Dados em Excel frequentemente estão dispersos em múltiplos arquivos, mesmo que a informação seja sobre um mesmo indicador. Essa situação é comum em ambiente empresarial e em conjuntos de dados públicos do governo. No entanto, essa estrutura de dados dispersa não é muito favorável no dia a dia de análise de dados.
Neste artigo apresentamos uma forma simples de consolidar múltiplas planilhas de Excel em uma tabela única, facilitando análises de dados subsequentes. Criamos um código simples, em R e Python, que consolida diversas planilhas automaticamente, eliminando procedimentos manuais de tratamento de dados. Usamos como exemplo os dados desagregados do IPCA fornecidos pelo IBGE.
Dados de exemplo
Vamos utilizar os dados desagregados do IPCA fornecidos pelo IBGE neste link. Trata-se de informações sobre as variações e pesos do indicador de inflação desagregado por grupos, subgrupos, itens e subitens nas regiões metropolitanas e municípios em que a instituição coleta os dados.
A imagem abaixo mostra, como exemplo, a tabela de variação mensal do IPCA obtida no site do IBGE referente ao período de Dezembro/2022:

No site do IBGE existe uma tabela como essa para cada mês e ano. Após baixar e descompactar os dados do ano de 2022, temos os seguintes arquivos:
R
# Pacotes
library(stringr)
library(readxl)
library(dplyr)
library(purrr)
# Lista de arquivos
arquivos_xls <- paste0("dados/xls/", list.files(path = "dados/xls/"))
arquivos_xls <- setNames(
object = arquivos_xls,
nm = stringr::str_extract(string = arquivos_xls, pattern = "[:digit:]{1,6}")
)
arquivos_xls
202201 202202 "dados/xls/ipca_202201Subitem.xls" "dados/xls/ipca_202202Subitem.xls" 202203 202204 "dados/xls/ipca_202203Subitem.xls" "dados/xls/ipca_202204Subitem.xls" 202205 202206 "dados/xls/ipca_202205Subitem.xls" "dados/xls/ipca_202206Subitem.xls" 202207 202208 "dados/xls/ipca_202207Subitem.xls" "dados/xls/ipca_202208Subitem.xls" 202209 202210 "dados/xls/ipca_202209Subitem.xls" "dados/xls/ipca_202210Subitem.xls" 202211 202212 "dados/xls/ipca_202211Subitem.xls" "dados/xls/ipca_202212Subitem.xls"
Python
# Bibliotecas
import os
import pandas as pd
# Lista de arquivos
arquivos_xls = [os.path.join("dados/xls/", file) for file in os.listdir("dados/xls")]
arquivos_xls = dict(
zip(
pd.Series(arquivos_xls).str.extract("(\d{1,6})", expand = False).tolist(),
arquivos_xls
)
)
arquivos_xls
{'202201': 'dados/xls/ipca_202201Subitem.xls', '202202': 'dados/xls/ipca_202202Subitem.xls', '202203': 'dados/xls/ipca_202203Subitem.xls', '202204': 'dados/xls/ipca_202204Subitem.xls', '202205': 'dados/xls/ipca_202205Subitem.xls', '202206': 'dados/xls/ipca_202206Subitem.xls', '202207': 'dados/xls/ipca_202207Subitem.xls', '202208': 'dados/xls/ipca_202208Subitem.xls', '202209': 'dados/xls/ipca_202209Subitem.xls', '202210': 'dados/xls/ipca_202210Subitem.xls', '202211': 'dados/xls/ipca_202211Subitem.xls', '202212': 'dados/xls/ipca_202212Subitem.xls'}
Função para ler planilhas Excel
Como pode ser observado na imagem acima, as planilhas do IPCA/IBGE possuem alguns problemas. Apesar de serem planilhas padronizadas, alguns detalhes como o nome da primeira coluna ausente, a linha 6 em branco, células mescladas, etc., acabam demandando um trabalho adicional para consolidar os dados.
