Nos últimos dias, infelizmente, observamos um aumento no número de focos de queimadas em várias regiões do Brasil. Em resposta a essa situação, realizamos uma análise no Python da série temporal dos focos de queimadas no país, utilizando dados mensais coletados pelo Instituto Nacional de Pesquisas Espaciais (INPE) de 1998 a 2024. O objetivo desta análise é investigar tendências, padrões sazonais, distribuição e o comportamento geral do número de focos de queimadas, a fim de identificar padrões relevantes que possam contribuir para uma melhor compreensão do problema.
Dados
Usamos os dados disponibilizados pelo INPE através da página do Programa Queimadas do INPE, que remete aos dados de Monitoramento dos Focos Ativos por Países. A base de dados contempla o número de focos ativos detectados por satélite, fornecendo informações mensais sobre os focos de queimadas em todo o território brasileiro.
Análise de dados
Para entender o comportamento dos dados, devemos ter em mente que eles se tratam de uma Série Temporal, ou seja, dados que são ordenados ao longo do tempo. Isso é muito importante, pois dessa forma, podemos empregar uma análise de dados voltada exclusivamente para este tipo de dados.
Os pontos principais que devemos compreender de uma Série Temporal são:
- Tendência: A série temporal indica um aumento geral no número de focos de queimadas ao longo dos anos.
- Sazonalidade: Existe um padrão sazonal bem definido, com picos de queimadas durante a época seca (julho-agosto-setembro), e quedas durante a época chuvosa (janeiro-fevereiro-março).
- Distribuição: A distribuição dos focos de queimadas apresenta uma grande variabilidade, com picos bastante elevados e momentos de relativa estabilidade.
Uma vez que definimos os conceitos acima, podemos empregar ferramentas estatísticas e de visualização para análisar os dados:
- Gráfico de Linha: Para visualizar a trajetória da série temporal, identificando tendências e sazonalidades.
- Estatísticas Descritivas: Para obter medidas de tendência central (média, mediana), dispersão (desvio padrão, variância) e valores extremos (mínimo, máximo).
- Histograma: Para visualizar a distribuição dos dados, identificando a frequência de ocorrência de diferentes valores.
- Sazonalidade: Para analisar os padrões sazonais, identificando os meses com maior e menor número de focos de queimadas.
- Violin Plot: Para comparar a distribuição dos dados em diferentes meses do ano.
- Decomposição: Para separar a série temporal em suas componentes: tendência, sazonalidade e resíduos.
- Dessazonalização e Média Móvel: Para remover a sazonalidade e suavizar a série temporal, facilitando a análise de tendências de longo prazo.
Bibliotecas
# Carrega bibliotecas
# Manipulação -------------------
import pandas as pd
import numpy as np
# Visualização e Estatística -----------------
import seaborn as sns
from matplotlib import pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.seasonal import seasonal_decompose
sns.set()Coleta dos Dados
Após carregar as bibliotecas necessárias, devemos importar os dados que vamos analisar. Realizamos o procedimento diretamente usando a função pd.read_csv do pandas, passando diretamente o link de download do arquivo.
# Realiza a leitura do arquivo diretamente do site
dados_brutos = pd.read_csv("https://terrabrasilis.dpi.inpe.br/queimadas/situacao-atual/media/csv_estatisticas/historico_pais_brasil.csv")
dados_brutos.tail()| Unnamed: 0 | Janeiro | Fevereiro | Março | Abril | Maio | Junho | Julho | Agosto | Setembro | Outubro | Novembro | Dezembro | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 2023 | 2494.0 | 2035.0 | 2585.0 | 2359.0 | 5286.0 | 8597.0 | 13985.0 | 28056.0 | 46498.0 | 39692.0 | 26824.0 | 11515.0 | 189926.0 |
| 26 | 2024 | 4555.0 | 4566.0 | 5448.0 | 2613.0 | 6324.0 | 12432.0 | 22478.0 | 51527.0 | NaN | NaN | NaN | NaN | 109943.0 |
| 27 | Máximo* | 7057.0 | 3238.0 | 5213.0 | 4117.0 | 6698.0 | 18024.0 | 30391.0 | 91085.0 | 141220.0 | 67228.0 | 45364.0 | 28639.0 | 393915.0 |
| 28 | Média* | 3228.0 | 1968.0 | 2384.0 | 2215.0 | 3827.0 | 7635.0 | 15118.0 | 46529.0 | 64052.0 | 37922.0 | 21945.0 | 11264.0 | 217563.0 |
| 29 | Mínimo* | 547.0 | 562.0 | 667.0 | 538.0 | 1811.0 | 3551.0 | 4740.0 | 21410.0 | 23293.0 | 19568.0 | 6804.0 | 4376.0 | 101530.0 |
Tratamento dos dados
Os dados brutos não estão em um formato ideal para análise, bem como há linhas indesejadas. Vamos tornar os dados tidy, isto é, a coluna vai ser referir à variável de interesse (foco de queimadas) e as colunas que representam a data de cada observação (uma coluna de data com o tipo datetime do pandas, e colunas categóricas representando o mês e ano dos valores).
