Os dados regionais do CAGED permitem analisar o mercado de trabalho de forma detalhada, em termos de setores, educação, rendimento e características pessoais dos trabalhadores brasileiros. Neste exercício mostramos como acessar estas informações online via Python.
Importante: no momento atual, o acesso aos dados do CAGED só é permitido para conexões de internet do Brasil. Dessa forma, aplicativos como Google Colab não funcionarão.
Passo 01: acessar o FTP do CAGED
Abra o navegador de internet ou app compatível com navegação FTP e acesse o link: ftp://ftp.mtps.gov.br/pdet/microdados/NOVO%20CAGED/
Em seguida, navegue até o arquivo desejado. Exemplo para o CAGED de setembro/2024: ftp://ftp.mtps.gov.br/pdet/microdados/NOVO%20CAGED/2024/202409/CAGEDMOV202409.7z
Passo 02: baixar o arquivo
Agora abra o um Jupyter Notebook no VS Code e baixe o arquivo com o comando curl.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Passo 03: importar arquivo
Agora utilize um programa de descompactação, como o 7-Zip, do arquivo zipado para extrair o arquivo do CAGED e, então, importe a tabela de dados usando o pandas:
competênciamov região ... unidadesaláriocódigo valorsaláriofixo
0 202409 4 ... 5 1857.82
1 202409 4 ... 1 9.33
2 202409 3 ... 5 1694.00
3 202409 3 ... 5 0.00
4 202409 5 ... 5 663.39
[5 rows x 28 columns]Passo 04: tratamento/análise de dados
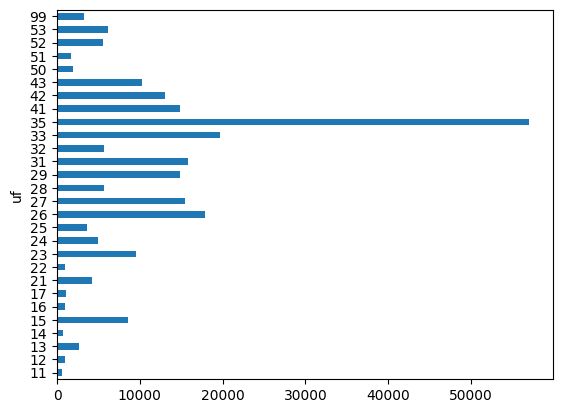
Por fim, basta realizar os processamentos e análises regionais desejadas. Aqui calculamos o número de vagas geradas no estado de Santa Catarina:
13074Conclusão
Os dados regionais do CAGED permitem analisar o mercado de trabalho de forma detalhada, em termos de setores, educação, rendimento e características pessoais dos trabalhadores brasileiros. Neste exercício mostramos como acessar estas informações online via Python.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, conheça o Clube AM clicando aqui.

