Condições como a temperatura, umidade, radiação e pressão atmosférica podem influenciar diversos aspectos do nosso cotidiano. Desde a safra de grãos, no interior de Mato Grosso, até a decisão de um vendedor ambulante levar seu carrinho para a praia, no Rio de Janeiro, o monitoramento sobre o clima pode ajudar a tomar melhores decisões.
Neste exerício mostramos como coletar dados públicos sobre condições climáticas, possibilitando análises e monitoramento. Usamos a linguagem Python para todo o processo, permitindo rotinas automatizadas e ágeis.
Fontes de dados
No Brasil, uma das principais fontes de dados públicas sobre condições climática é o Instituto Nacional de Meteorologia (INMET), que disponibiliza dados históricos com relativa atualização sobre:
- Precipitação
- Pressão atmosférica
- Radiação
- Temperatura
- Umidade
- Vento
Os dados são disponibilizados para o nível de:
- Regiões
- Estados
- Municípios
Em uma granularidade de:
- Data
- Hora
A base de dados do INMET inicia em 2000 e possui dados até o ano corrente (usualmente, atualizado até o mês anterior). Para saber mais, acesse a base de dados em https://portal.inmet.gov.br/dadoshistoricos.
Coleta de dados
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Vamos mostrar um exemplo de coleta de dados sobre o clima para o ano de 2024 na cidade de Florianópolis-SC.
O arquivo de dados é compactado (zip) com uma série de tabelas CSV, então é necessário baixá-lo e extrair a tabela de interesse. A nomemclatura dos nomes de arquivos das tabelas segue um padrão como esse:
“INMET_{SIGLA REGIÃO}_{SIGLA ESTADO}_{CÓDIGO INTERNO}_{MUNICÍPIO}_{DATA INÍCIO}_A_{DATA FIM}.CSV”
onde entre chaves {} estão as informações de cada granularidade.
Para simplificar, buscamos o termo “florianopolis” na lista de arquivos e importamos o arquivo CSV encontrado:
Hora UTC ... Unnamed: 19
Data ...
2024-01-01 0000 UTC ... NaN
2024-01-01 0100 UTC ... NaN
