Na edição 54 do Clube do Código, de autoria do Renato Lerípio, replicamos o box "Propagação da Inflação de Alimentos" do Relatório de Inflação de setembro de 2018, do Banco Central brasileiro. A ideia é relativamente simples: estimar, através de um VAR, o efeito de choques no IPCA do grupo "Alimentação e bebidas" sobre os demais preços da economia. Esses outros preços são representados por um núcleo, o qual expurga do índice geral os itens do grupo "Alimentação e bebidas" (obviamente) e também itens relacionados à energia. O box não explicita que itens estão inclusos nesta última categoria, então vamos considerar os itens "Combustíveis (veículos)" e "Combustíveis (domésticos)" -- talvez energia elétrica também entre nesta conta, mas vamos ignorar. O importante é que o resultado final fica bem próximo do original e os interessados podem facilmente adaptar de acordo com sua intuição.
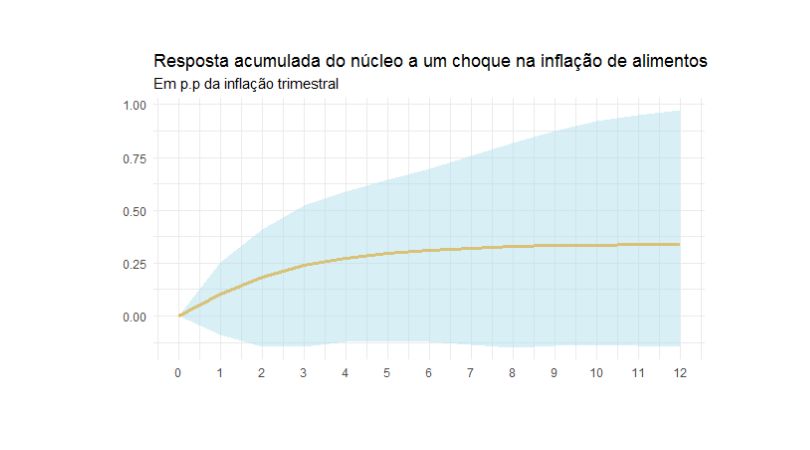
O interessante do exercício é que ele fornece uma estimativa do efeito de segunda ordem de choques nos preços dos alimentos. Quem acompanha os relatórios e atas do BC provavelmente já se deparou com essa expressão. Em linhas gerais, o efeito de segunda ordem ocorre quando o choque no preço de um determinado segmento contamina o restante do conjunto de preços da economia -- e vale lembrar que, neste caso, a política monetária deve ser reativa. Do ponto de vista operacional, um outro aspecto interessante do exercício é que ele envolve uma série de ferramentas que são utilizadas com bastante frequência em análises e modelagem: acumular valores de uma série, modificar a frequência e aplicar ajuste sazonal.
Abaixo, colocamos o gráfico que ilustra a função impulso-resposta extraída do VAR estimado.
 Membros do Clube do Código já podem acessar o código do exercício no repositório do github.
Membros do Clube do Código já podem acessar o código do exercício no repositório do github.

