A previsão quantitativa é um processo fundamental para tomada de decisões em economia e finanças. Ela envolve a coleta de dados relevantes, a aplicação de modelos e a apresentação de resultados. No entanto, esse processo pode ser demorado e exigir um grande esforço manual, o que pode levar a erros e atrasos na tomada de decisão.
A boa notícia é que a ciência de dados pode ajudar a automatizar esse processo de previsão quantitativa, permitindo que as empresas e os gestores tomem decisões mais rápidas e precisas. Neste exercício, vamos mostrar a aplicação do ciclo completo da ciência de dados para prever, como exemplo, o Produto Interno Bruto (PIB) do Brasil usando a linguagem de programação R e o GitHub Actions para automatização.
Vamos começar explicando o que é o ciclo completo de ciência de dados e como ele pode ser aplicado ao problema de previsão quantitativa. Em seguida, vamos mostrar os resultados das etapas do ciclo, que envolvem coletar as variáveis necessárias para a previsão do PIB, aplicar modelos para previsão e apresentar os resultados de forma clara e objetiva. Nofinal, mostramos que o GitHub Actions pode ser utilizado para automatizar todo o processo de previsão, permitindo que as previsões sejam atualizadas sem processos manuais sempre que novos dados estiverem disponíveis.
O ciclo da ciência de dados
O ciclo de vida da ciência de dados é uma metodologia que descreve as etapas fundamentais de um projeto de ciência de dados, desde a declaração do problema até a tomada de decisão e implantação. A seguir, vamos explicar cada uma das etapas e como elas podem ser aplicadas ao problema de previsão quantitativa.
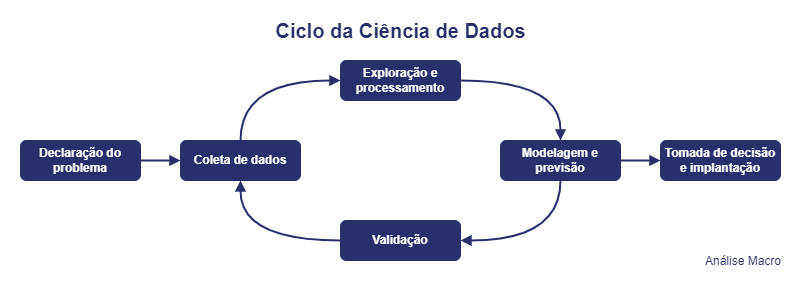
- Declaração do problema: Essa etapa envolve a identificação do problema que será abordado e a definição dos objetivos do projeto. No caso da previsão quantitativa do PIB do Brasil, o problema seria a previsão do crescimento econômico para os próximos trimestres.
- Coleta de dados: Nessa etapa, são coletados os dados necessários para a análise, que no caso da previsão do PIB poderiam incluir dados macroeconômicos como taxa de juros, taxa de câmbio, inflação, entre outros.
- Exploração e processamento de dados: Nessa etapa, os dados são explorados e pré-processados para garantir que estejam prontos para a modelagem. Isso pode incluir a análise da distribuição dos dados, detecção de valores ausentes e tratamento de outliers.
- Modelagem e previsão: Nessa etapa, são aplicados modelos para fazer a previsão do PIB com base nos dados coletados e processados. Existem várias técnicas de modelagem que podem ser utilizadas, como modelos ARIMA, redes neurais, entre outros.
- Validação: Nessa etapa, a precisão do modelo é avaliada e validada para garantir que as previsões são precisas e confiáveis. Isso pode ser feito usando técnicas de validação cruzada ou outras métricas de avaliação de modelo.
- Tomada de decisão e implantação: Nessa etapa, as previsões são apresentadas aos tomadores de decisão e, se aprovadas, são implementadas na empresa ou organização. No caso da previsão do PIB, as previsões poderiam ser usadas para orientar as decisões de investimento e de política econômica.
Portanto, a aplicação do ciclo completo de ciência de dados pode ajudar a automatizar o processo de previsão quantitativa do PIB do Brasil, desde a coleta de dados até a apresentação dos resultados. Ao utilizar ferramentas de programação e automatização como GitHub Actions, é possível atualizar as previsões automaticamente sempre que novos dados estiverem disponíveis, tornando o processo ainda mais eficiente e preciso.
Exemplo prático de previsão quantitativa
Para a parte prática de implementar o ciclo de ciência de dados, usando como exemplo a previsão quantitativa do PIB do Brasil, podemos utilizar diversas ferramentas úteis e que são ensinadas nos cursos aplicados de R e Python da Análise Macro.
Linguagens de programação open-source como o R e o Python podem ajudar em todo o processo, facilitando a automatização de cada etapa, e possuem uma grande quantidade de pacotes e ferramentas disponíveis para rápido e fácil uso. Por fim, pode ser utilizado o GitHub Actions para automatizar toda a implementação do ciclo e pode ser interessante gerar uma dashboard ou relatório no final, como essa dashboard simples abaixo (uma prova de conceito):
Link para acessar a dashboard: https://analisemacropro.github.io/auto_previsao/dashboard/previsao_pib.html
Conclusão
Em resumo, a utilização de linguagens de programação como o R ou Python e ferramentas como o GitHub Actions podem ajudar a aplicar todas as etapas do ciclo completo de ciência de dados de forma eficiente e escalável, permitindo a criação de modelos mais precisos e uma tomada de decisão mais informada.
Códigos de reprodução em R deste exercício estão disponíveis para membros do Clube AM da Análise Macro.