2024-01-01 0200 UTC ... NaN
2024-01-01 0300 UTC ... NaN
2024-01-01 0400 UTC ... NaN
... ... ... ...
2024-08-31 1900 UTC ... NaN
2024-08-31 2000 UTC ... NaN
2024-08-31 2100 UTC ... NaN
2024-08-31 2200 UTC ... NaN
2024-08-31 2300 UTC ... NaN
[5856 rows x 19 columns]Análise de dados
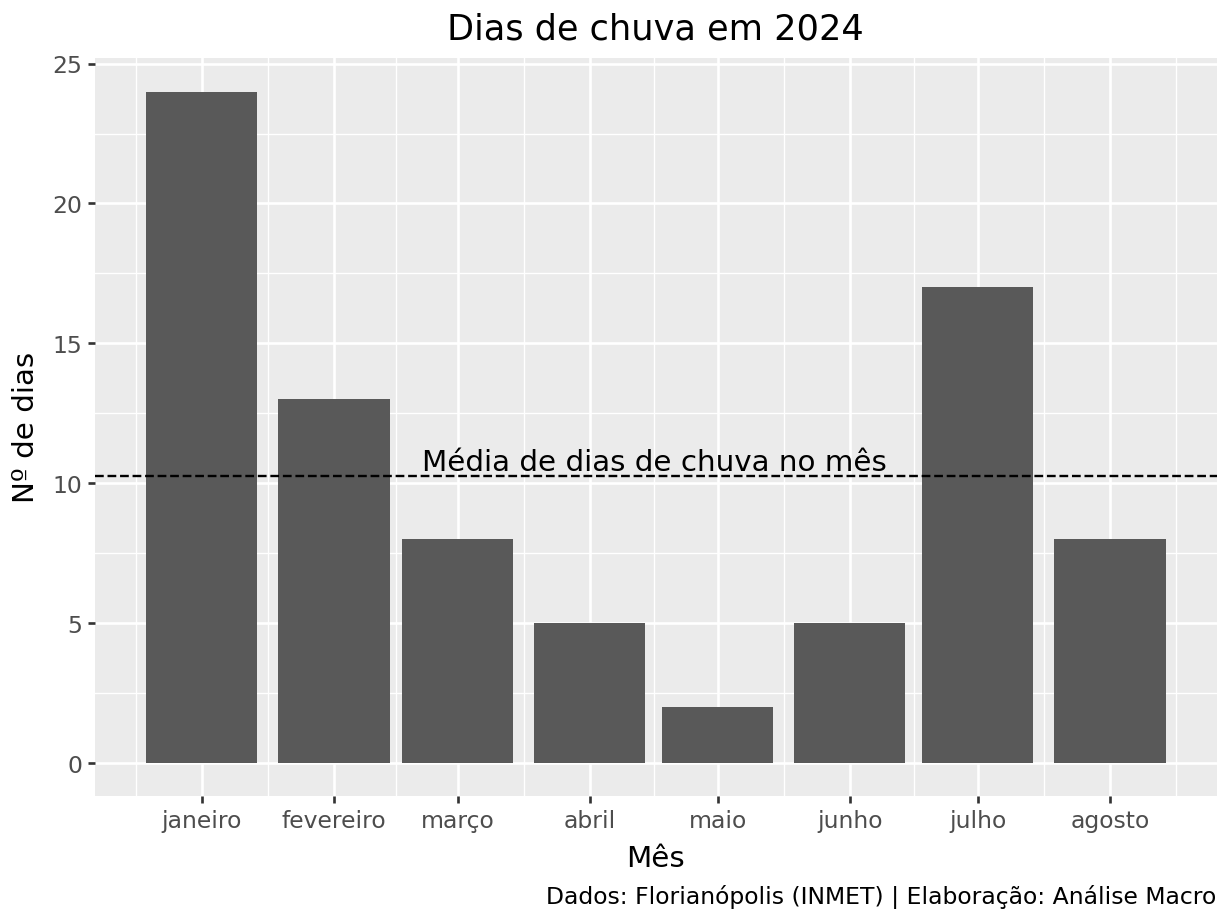
Uma vez que os dados tenham sido obtidos, é possível realizar análises interessantes, como o nº de dias de chuva por mês:
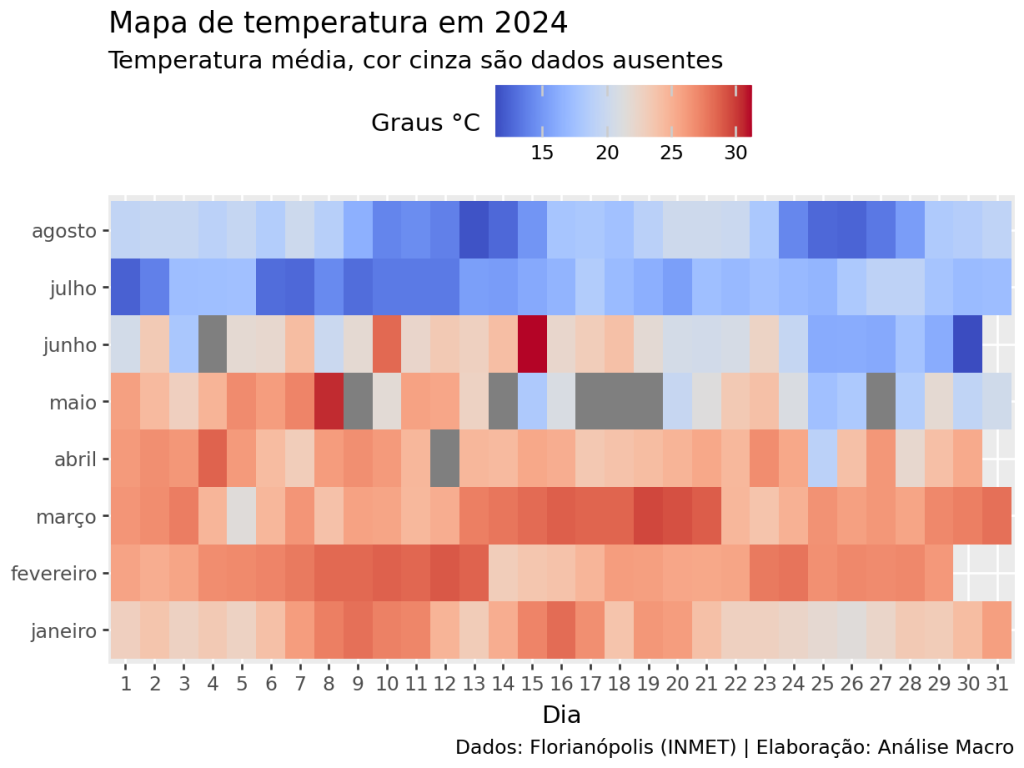
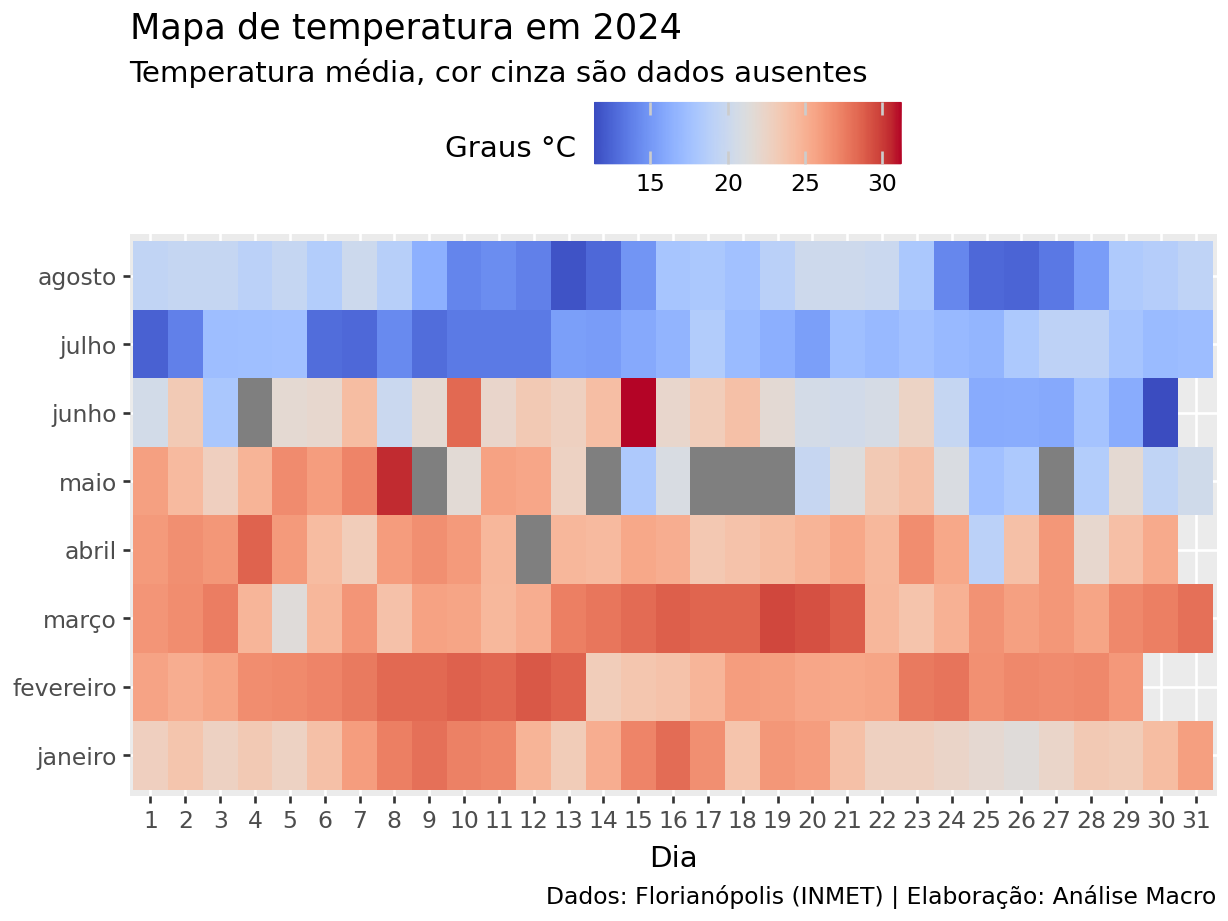
Ou, ainda, o mapa de temperatura média ao longo do ano:
Conclusão
As condições climatológicas influenciam desde a safra de grãos até a decisão de um vendedor ambulante levar seu carrinho para a praia ou não. Por sua importância e impactos na economia do país, neste exercício mostramos como coletar e elaborar análises de dados sobre o clima usando o Python.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