Tendo isso em vista, a função abaixo se encarrega de importar uma planilha qualquer dessa amostra, tomando como exemplo a folha de variações mensais, e aplicar os devidos tratamentos de dados para que o resultado seja uma tabela minimamente organizada:
R
# Função para ler dados de interesse da planilha Excel
ler_excel <- function(arquivo, periodo) {
tabela <- readxl::read_xls(
path = arquivo,
sheet = "MENSAL SUBITEM IPCA",
skip = 4,
na = "-"
)
tabela |>
dplyr::mutate(periodo = periodo, .before = 1) |>
dplyr::rename(dplyr::any_of(c("item" = "...1"))) |>
dplyr::filter(dplyr::row_number() != 1)
}
Python
# Função para ler dados de interesse da planilha Excel
def ler_excel(arquivo, periodo):
tabela = pd.read_excel(
io = arquivo,
sheet_name = "MENSAL SUBITEM IPCA",
skiprows = 4,
na_values = " -"
)
tabela = (
tabela
.assign(periodo = periodo)
.rename(columns = {" ": "item"})
.query("not item.isna()")
)
return tabela
Consolidação de planilhas Excel
Por fim, aplicamos a função de leitura/tratamento de dados iterativamente, percorrendo todos os arquivos de Excel. Esse procedimento cria uma lista de tabelas, cada uma correspondente a um mês de dados. Utilizamos esta lista para combinar as tabelas e temos como resultado uma única tabela analítica:
R
# Lê e consolida arquivos Excel dados <- purrr::map2( .x = arquivos_xls, .y = names(arquivos_xls), .f = ~ler_excel(.x, .y) ) |> purrr::list_rbind() head(dados)
| periodo | item | RJ | POA | BH | REC | SP | DF | BEL | FOR | SAL | CUR | GOI | VIT | CG | RB | SL | AJU | NACIONAL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 202201 | ÍNDICE GERAL | 0.60 | -0.53 | 0.80 | 0.41 | 0.63 | 0.49 | 0.65 | 0.73 | 0.86 | 0.47 | 0.74 | 0.57 | 0.62 | 0.87 | 0.54 | 0.90 | 0.54 |
| 202201 | ALIMENTAÇÃO E BEBIDAS | 1.24 | 0.35 | 1.63 | 0.49 | 0.98 | 1.33 | 2.03 | 1.00 | 1.14 | 1.14 | 1.48 | 1.47 | 0.90 | 0.32 | 0.86 | 1.95 | 1.11 |
