Análise de séries temporais frequentemente exige tratamentos e transformações dos dados, como a criação de defasagens (lag, no inglês) de uma variável. Podemos representar esse procedimento envolvendo o operador lag como:
![]()
Ou seja, quando aplicamos a defasagem em um elemento de yt o que obtemos é o valor anterior da série temporal.
No R este procedimento é bastante simples, sendo possível fazê-lo de mais de uma maneira diferente. Vamos a um exemplo prático!
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
library(magrittr) # CRAN v2.0.1 library(dplyr) # CRAN v1.0.7 library(timetk) # CRAN v2.6.2 library(tsibbledata) # CRAN v0.2.0
Vamos usar a série temporal do crescimento anual do PIB brasileiro como exemplo. Esses dados estão disponíveis no pacote tsibbledata. Primeiro uma rápida visualização da série:
pib_br <- tsibbledata::global_economy %>% dplyr::filter(Country == "Brazil") %>% dplyr::select(Year, Growth) pib_br %>% timetk::plot_time_series( .date_var = Year, .value = Growth, .title = "Brasil: crescimento anual do PIB", .y_lab = "%", .line_size = 2, .smooth = FALSE, .interactive = FALSE )
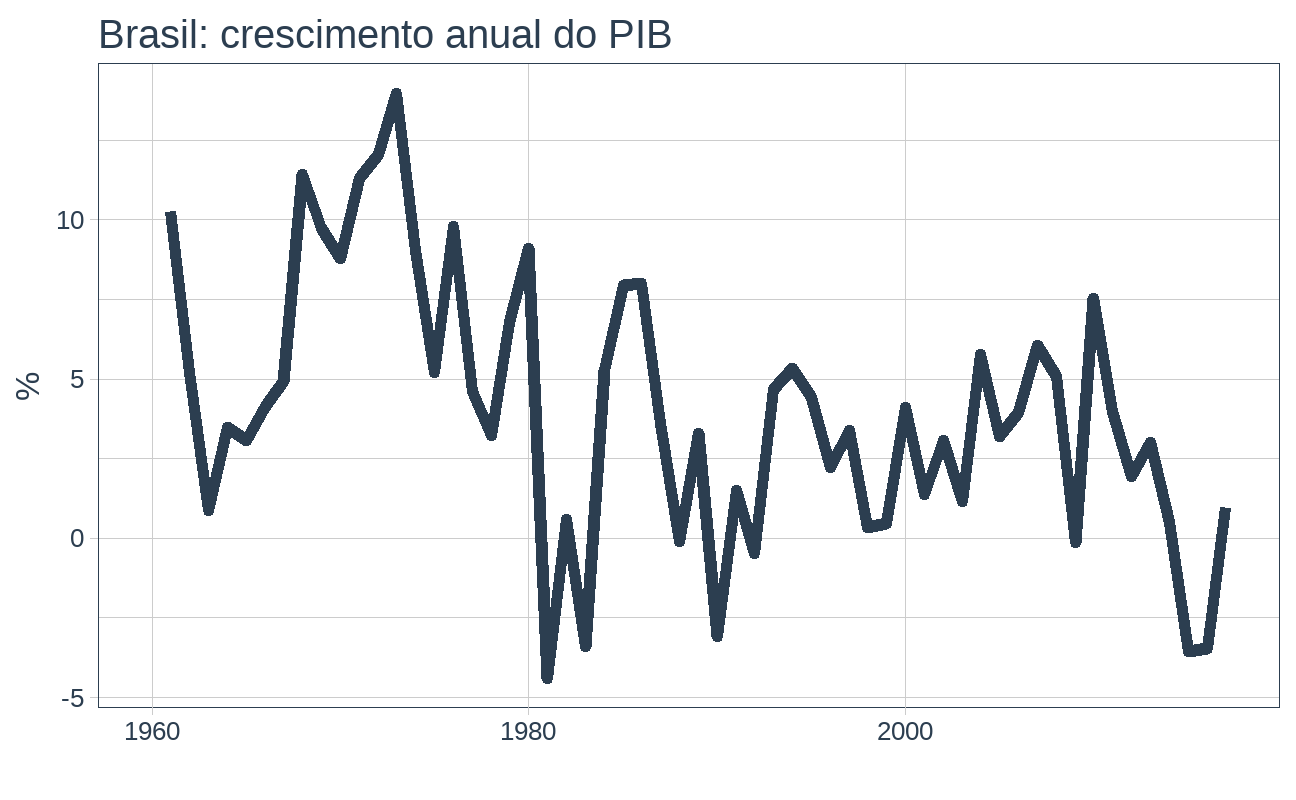
O objeto que temos é do tipo data.frame com características de série temporal (tsibble), muito vantajoso para procedimentos de tratamento de dados usando tidyverse. Neste formato, para criar uma defasagem da variável podemos simplesmente adicionar uma coluna aplicando a função dplyr::lag na variável de interesse. Simples, não?
pib_br %>% dplyr::mutate(growth_lag1 = dplyr::lag(Growth))
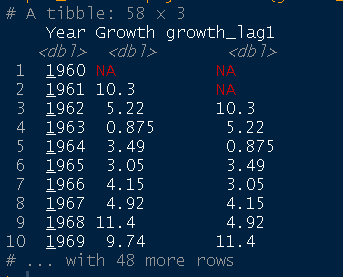
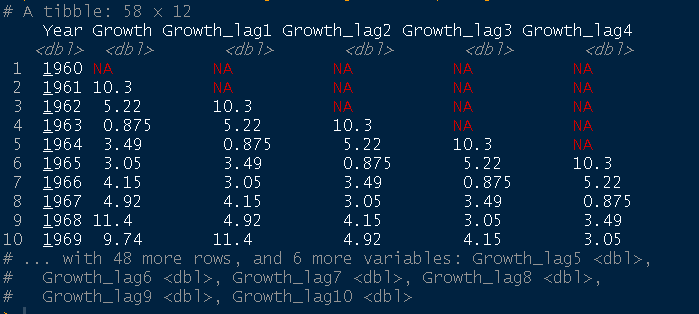
Caso o usuário precise criar múltiplas defasagens de uma variável, não há problema. O pacote timetk possui a função tk_augment_lags() que facilita o trabalho, basta apontar uma sequência de lags a serem criados, por exemplo de 1 até 10:
pib_br %>% timetk::tk_augment_lags(Growth, .lags = 1:10)
Saiba mais:


