No mês de dezembro, iremos lançar uma nova versão do Clube do Código, que se chamará Clube AM. O projeto de compartilhamento de códigos da Análise Macro vai avançar para uma versão 2.0, que incluirá a existência de um grupo fechado no Whatsapp, de modo a reunir os membros do Novo Clube, compartilhando com eles todos os códigos dos nossos posts feitos aqui no Blog, exercícios de análise de dados de maior fôlego, bem como tirar dúvidas sobre todos os nossos projetos, exercícios e nossos Cursos e Formações.
Para ilustrar o que vamos compartilhar lá nesse novo ambiente, estou publicando nesse espaço alguns dos nossos exercícios de análise de dados. Esses exercícios fazem parte do repositório atual do Clube do Código, que deixará de existir. Além de todos os exercícios existentes no Clube do Código, vamos adicionar novos exercícios e códigos toda semana, mantendo os membros atualizados sobre o que há de mais avançado em análise de dados, econometria, machine learning, forecasting e R.
Hoje, vou mostrar um exercício que fizemos que buscava relacionar o índice VIX com a volatilidade da taxa de câmbio. Como de praxe, o script começa com alguns pacotes que utilizamos no exercício.
library(BETS) library(xts) library(fGarch) library(scales) library(quantmod) library(xts) library(gridExtra) library(tidyverse) library(timetk)
Na sequência, pegamos os dados do câmbio diretamente do site do Banco Central e estimamos a volatilidade da mesma a partir de um modelo GARCH.
cambio = BETSget(1, from='2014-01-01') cambiod = xts(cambio$value, order.by = cambio$date) dcambio = diff(log(cambiod)) dcambio = dcambio[complete.cases(dcambio)] m1=garchFit(~1+garch(1,1),data=dcambio,trace=F) vol = fBasics::volatility(m1) vol = xts(vol, order.by = cambio$date[-1]) volatilidade = tk_tbl(vol, preserve_index = TRUE, rename_index = 'date')
Na sequência, pegamos o índice VIX, utilizando para isso o pacote quantmod. Com as duas séries em mãos, nós podemos juntá-las em um único tibble.
getSymbols('VIXCLS', src='FRED')
vix = tibble(date=as.Date(time(VIXCLS)),
vix = VIXCLS)
data = inner_join(vix, volatilidade, by='date') %>%
drop_na()
colnames(data) = c('date', 'vix', 'volcambio')
De posse dos dados, podemos gerar um gráfico como abaixo.
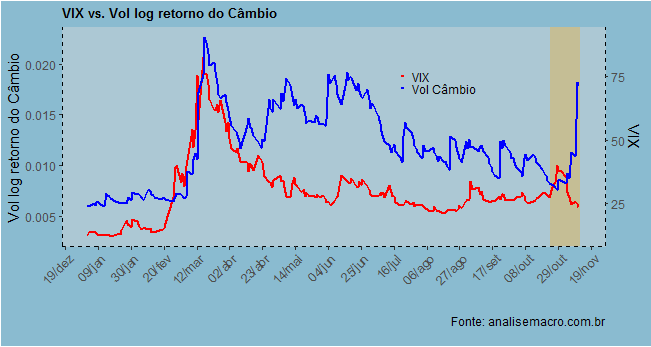
As séries costumam apresentar alguma correlação positiva. Mas é possível observar na ponta um descolamento das mesmas. Enquanto o VIX está indo para baixo, a volatilidade da taxa de câmbio USD/BRL apresentou uma alta considerável nos últimos dias.
_________________
(*) Cadastre-se aqui na nossa Lista VIP para receber um super desconto na abertura das Turmas 2021.