# Remover as linhas de Máximo, Média e Mínimo
df = dados_brutos[~dados_brutos['Unnamed: 0'].isin(['Máximo*', 'Média*', 'Mínimo*'])]
# Transformar a coluna 'Unnamed: 0' em tipo inteiro para manipular o ano
df['Unnamed: 0'] = df['Unnamed: 0'].astype(int)
# Converter os dados de wide para long, juntando meses com anos
df_long = pd.melt(df,
id_vars = ['Unnamed: 0'],
value_vars = df.columns[1:-1],
var_name = 'Mês',
value_name = 'Valor')
# Renomear a coluna de 'Unnamed: 0' para 'Ano'
df_long.rename(columns={'Unnamed: 0': 'Ano'}, inplace=True)C:\Users\Dell\AppData\Local\Temp\ipykernel_24936\2749955312.py:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['Unnamed: 0'] = df['Unnamed: 0'].astype(int)# Dicionário para mapear os meses em português para seus números correspondentes
mes_map = {
'Janeiro': '01', 'Fevereiro': '02', 'Março': '03', 'Abril': '04',
'Maio': '05', 'Junho': '06', 'Julho': '07', 'Agosto': '08',
'Setembro': '09', 'Outubro': '10', 'Novembro': '11', 'Dezembro': '12'
}queimadas_df = (
df_long
.assign(Mes = df_long['Mês'].map(mes_map)) # Substituir os nomes dos meses pelos números
.assign(data = lambda x: pd.to_datetime(x['Ano'].astype(str) + '-' + x['Mes'], format='%Y-%m')) # Criar e converter a coluna 'Ano-Mês' para datetime
.sort_values(by='data') # Ordenar o DataFrame pela coluna 'Ano-Mês'
.reset_index(drop=True) # Resetar o índice
.dropna() # retira dados faltantes
.query("data >= '1999-01-01'") # filtra dados a partir de 1999
)# Exibir o resultado
queimadas_df.head()| Ano | Mês | Valor | Mes | data | |
|---|---|---|---|---|---|
| 12 | 1999 | Janeiro | 1081.0 | 01 | 1999-01-01 |
| 13 | 1999 | Fevereiro | 1284.0 | 02 | 1999-02-01 |
| 14 | 1999 | Março | 667.0 | 03 | 1999-03-01 |
| 15 | 1999 | Abril | 717.0 | 04 | 1999-04-01 |
| 16 | 1999 | Maio | 1811.0 | 05 | 1999-05-01 |
Análise de dados
Gráfico de Linha
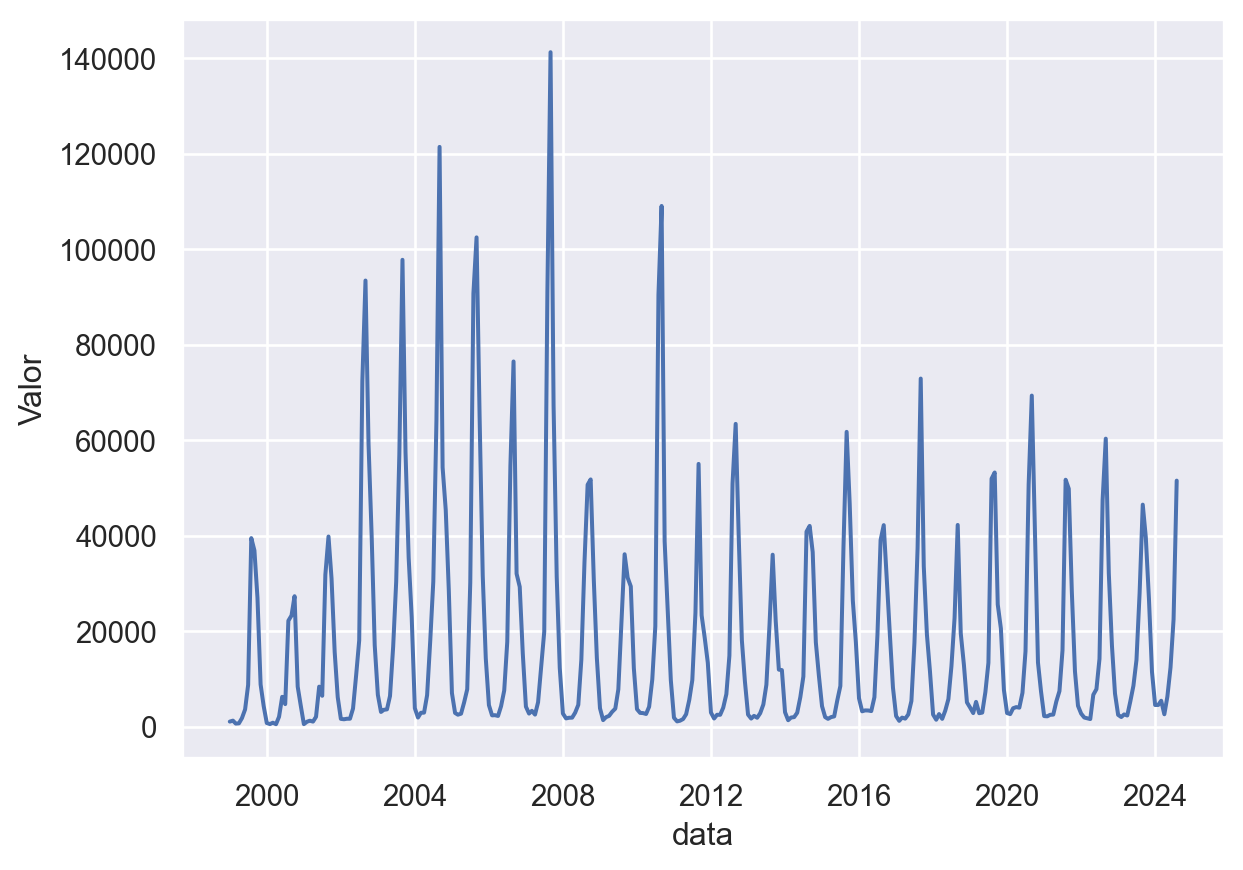
O gráfico de linha mostra uma clara sazonalidade nos dados de queimadas, com picos nos meses de julho e agosto, e um período de menor atividade no início do ano. Também é possível observar uma tendência de crescimento geral no número de focos de queimadas em determinados anos da década de 2000.
sns.lineplot(x = queimadas_df['data'], y = queimadas_df['Valor'])
Estatísticas Descritivas
As tabelas de estatísticas descritivas fornecem um resumo numérico dos dados de queimadas, ajudando a entender a distribuição e as características principais da série temporal. Vamos analisar cada tabela:
# Amostra
queimadas_df['Valor'].describe()count 308.000000
mean 18320.396104
std 23137.121209
min 538.000000
25% 2825.750000
50% 7535.500000
75% 27095.750000
max 141220.000000
Name: Valor, dtype: float64Essa tabela descreve as estatísticas gerais da coluna “Valor”, que representa o número de focos de queimadas.
- count: Indica o número total de observações (308.000), ou seja, o número de registros de focos de queimadas no período analisado.
- mean: A média dos focos de queimadas é de 18.320, o que significa que, em média, houve cerca de 18320 focos de queimadas por mês.
- std: O desvio padrão é de 23.137, indicando a dispersão dos dados em torno da média. Um desvio padrão alto sugere que os valores variam bastante.
- min: O valor mínimo de focos de queimadas registrado foi de 538.
- 25%: O primeiro quartil (25%) representa o valor abaixo do qual estão 25% dos dados. Neste caso, 25% dos meses tiveram menos de 2.825 focos de queimadas.
- 50%: A mediana (50%) é o valor que divide a série temporal em duas partes iguais. Neste caso, 50% dos meses tiveram menos de 7.535 focos de queimadas.
- 75%: O terceiro quartil (75%) representa o valor abaixo do qual estão 75% dos dados. Neste caso, 75% dos meses tiveram menos de 27.095 focos de queimadas.
- max: O valor máximo de focos de queimadas registrado foi de 141.220.
# Mensal
queimadas_df.groupby('Mês')['Valor'].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Mês | ||||||||
| Abril | 26.0 | 2230.076923 | 829.411788 | 538.0 | 1688.00 | 2279.5 | 2664.00 | 4117.0 |
| Agosto | 26.0 | 47143.653846 | 21014.802002 | 21410.0 | 32486.25 | 44176.0 | 53956.25 | 91085.0 |
| Dezembro | 25.0 | 11536.680000 | 5852.824338 | 4376.0 | 7408.00 | 11515.0 | 14332.00 | 28639.0 |
| Fevereiro | 26.0 | 2068.000000 | 872.555282 | 562.0 | 1416.00 | 1931.5 | 2735.00 | 4566.0 |
| Janeiro | 26.0 | 3279.038462 | 1643.529068 | 547.0 | 2313.25 | 2922.0 | 4172.50 | 7057.0 |
| Julho | 26.0 | 15672.038462 | 7098.407965 | 4740.0 | 9958.25 | 14540.0 | 18951.50 | 30391.0 |
| Junho | 26.0 | 7976.538462 | 3614.205763 | 3632.0 | 5667.75 | 7183.5 | 8549.00 | 18024.0 |
| Maio | 26.0 | 3923.384615 | 1508.399790 | 1811.0 | 2865.75 | 3591.0 | 5111.00 | 6698.0 |
| Março | 26.0 | 2501.807692 | 1154.557197 | 667.0 | 1814.25 | 2463.5 | 2911.75 | 5448.0 |
| Novembro | 25.0 | 22550.680000 | 9791.408205 | 8399.0 | 15640.00 | 19334.0 | 29396.00 | 45364.0 |
| Outubro | 25.0 | 38498.520000 | 13670.745990 | 19568.0 | 28342.00 | 33607.0 | 46741.00 | 67228.0 |
