Anualmente as queimadas devastam a fauna e a flora do Brasil em diversas regiões, atingindo níveis mais extremos nos anos recentes. Os reflexos destes eventos são sentidos tanto na cadeia produtiva do país, pela destruição de safras, quanto na qualidade do ar, pela concentração de fumaça, e, portanto, na vida cotidiana dos brasileiros.
Dado o perigo de afetar a dinâmica econômica e a saúde da população, torna-se imperativo monitorar e analisar os dados de queimadas no Brasil, possibilitando a ação através de medidas corretivas ou preventivas. Apesar do noticiário diário sobre o assunto, pouco se fala sobre a origem e a análise dos dados que possibilitem ações.
Neste artigo exploramos fontes públicas de dados sobre secas e queimadas no Brasil. Mostramos como acessar, coletar e preparar os dados para elaboração de análises. Usamos a linguagem Python para desenvolver uma rotina automatizada.
Fontes de dados
No Brasil existem algumas instituições do governo/academia que monitoram as queimadas no Brasil e disponibilizam os dados:
- Instituto Nacional de Pesquisas Espaciais (INPE), através do Programa Queimadas, disponibiliza dados sobre focos de fogo identificados por satélites, além de área queimada, área desmatada, riscos de queimada, dentre outros.
- Laboratório de Aplicações de Satélites Ambientais da Universidade Federal do Rio de Janeiro (Lasa-UFRJ) publicam dados sobre área queimada e perigo de fogo identificados por satélite em tempo quase real.
Os dados costumam, quando muito, ser disponibilizados através de arquivos CSV para download. Na falta desta opção, o interessado deve verificar a possibilidade de web scraping.
Coleta de dados
Vamos demonstrar como coletar dados de queimadas no Brasil provenientes do INPE, através do seu Programa Queimadas. Todos os dados disponíveis estão no endereço https://terrabrasilis.dpi.inpe.br/queimadas/portal/dados-abertos/.
- Exemplo 1: focos de queimadas diário no Brasil.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
- Exemplo 2: focos de queimadas mensal no Brasil.
- Exemplo 3: área queimada mensal no Brasil.
| Ano | Mês | Amazônia | Caatinga | Cerrado | Mata Atlântica | Pampa | Pantanal | Total mensal | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2002 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 2002 | 2.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 2002 | 3.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 2002 | 4.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 2002 | 5.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 290 | 2024 | 5.0 | 2014.0 | 430.0 | 11482.0 | 2210.0 | 12.0 | 390.0 | 16538.0 |
| 291 | 2024 | 6.0 | 3400.0 | 1114.0 | 23250.0 | 6755.0 | 0.0 | 4704.0 | 39223.0 |
| 292 | 2024 | 7.0 | 8664.0 | 1754.0 | 18706.0 | 7257.0 | 28.0 | 1820.0 | 38229.0 |
| 293 | 2024 | 8.0 | 36022.0 | 4870.0 | 49070.0 | 11945.0 | 157.0 | 8640.0 | 110704.0 |
| 294 | Total anual | NaN | 62268.0 | 9549.0 | 106677.0 | 29211.0 | 236.0 | 16440.0 | 224381.0 |
295 rows × 9 columns
Análise de dados
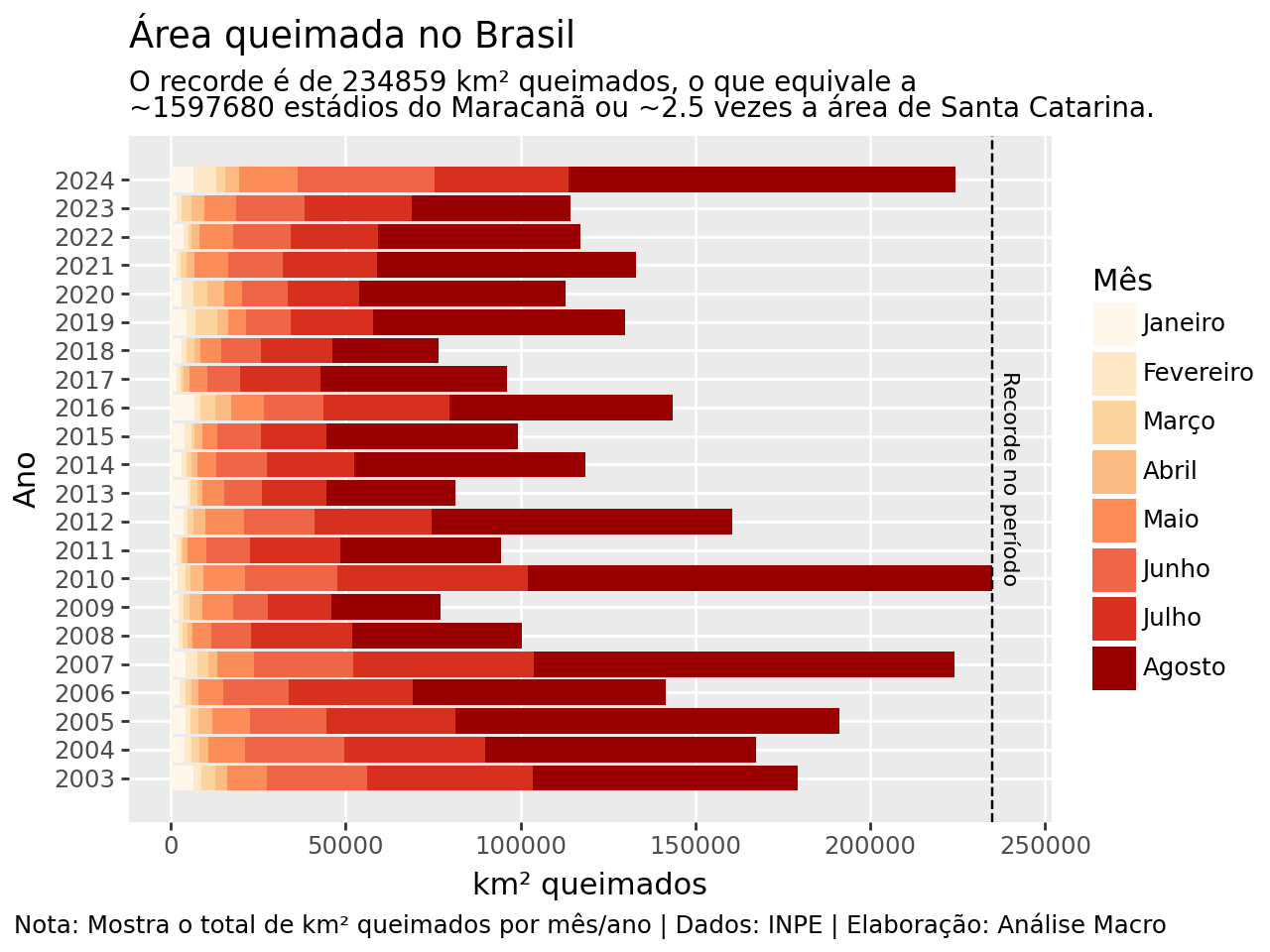
Uma vez que os dados tenham sido obtidos, é possível, unindo o conhecimento sobre a área e sobre séries temporais, produzir análises com esta abaixo:
Conclusão
Neste artigo exploramos fontes públicas de dados sobre secas e queimadas no Brasil. Mostramos como acessar, coletar e preparar os dados para elaboração de análises. Usamos a linguagem Python para desenvolver uma rotina automatizada.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

