O Bolsa Família (PBF) é um programa de transferência de renda condicional criado em 2003, amplamente investigado na literatura e com significativos impactos em redução de pobreza, escolarização, distribuição de renda, entre outros. Para avaliar estes impactos os analistas, assistentes e pesquisadores utilizam os microdados do PBF através de linguagens de programação. Neste exercício mostramos como fazer isso utilizando o R.
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
library(data.table) # CRAN v1.14.0 library(janitor) # CRAN v2.1.0 library(downloader) # CRAN v0.4 library(dplyr) # CRAN v1.0.7
Há uma grande variedade de dados relacionados ao PBF. Neste exemplo, iremos explorar a tabela referente aos valores de parcela pagos aos beneficiários do programa, disponível no Portal da Transparência.
Os dados são armazenados em arquivos CSV compactados em formato ZIP, havendo um arquivo para cada mês/ano. Sendo assim, precisamos baixar o arquivo compactado, descompactá-lo e, por fim, importar o CSV para o R. Para facilitar todo este procedimento, criei uma função e deixei disponível no GitHub. O comando abaixo importa a função para ser usada no R:
# Importar do GitHub função para acesso aos dados do PBF (Pagamentos) downloader::source_url( url = paste0( "https://gist.githubusercontent.com/schoulten/", "37fc426ef1ceefcaa96f8e232d1380c7/raw/", "34665e0354caeb3ff65e1bbaf0a384f97112a5bd/", "import_pbf_pagmt.R" ), sha = "7e9f3d3d3961d762f5c3e8d06b3ceacc1911dd06" )
Com a função no environment, passamos um valor de ano (4 dígitos) e mês (2 dígitos) de referência para importar em formato tabular (data.table1) os dados do Bolsa Família (Pagamentos), por exemplo:
# Importar dados (setembro/2021)
tbl_pbf <- import_pbf_pagmt("2021", "09")
dplyr::glimpse(tbl_pbf) # classe data.table