| Setembro | 25.0 | 64935.080000 | 30190.486548 | 23293.0 | 42209.00 | 55031.0 | 76475.00 | 141220.0 |
Essa tabela agrupa as estatísticas descritivas por mês, mostrando a variação do número de focos de queimadas ao longo do ano.
Observando essa tabela, podemos identificar os meses com maior média de focos de queimadas (como Setembro, Agosto e Outubro) e os meses com menor média (como Fevereiro, Abril e Março). Também podemos observar a variabilidade dos dados em cada mês, através do desvio padrão.
# Anual
queimadas_df.groupby('Ano')['Valor'].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Ano | ||||||||
| 1999 | 12.0 | 11217.666667 | 14575.194534 | 667.0 | 1233.25 | 4004.0 | 13401.50 | 39492.0 |
| 2000 | 12.0 | 8460.833333 | 9918.891377 | 538.0 | 830.50 | 4602.5 | 11850.25 | 27332.0 |
| 2001 | 12.0 | 12123.666667 | 14154.922089 | 547.0 | 1220.50 | 6344.0 | 19489.75 | 39829.0 |
| 2002 | 12.0 | 26784.500000 | 31948.491034 | 1569.0 | 1681.75 | 13968.0 | 44749.00 | 93417.0 |
| 2003 | 12.0 | 28436.416667 | 29414.077151 | 3099.0 | 5746.75 | 19866.0 | 40816.75 | 97758.0 |
| 2004 | 12.0 | 31703.750000 | 35588.112229 | 1932.0 | 3651.25 | 23331.5 | 47596.00 | 121395.0 |
| 2005 | 12.0 | 30213.583333 | 36033.141357 | 2528.0 | 4530.75 | 11093.0 | 39979.00 | 102455.0 |
| 2006 | 12.0 | 20764.916667 | 23763.389498 | 2269.0 | 3841.25 | 11507.5 | 29987.25 | 76475.0 |
| 2007 | 12.0 | 32826.250000 | 44308.582329 | 2550.0 | 4000.00 | 12518.0 | 40372.75 | 141220.0 |
| 2008 | 12.0 | 17661.083333 | 19278.789704 | 1751.0 | 2559.25 | 9311.5 | 31650.75 | 51784.0 |
| 2009 | 12.0 | 12925.166667 | 13055.569127 | 1396.0 | 2926.00 | 5849.0 | 23685.50 | 36116.0 |
| 2010 | 12.0 | 26615.250000 | 36111.900313 | 2681.0 | 3489.25 | 9827.5 | 27749.25 | 109030.0 |
| 2011 | 12.0 | 13174.916667 | 15743.912933 | 1127.0 | 1820.25 | 7697.5 | 19740.75 | 55031.0 |
| 2012 | 12.0 | 18102.833333 | 21313.815604 | 1728.0 | 2860.75 | 8174.5 | 23550.50 | 63408.0 |
| 2013 | 12.0 | 10678.750000 | 10818.583575 | 1715.0 | 2478.75 | 6729.5 | 14318.00 | 36019.0 |
| 2014 | 12.0 | 14657.666667 | 15953.321406 | 1371.0 | 2704.25 | 8370.5 | 22392.25 | 42049.0 |
