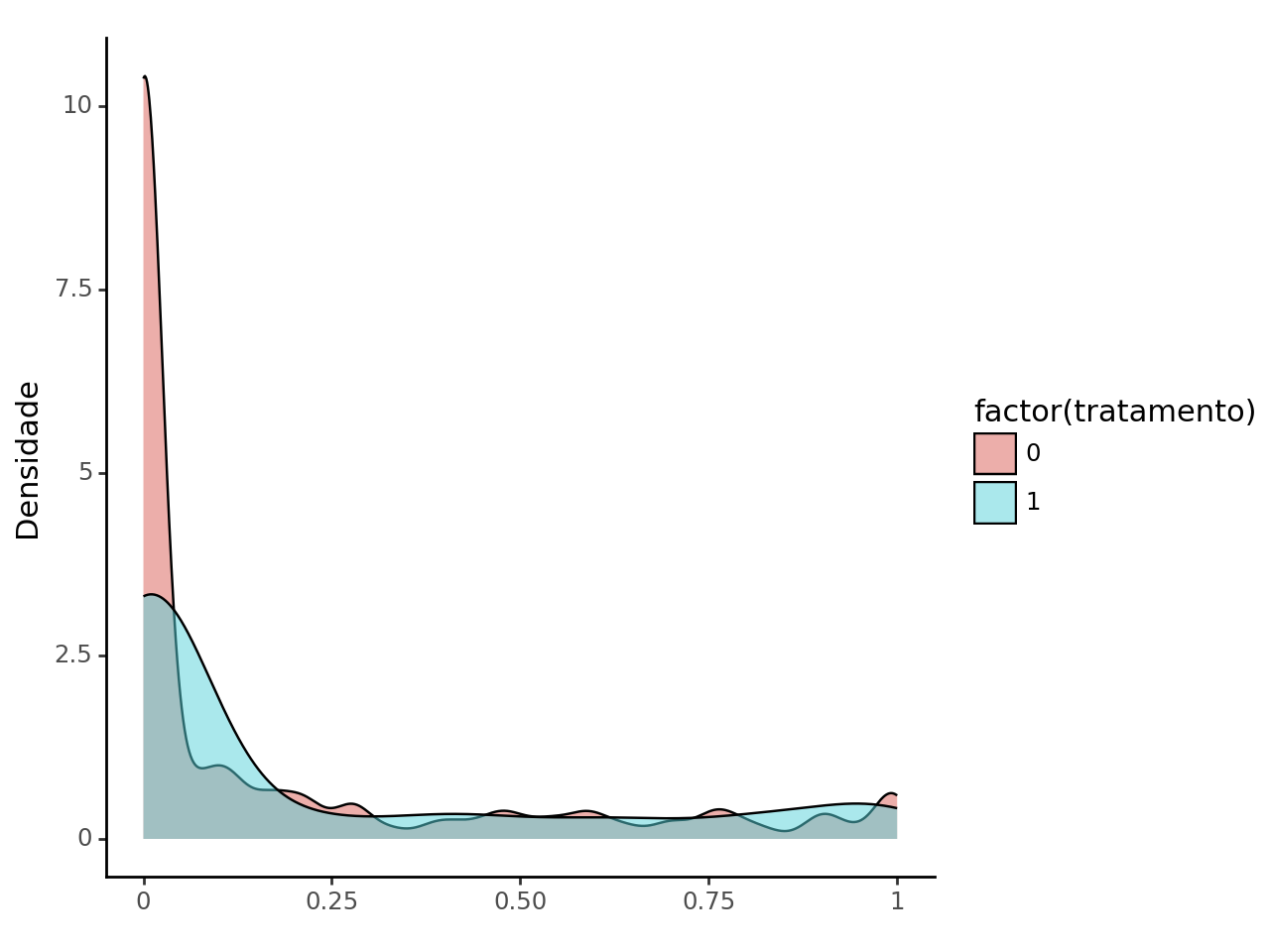
Muito menos conseguimos melhorar as tendências.