# Rows: 14,655,291
# Columns: 9
# $ mes_referencia <int> 202109, 202109, 202109, 202109, 202109, 202109,~
# $ mes_competencia <int> 202104, 202104, 202104, 202104, 202104, 202104,~
# $ uf <chr> "BA", "ES", "MG", "PI", "RJ", "RS", "BA", "MG",~
# $ codigo_municipio_siafi <int> 3843, 5675, 604, 995, 5839, 996, 3709, 4085, 60~
# $ nome_municipio <chr> "RODELAS", "MUQUI", "DIVISA ALEGRE", "COIVARAS"~
# $ cpf_favorecido <chr> "***.015.315-**", "***.196.477-**", "***.538.95~
# $ nis_favorecido <int64> 1.004631e-313, 6.246777e-314, 6.262453e-314, ~
# $ nome_favorecido <chr> "MARIA EDILENE TELES FONSECA", "KARLA CRISTINA ~
# $ valor_parcela <dbl> 347, 446, 260, 624, 617, 194, 179, 178, 260, 89~
Com apenas um comando já temos um objeto com mais de 14 milhões de observações e 9 colunas pronto para análise. Consulte o dicionário das variáveis no Portal da Transparência para mais informações. Por exemplo, se você quiser saber o valor médio das parcelas pagas e o total de beneficiários do programa:
# Benefício médio mean(tbl_pbf$valor_parcela, na.rm = TRUE) # [1] 186.2093 # Número de beneficiários length(unique(tbl_pbf$nis_favorecido)) # [1] 14655264
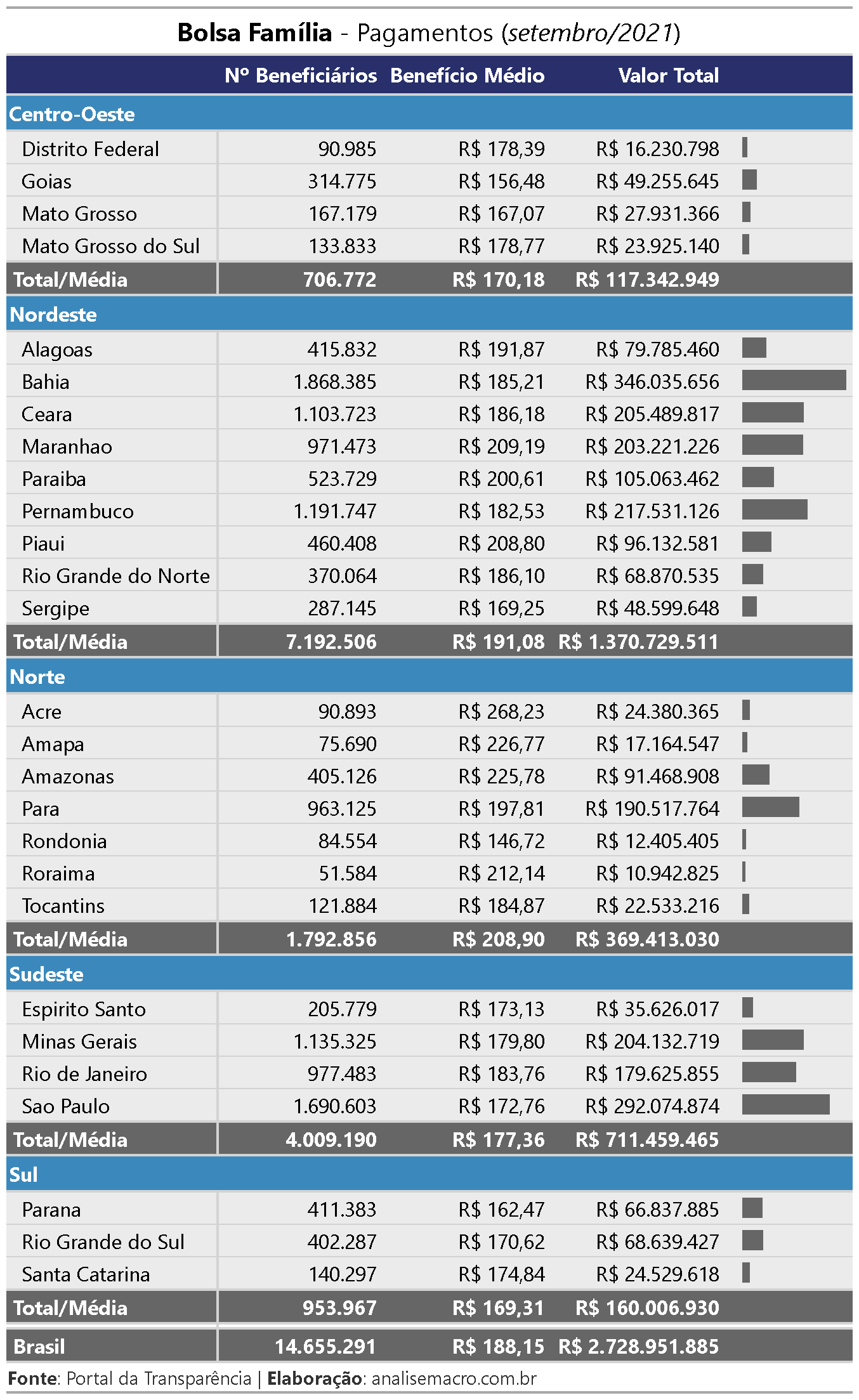
Similarmente podemos calcular o total (R$) em benefício repassado por estado, por exemplo:
# Valor total repassado por estado (UF) total_uf <- tbl_pbf[, list(valor_total = sum(valor_parcela, na.rm = TRUE)), by = uf] total_uf # uf valor_total # 1: BA 346035656 # 2: ES 35626017 # 3: MG 204132719 # 4: PI 96132581 # 5: RJ 179625855 # 6: RS 68639427 # 7: PE 217531126 # 8: MA 203221226 # 9: SC 24529618 # 10: AC 24380365 # 11: AL 79785460 # 12: AM 91468908 # 13: AP 17164547 # 14: CE 205489817 # 15: DF 16230798 # 16: GO 49255645 # 17: MS 23925140 # 18: MT 27931366 # 19: PA 190517764 # 20: PB 105063462 # 21: PR 66837885 # 22: RN 68870535 # 23: RO 12405405 # 24: RR 10942825 # 25: SE 48599648 # 26: SP 292074874 # 27: TO 22533216 # uf valor_total
Ou ainda fazer análises um pouco mais elaboradas/informativas, como essa:
Saiba mais
As possibilidades de análise que os dados oferecem são diversas, saiba mais nos cursos da Análise Macro.
[1] Classe de objeto mais recomendada para lidar com arquivos grandes (neste exemplo, 14+ milhões de linhas).