| 2015 | 12.0 | 18064.833333 | 20592.690861 | 1659.0 | 2133.25 | 7055.0 | 29279.00 | 61739.0 |
| 2016 | 12.0 | 15351.416667 | 14628.063033 | 3238.0 | 3420.75 | 7195.5 | 22133.75 | 42209.0 |
| 2017 | 12.0 | 17292.333333 | 21572.557274 | 1239.0 | 2169.75 | 8519.0 | 22902.25 | 72895.0 |
| 2018 | 12.0 | 11072.500000 | 12189.556338 | 1476.0 | 2631.00 | 5451.5 | 14652.50 | 42251.0 |
| 2019 | 12.0 | 16469.333333 | 18379.465609 | 2842.0 | 3763.25 | 7479.0 | 21842.00 | 53234.0 |
| 2020 | 12.0 | 18566.416667 | 22480.645807 | 2657.0 | 3971.50 | 7258.5 | 22220.00 | 69329.0 |
| 2021 | 12.0 | 15340.083333 | 18220.715840 | 2187.0 | 2536.25 | 6379.0 | 19074.25 | 51711.0 |
| 2022 | 12.0 | 16730.250000 | 19611.507179 | 1616.0 | 2552.00 | 7414.5 | 20766.00 | 60313.0 |
| 2023 | 12.0 | 15827.166667 | 15640.357313 | 2035.0 | 2562.25 | 10056.0 | 27132.00 | 46498.0 |
| 2024 | 8.0 | 13742.875000 | 16570.247696 | 2613.0 | 4563.25 | 5886.0 | 14943.50 | 51527.0 |
Essa tabela agrupa as estatísticas descritivas por ano, mostrando a evolução do número de focos de queimadas ao longo do tempo.
Essa tabela permite observar a tendência geral do número de focos de queimadas ao longo dos anos, mostrando se há um aumento, diminuição ou estabilidade. Também podemos identificar os anos com maior e menor média de focos de queimadas, e a variabilidade dos dados em cada ano.
Histograma
O histograma mostra que a distribuição dos dados de queimadas é assimétrica, com uma cauda longa à direita, indicando que há uma maior frequência de valores baixos e alguns valores altos.
sns.histplot(queimadas_df['Valor'])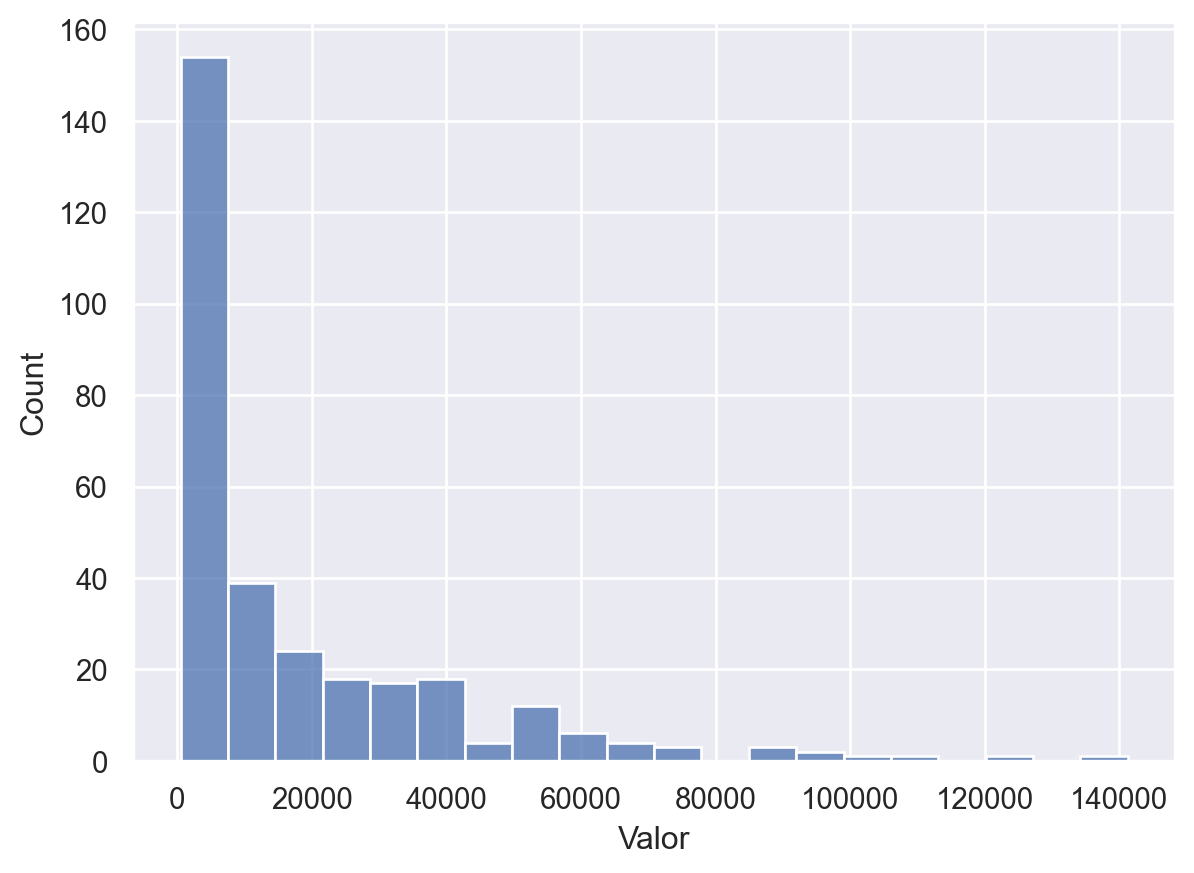
Sazonalidade
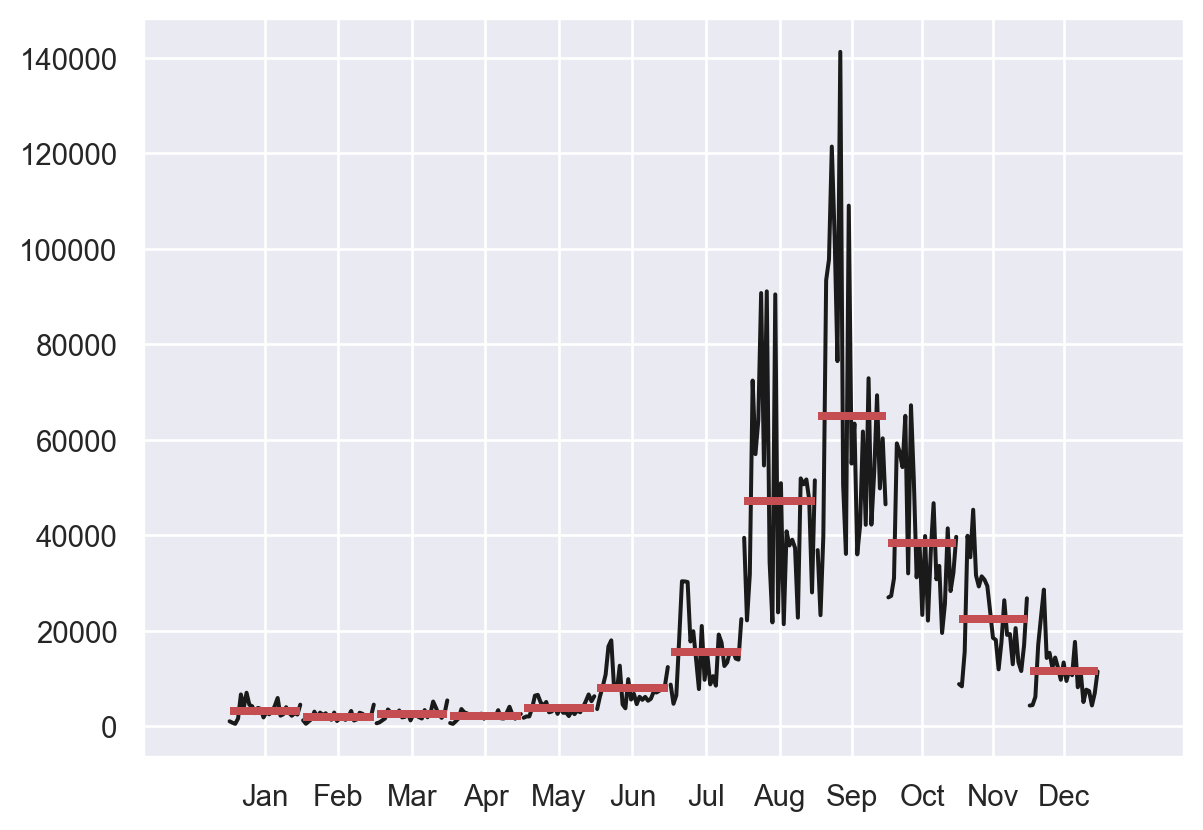
O gráfico de sazonalidade confirma a sazonalidade observada no gráfico de linha, com picos nos meses de julho e agosto, e um período de menor atividade no início do ano.
queimadas_df.index = pd.DatetimeIndex(queimadas_df.data, freq='MS')sm.graphics.tsa.month_plot(queimadas_df.Valor);
Violin Plot
O violin plot mostra a distribuição dos dados de queimadas em diferentes meses do ano. É possível observar que a distribuição dos dados é mais concentrada nos meses de julho e agosto, com uma maior variabilidade nos meses de setembro e outubro.