| 202201 | ALIMENTAÇÃO NO DOMICÍLIO | 1.58 | 0.49 | 2.07 | 0.48 | 1.49 | 1.68 | 2.37 | 1.29 | 1.23 | 1.30 | 1.98 | 1.74 | 0.96 | 0.40 | 0.88 | 2.31 | 1.44 |
| 202201 | CEREAIS, LEGUMINOSAS E OLEAGINOSAS | -2.39 | -3.80 | -2.66 | -2.31 | -1.43 | 0.39 | -0.46 | -3.02 | -1.58 | -1.89 | -2.38 | -2.84 | 0.45 | -1.50 | -4.52 | -1.90 | -2.08 |
| 202201 | ARROZ | -3.78 | -3.31 | -3.38 | -3.79 | -1.72 | -1.05 | -1.51 | -3.42 | -1.59 | -2.76 | -3.16 | -2.75 | -0.32 | -1.41 | -4.93 | -3.50 | -2.66 |
| 202201 | FEIJÃO-MULATINHO | NA | NA | NA | -2.31 | NA | NA | NA | NA | -3.65 | NA | NA | NA | NA | NA | -2.49 | NA | -2.97 |
Python
# Lê e consolida arquivos Excel dados = list( map( ler_excel, list(arquivos_xls.values()), list(arquivos_xls.keys()) ) ) dados = pd.concat(dados) dados.head()
item RJ POA ... AJU NACIONAL periodo 1 ÍNDICE GERAL 0.60 -0.53 ... 0.90 0.54 202201 2 ALIMENTAÇÃO E BEBIDAS 1.24 0.35 ... 1.95 1.11 202201 3 ALIMENTAÇÃO NO DOMICÍLIO 1.58 0.49 ... 2.31 1.44 202201 4 CEREAIS, LEGUMINOSAS E OLEAGINOSAS -2.39 -3.80 ... -1.90 -2.08 202201 5 ARROZ -3.78 -3.31 ... -3.50 -2.66 202201 [5 rows x 19 columns]
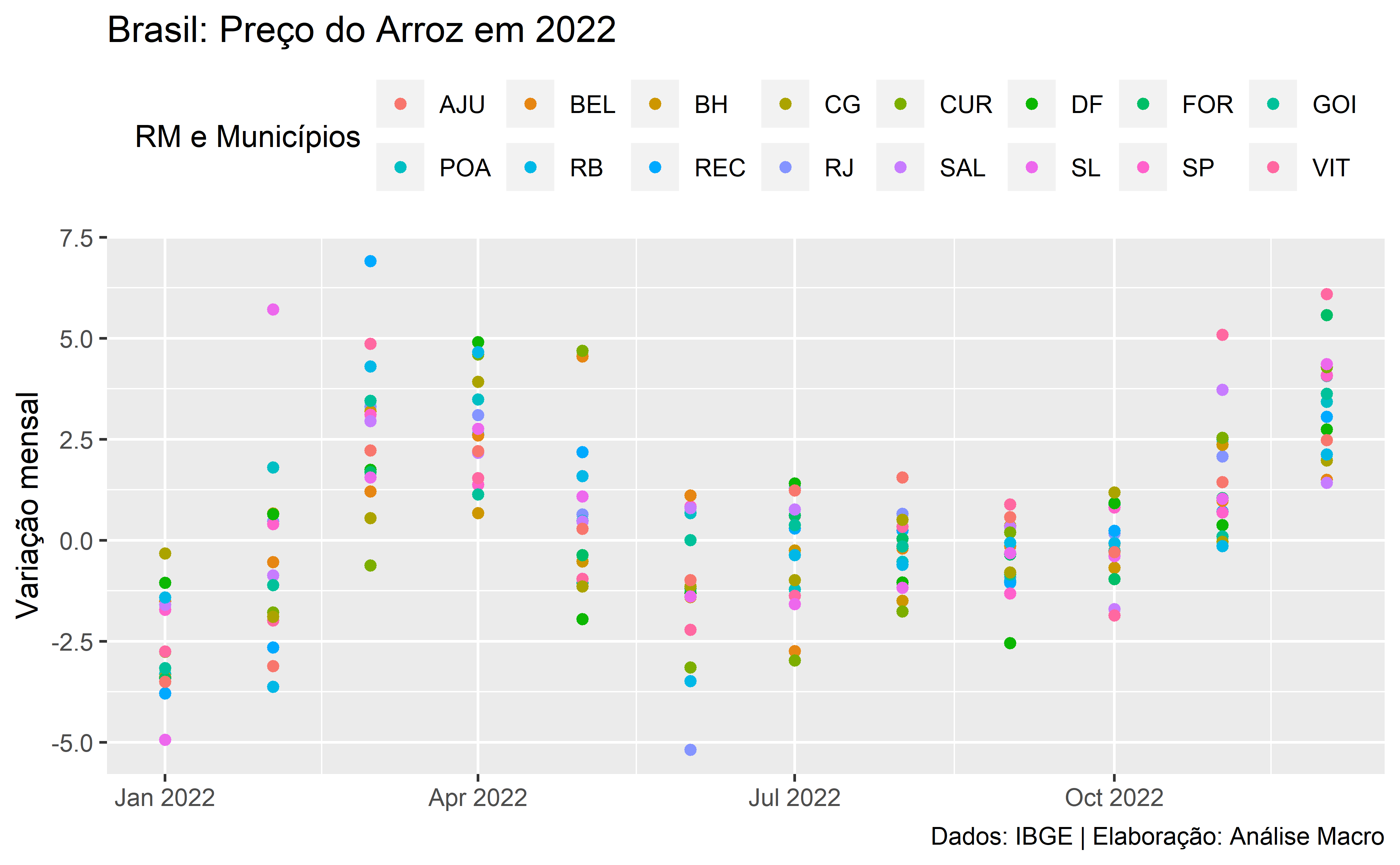
Agora as planilhas de Excel estão todas consolidadas em uma única tabela e você pode fazer as análises de dados que precisar sem muito esforço! Como exemplo, plotamos um gráfico com a variação mensal do Arroz em 2022 no Brasil:
Conclusão
Neste artigo apresentamos uma forma simples de consolidar múltiplas planilhas de Excel em uma tabela única, facilitando análises de dados subsequentes. Criamos um código simples, em R e Python, que consolida diversas planilhas automaticamente, eliminando procedimentos manuais de tratamento de dados. Usamos como exemplo os dados desagregados do IPCA fornecidos pelo IBGE.
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

