A edição 57 do Clube do Código aborda o tema de nowcasting. Em termos bem gerais, nowcasting é a previsão do presente -- ou do futuro/passado muito recente. O objetivo, neste caso, é encontrar um conjunto de variáveis capaz de capturar a dinâmica da série de interesse no mesmo período em que esta ocorre.
Entretanto, este conjunto pode envolver um número arbitrariamente grande de variáveis: dezenas, centenas ou até milhares. Se o número de variáveis for superior ao número de observações, não é possível estimar coeficientes em modelos paramétricos tradicionais (OLS, por exemplo). Por outro lado, mesmo que seja possível estimar os coeficientes, não é apropriado introduzir um número muito elevado de variáveis nos modelos: isto pode gerar overfitting, o que tende a produzir previsões bastante imprecisas.
Uma solução comumente adotada é utilizar um modelo com fatores. Mais especificamente, um fator busca reduzir o conjunto de informações (variáveis) a uma fonte de variação comum entre elas. Em geral, essa fonte de variação comum é não-observável. A ideia, portanto, é utilizar um conjunto de variáveis relacionadas a essa fonte e, ao extrair o componente de variação comum entre elas, obter uma aproximação desta fonte não-observável.
Para ficar mais claro, imagine que estejamos interessados em acompanhar em "tempo real" a evolução da atividade econômica. Sabemos que uma série de variáveis são afetados ou afetam a atividade econômica, embora em direções e magnitudes possivelmente distintas. Por exemplo, a utilização de energia elétrica, a produção da indústria, a confiança dos consumidores, etc. Ao extrair o componente de variação comum entre estas variáveis, poderíamos ter uma medida (indireta) da atividade econômica. E se tivermos estas informações disponíveis no instante t, poderemos ter informação sobre a atividade econômica também em t -- um Nowcast.
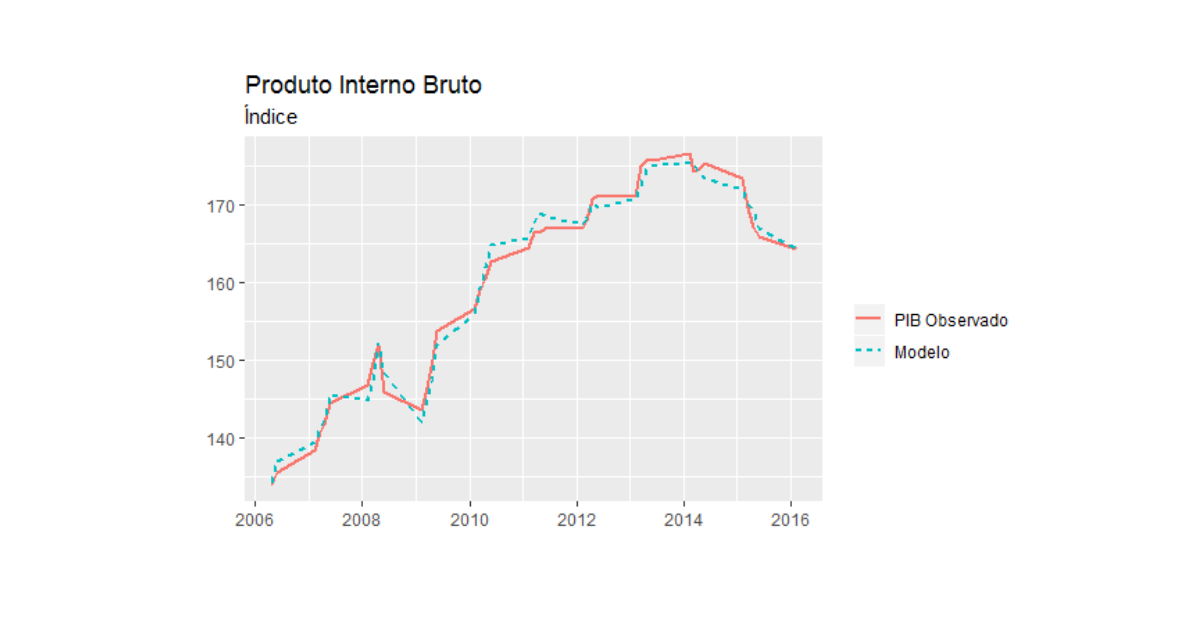
Estimulado por essa ideia, o exercício busca realizar um Nowcast do PIB. O IBGE divulga os resultados do PIB cerca de 2 meses depois do fim de cada trimestre. Porém, uma variedade de informações sobre a atividade torna-se disponível no decorrer do próprio trimestre. É possível, então, reunir essas informações, extrair fatores e obter previsões. De início, serão utilizadas apenas 10 variáveis: medidas de inflação, atividade da indústria e confiança dos agentes. Após realizar o tratamento nos dados, serão construídos os fatores através de Componentes Principais (PCA). Em seguida, será ajustado um modelo OLS com a série de PIB como variável dependente e os quatro primeiros fatores como covariáveis.