mes = queimadas_df.Mes.unique()
labels = list(queimadas_df['Mês'].unique())valores_mes = [queimadas_df.Valor[queimadas_df.Mes == id] for id in mes]plt.rcParams['figure.subplot.bottom'] = 0.23
fig = plt.figure()
ax = fig.add_subplot(111)
sm.graphics.violinplot(valores_mes, ax=ax, labels=labels,
plot_opts={'cutoff_val':5, 'cutoff_type':'abs',
'label_fontsize':'small',
'label_rotation':30})
ax.set_xlabel("")
ax.set_ylabel("")
plt.show()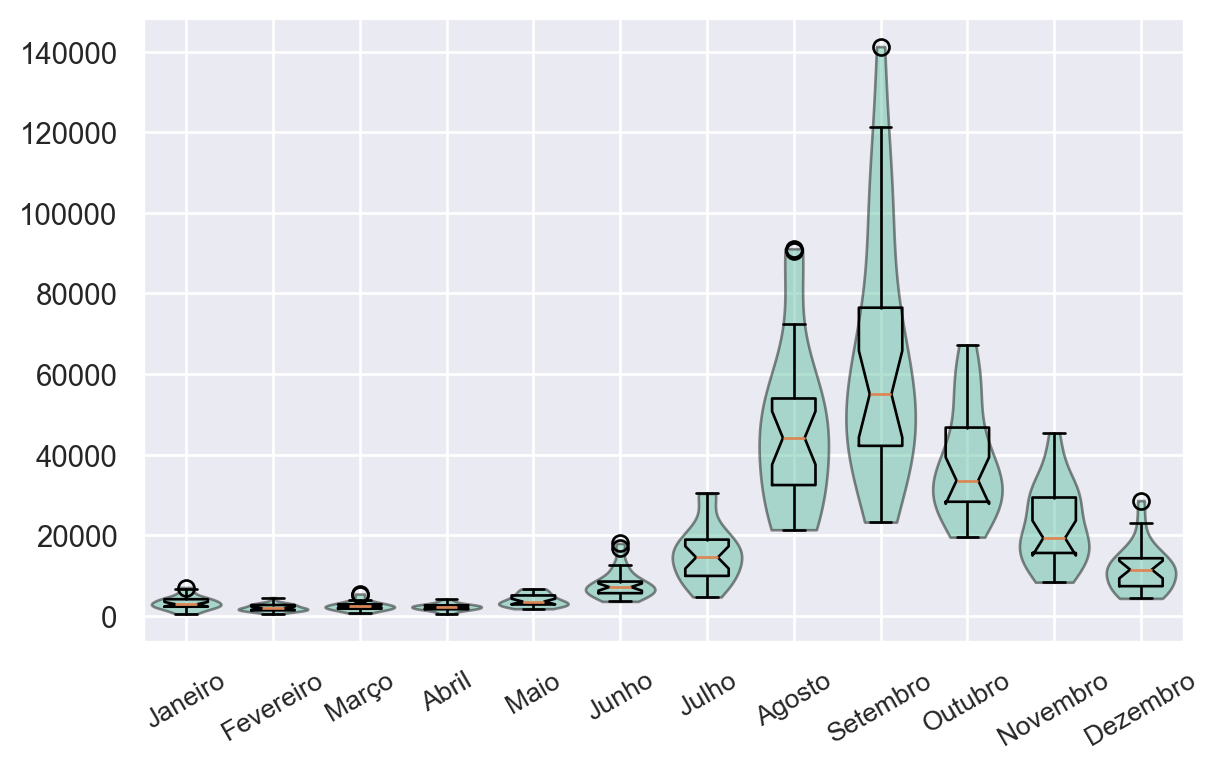
Decomposição
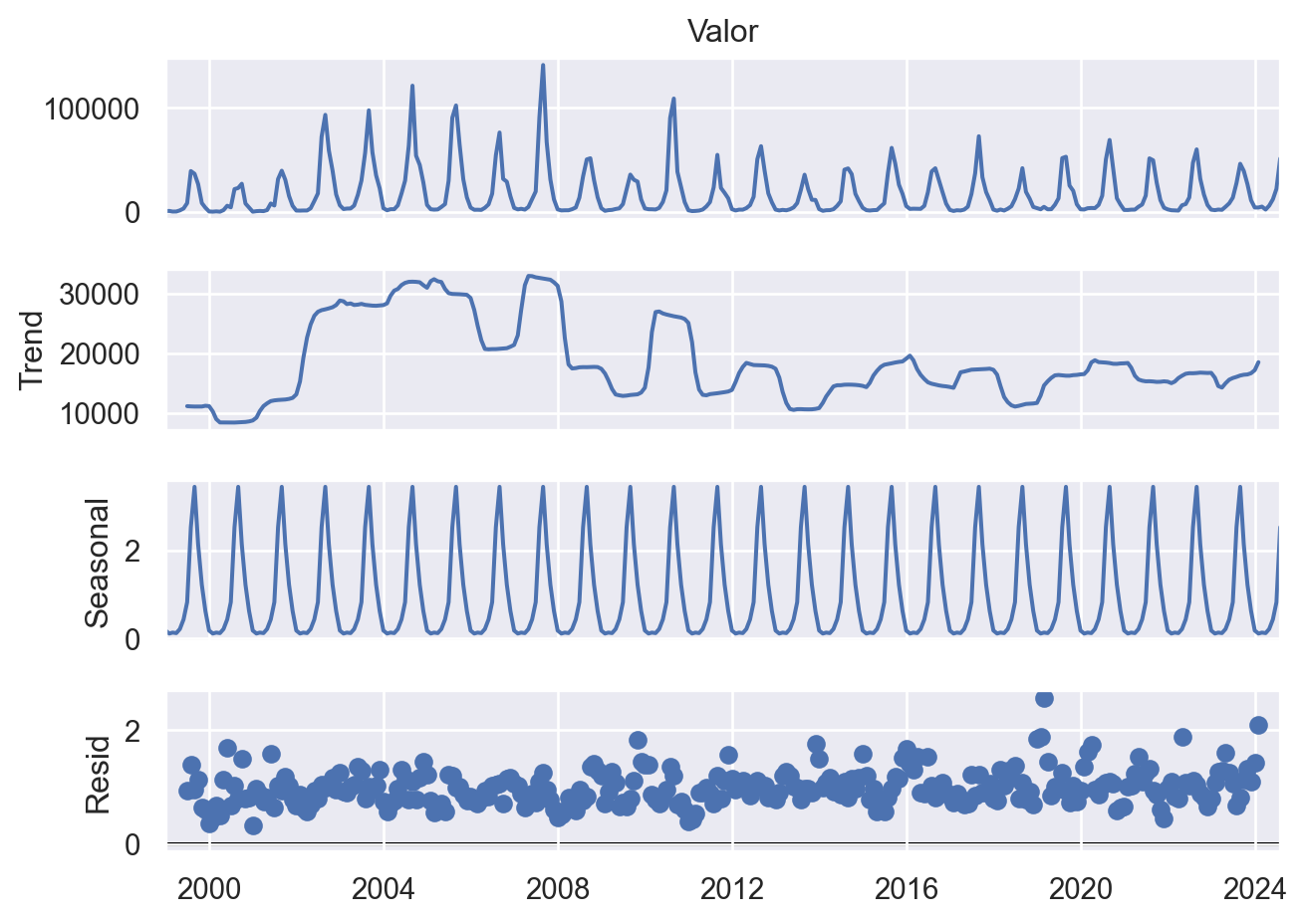
A decomposição da série temporal em seus componentes (tendência, sazonalidade e resíduos) permite uma análise mais detalhada dos padrões presentes nos dados. O componente de tendência mostra um crescimento gradual no número de focos de queimadas ao longo do tempo. O componente de sazonalidade destaca os picos nos meses de julho e agosto. O componente de resíduos representa a variabilidade aleatória dos dados.
