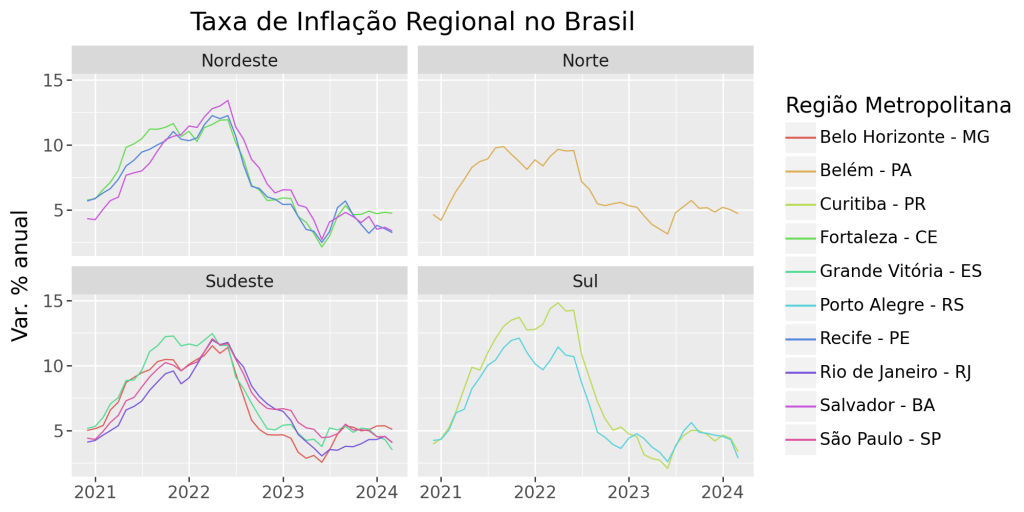
Os dados desagregados do IPCA fornecem informações detalhadas sobre o comportamento de preços no Brasil a nível de região metropolitana e município, possibilitando ricas análises regionais de dados. Neste artigo mostramos como acessar, processar e analisar estes dados utilizando o Python.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados Econômicos e Financeiros com Python.
Passo 01: buscando dados no portal Sidra/IBGE
- Acesse o site https://sidra.ibge.gov.br/
- Clique em “IPCA”
- Clique no ícone ao lado do mês/ano chamado “Relação de tabelas da pesquisa”
- Clique em uma tabela que possua dados regionais (ex: “7060”)
- Aplique filtros na página da tabela para obter dados de interesse (ex: tipo de indicador, variação, grupo, subitem, período e nível territorial)
- Clique no botão com símbolo de link no canto inferior direito da tela chamado “Links para compartilhar”
- Copie o link informado no campo “Parâmetros para a API” (ex: https://apisidra.ibge.gov.br/values/t/7060/n7/all/v/2265/p/all/c315/7169/d/v2265%202)
Passo 02: coleta, tratamento e análise de dados
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
- Abrir o Python (ex: acesse o Google Colab pelo endereço https://www.colab.new/)
- Importe as bibliotecas pandas e plotnine
- Colete os dados usando o link copiado na página do Sidra (adicione o termo “?formato=json” no final do link)
- Aplique os tratamentos necessários utilizando a biblioteca pandas
data rm gr valor 12 2020-12-01 Belém - PA Norte 4.63 13 2021-01-01 Belém - PA Norte 4.18 14 2021-02-01 Belém - PA Norte 5.42 15 2021-03-01 Belém - PA Norte 6.44 16 2021-04-01 Belém - PA Norte 7.32 - Produza sua análise de dados visualmente utilizando a biblioteca plotnine

Conclusão
Os dados desagregados do IPCA fornecem informações detalhadas sobre o comportamento de preços no Brasil a nível de região metropolitana e município, possibilitando ricas análises regionais de dados. Neste artigo mostramos como acessar, processar e analisar estes dados utilizando o Python.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