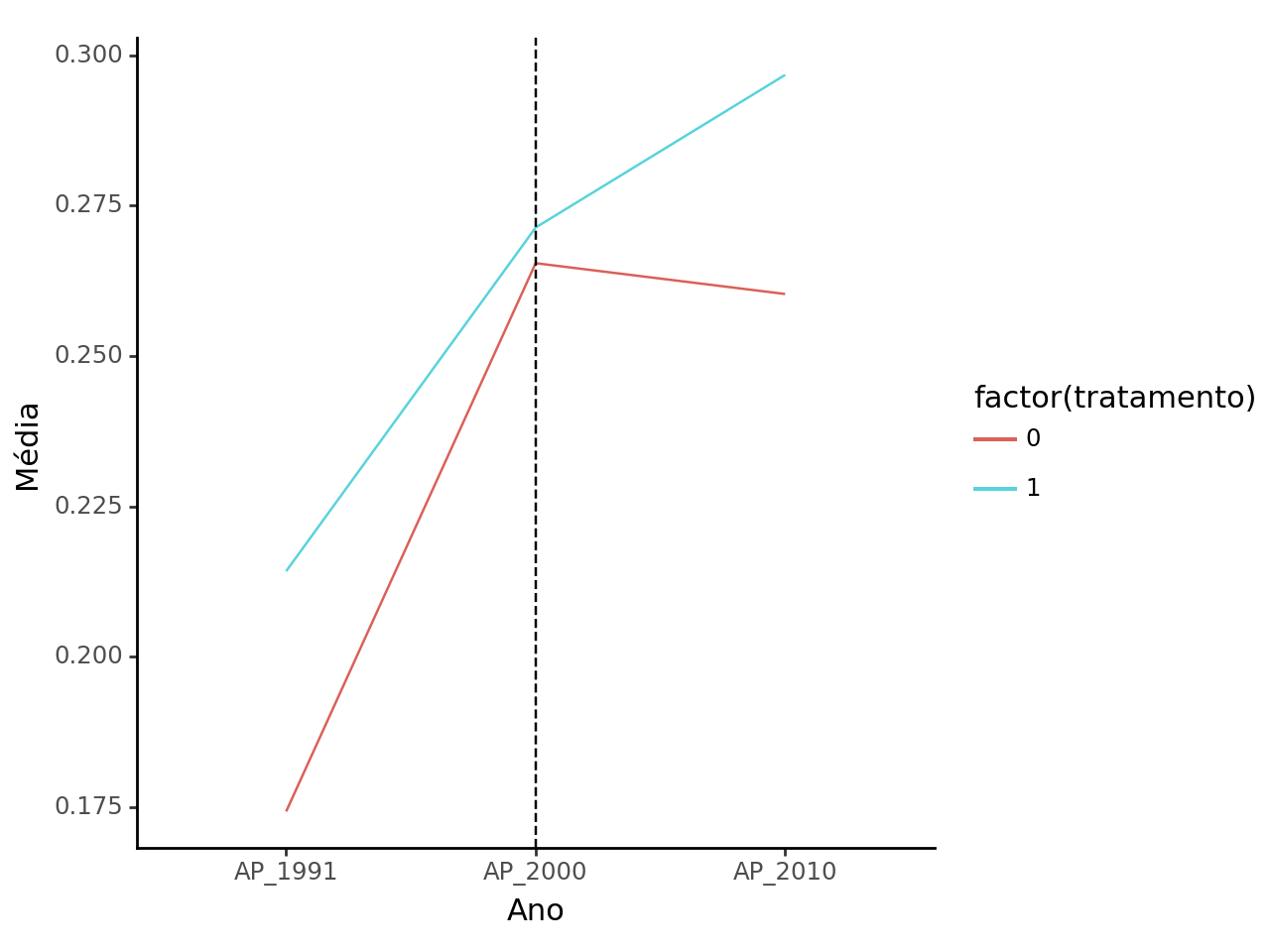 O método de pareamento, portanto, é inútil? Claramente não podemos afirmar isso, afinal, como qualquer método, existe diferentes formas de realizar a sua aplicação, visto que há diversos modelos/algoritmos que podem ser empregados.
O método de pareamento, portanto, é inútil? Claramente não podemos afirmar isso, afinal, como qualquer método, existe diferentes formas de realizar a sua aplicação, visto que há diversos modelos/algoritmos que podem ser empregados.
Propensity Score
Uma forma interessante de obtenção da distância entre as observações é o Propensity Score, que considera a probabilidade da observação pertencem ao grupo de controle ou tratamento, independente de seu pertencimento "original". Para tanto, criamos um escore de propensity (a probabilidade de pertencimento de determinado grupo) usando uma regressão logística e tomando como variável dependente a variável binária que representa o tratamento, e como variáveis preditoras as características das unidades.