decomposicao = seasonal_decompose(queimadas_df['Valor'], model = 'multiplicative') decomposicao.plot();
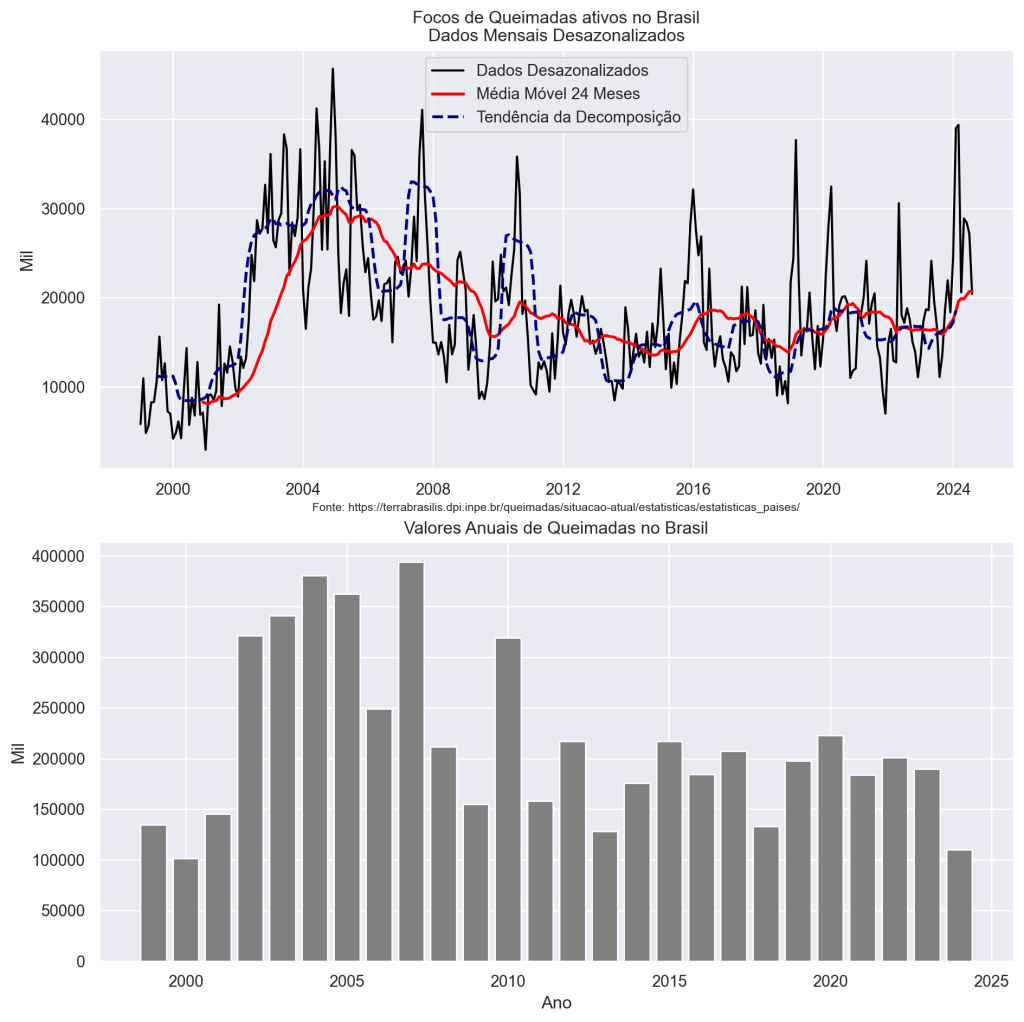
Dessazonalizar e Média Móvel
A dessazonalização e a média móvel permitem uma análise da tendência de longo prazo, removendo a influência da sazonalidade. O gráfico mostra que a tendência de crescimento no número de focos de queimadas se mantém mesmo após a dessazonalização.
Os gráficos finais mostram os dados dessazonalizados, a média móvel e os valores anuais de queimadas. O gráfico dos dados dessazonalizados mostra a tendência de crescimento no número de focos de queimadas, sem a influência da sazonalidade. O gráfico da média móvel suaviza a série temporal, facilitando a visualização da tendência de longo prazo. O gráfico dos valores anuais de queimadas mostra a evolução do número de focos de queimadas ao longo dos anos. É possível confirmar a trajetória da série, livre de efeitos sazonais comparando os valores anuais com os dados ajustados pela sazonalidade.
Em 2024, em particular, podemos verificar o aumento na tendência do foco de queimadas nos meses recentes, o que é um ponto de preocupação.
# Remover a sazonalidade
desazonalizado = queimadas_df['Valor'] / decomposicao.seasonal
# Calcular a média móvel de 24 meses
media_movel = desazonalizado.rolling(window=24).mean()
# Agrupar os valores anuais de queimadas
queimadas_anuais = queimadas_df.groupby('Ano')['Valor'].sum()
# Criar a figura com subplots
fig, axs = plt.subplots(2, 1, figsize=(10, 10))
# Gráfico 1: Dados desazonalizados com média móvel
axs[0].plot(desazonalizado, label='Dados Desazonalizados', color='black')
axs[0].plot(media_movel, label='Média Móvel 24 Meses', color='red', linewidth=2)
axs[0].plot(decomposicao.trend, label='Tendência da Decomposição', color='darkblue', linewidth=2, linestyle='dashed')
axs[0].set_title('Focos de Queimadas ativos no Brasil\nDados Mensais Desazonalizados')
axs[0].set_ylabel('Mil')
axs[0].legend()
axs[0].grid(True)
# Anotação da fonte
axs[0].annotate('Fonte: https://terrabrasilis.dpi.inpe.br/queimadas/situacao-atual/estatisticas/estatisticas_paises/',
xy=(0.5, -0.1), xycoords='axes fraction', ha='center', fontsize=8)
# Gráfico 2: Valores anuais de queimadas
axs[1].bar(queimadas_anuais.index, queimadas_anuais.values, color='gray')
axs[1].set_title('Valores Anuais de Queimadas no Brasil')
axs[1].set_xlabel('Ano')
axs[1].set_ylabel('Mil')
axs[1].grid(True)
# Ajustar layout
plt.tight_layout()
# Exibir o gráfico
plt.show()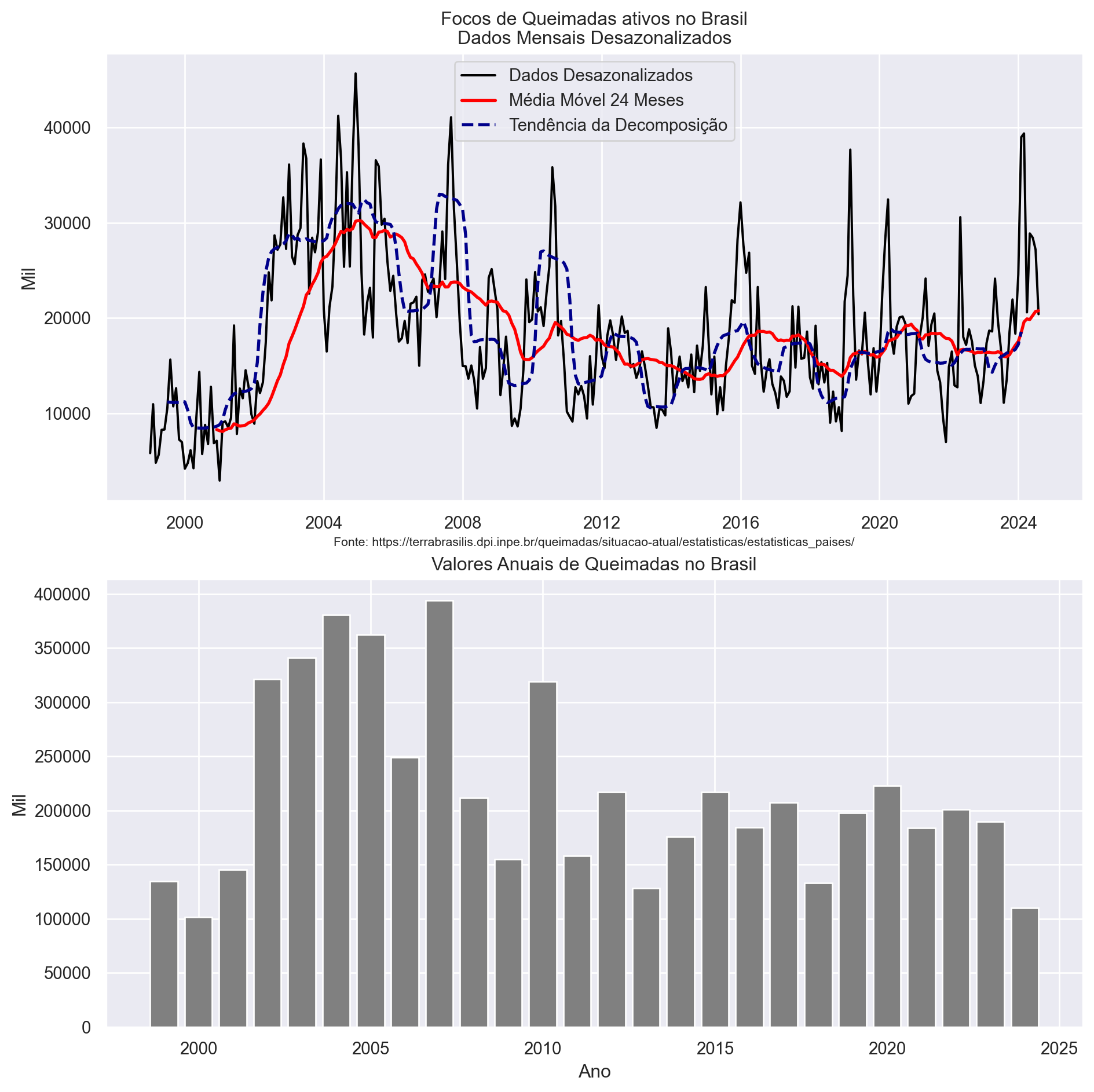
Conclusões
A análise dos dados de queimadas no Brasil revela uma clara sazonalidade, com picos nos meses de julho e agosto, e uma tendência de crescimento geral no número de focos de queimadas na década de 2000, com eventual queda no início de 2010, com preocupação de elevação no meses recentes de 2024.
É importante destacar que esta análise se baseia em dados coletados por satélite, em agregação mensal e para todo o território brasileiro, o que pode apresentar limitações em termos de precisão e abrangência. Além disso, a análise não considera outros fatores que podem influenciar o número de focos de queimadas, como as condições climáticas, a atividade humana e as políticas de controle de queimadas.
Para uma análise mais completa, seria necessário considerar outros dados e fatores, além de realizar estudos mais aprofundados sobre as causas e consequências das queimadas no Brasil.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