Após a estimação do escore de propensão, devemos realizar o match (pareamento das unidades conforme o escore). Aqui, aplicamos o emparelhamento de 1:1 (one-to-one Matching).
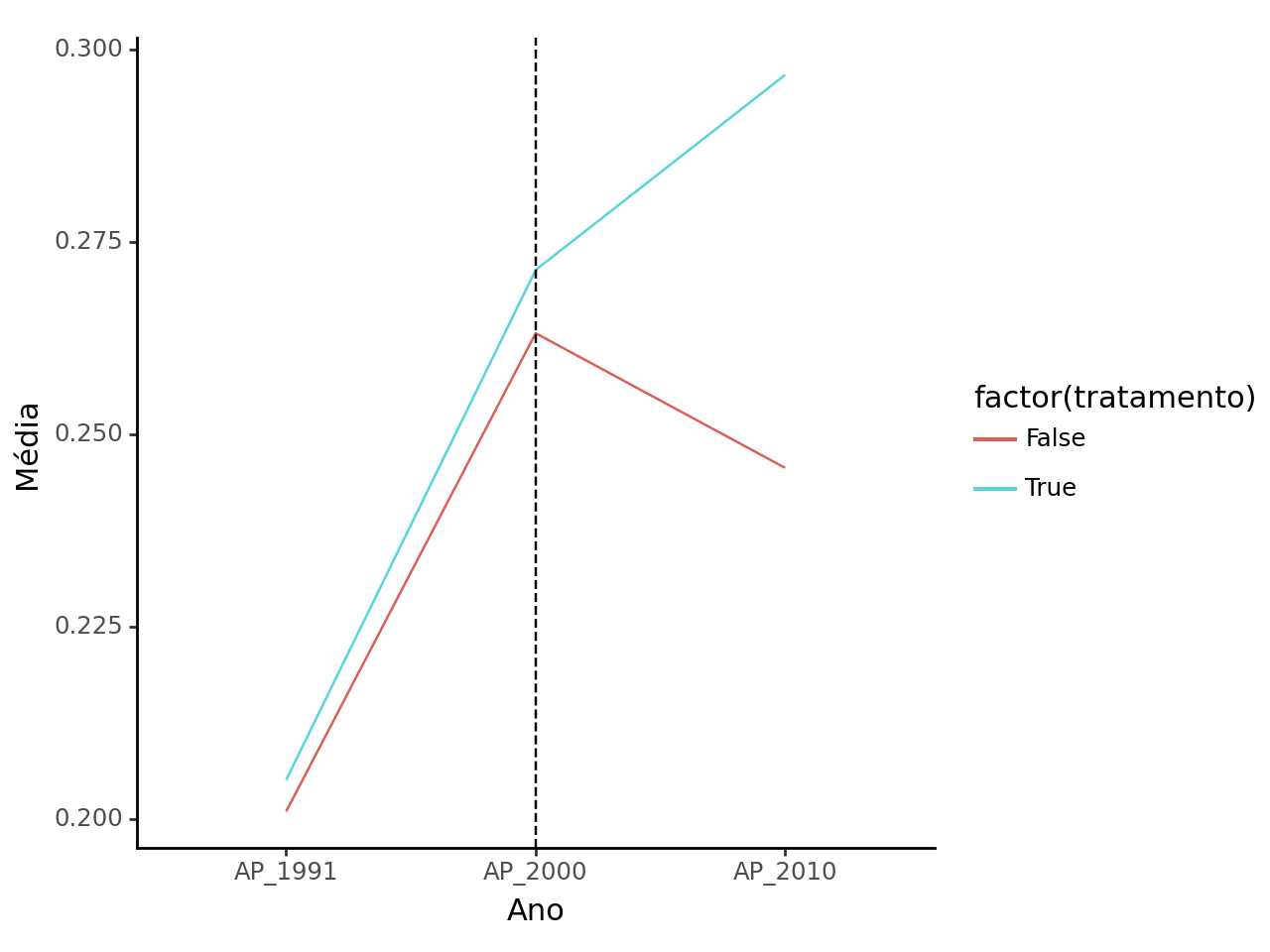 Bem melhor que antes, certo?
Bem melhor que antes, certo?

