Programar robôs para coletar informações online que não estão estruturadas ou disponíveis facilmente parece algo futurista, mas é uma vantagem competitiva de quem utiliza Python para analisar dados e automatizar processos. Neste artigo, apresentamos o que é a técnica web scraping, suas vantagens/desvantagens e como aplicar ela com o Python em um exemplo prático, do início ao fim.
O que é web scraping?
Praticamente tudo que está na internet pode ser um dado para uma análise. No entanto, nem todas as informações de uma página na internet estão disponíveis facilmente para serem coletadas. Para superar este desafio, foram criadas técnicas chamadas de web scraping visando robotizar tarefas que eram feitas por humanos.
Web scraping é o processo de coletar dados da internet, o que envolve acessar um site, navegar por sua estrutura, baixar e organizar dados de interesse através de códigos automatizáveis.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados com Python.
Quando usar web scraping?
As técnicas de web scraping são bastante úteis para situações específicas, como quando:
- Não há APIs de dados documentadas;
- Não há botão de baixar os dados;
- Dados não são estruturados para análise (textos);
- É necessário automatizar a extração de dados;
- Copiar e colar a informação para um arquivo local é inviável.
Quais são as principais aplicações do web scraping?
As técnicas de web scraping podem ser utilizadas para extrair diversas informações online, sendo principalmente aplicáveis a:
- Tabelas de dados em sites;
- Extração de links para arquivos;
- Monitoramento e comparação de preços;
- Extração de textos em páginas;
- E muito mais…
Quais são as desvantagens das técnicas de web scraping?
Mesmo possibilitando coleta de dados online de maneira automatizada, as técnicas de web scraping podem impor alguns desafios e desvantagens, como:
- Replicar a navegação web feita por humanos não é tão simple;
- Entender de tecnologias e linguagens web é importante (HTML, CSS, JavaScript);
- Códigos de web scraping são, frequentemente, não muito “bonitos”;
- Páginas na internet mudam → seu código para de funcionar!
- Páginas possuem configurações de segurança e você pode ser bloqueado se não seguir as regras;
É importante avaliar se você realmente precisa de web scraping para resolver determinado problema. Tente verificar primeiro se existe uma API, um link de download ou se os dados estão disponíveis em outro lugar na internet.
Entendendo o básico de uma página HTML
HTML é uma linguagem de marcação para criar páginas na internet. Você só precisa de um editor de textos para criar uma página simples. Por exemplo, podemos criar uma simples página de internet com alguns textos através do código abaixo, salvar este código em um arquivo e abri-lo no navegador para ver o resultado renderizado.
Arquivo .html aberto no editor de texto:
<!DOCTYPE html>
<html>
<body>
<h1>Cabeçalho 1</h1>
<p>Isso é um parágrafo</p>
<p>Abaixo é uma lista:</p>
<ul>
<li>R</li>
<li>Python</li>
<li>Julia</li>
</ul>
</body>
</html>Arquivo .html aberto no navegador:

Os navegadores se encarregam de “compilar” o arquivo, transformando-o no que vemos nas páginas da internet.
Primeiro passo do web scraping
O primeiro passo para fazer web scraping de um dado de uma página na internet é verificar se o site permite a extração de dados.
Há várias questões legais, de direitos autorais e privacidade que podem estar envolvidas e neste material não daremos nenhuma recomendação quanto a isso, apenas evidenciaremos que esses problemas podem acontecer e daremos um guia que pode ajudar a evitá-los, dessa forma você estará mais ciente e responsável com a prática de web scraping.
- O arquivo robots.txt: antes de escrever seu código de web scraping é importante verificar se a página permite o acesso por bots (scrapers, crawlers, spiders). As regras de permissão podem ser verificadas no arquivo “robots.txt” que é localizado, em geral, na raiz do site. Por exemplo:
Estes arquivos seguem uma padronização e estão disponíveis na maioria dos sites. Nele há instruções do tipo chave-valor dizendo quais partes do site é permitido/proibido fazer web scraping de dados. Caso não encontre ou estiver em dúvidas, pergunte (envie um e-mail) ao dono do site!
Na linguagem Python, a biblioteca robotspy facilita essa verificação das permissões. Basta apontar a URL do arquivo “robots.txt” e o caminho para a página de interesse e a biblioteca faz o “trabalho sujo” de ler o arquivo e te dizer se você pode ou não acessar a página por bots. Exemplos:
FalseDocumentação: https://pypi.org/project/robotspy/
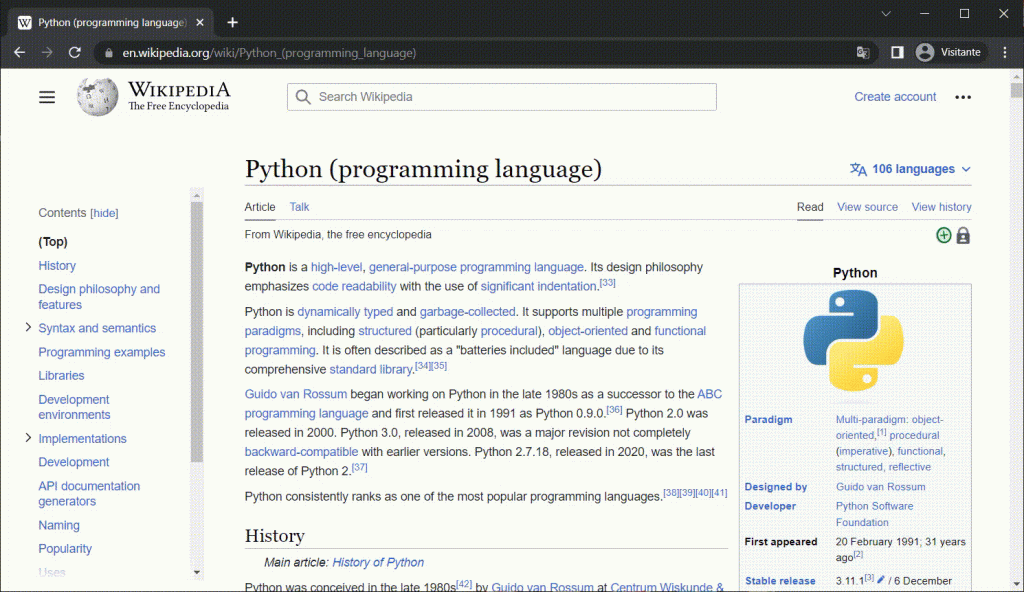
Exemplo prático: extração de uma tabela da Wikipédia
Como exemplo convidativo de web scraping no Python, vamos extrair os dados da tabela contida nesta página da Wikipédia (na seção “Typing”): https://en.wikipedia.org/wiki/Python_(programming_language)
Passo 1: o site permite web scraping?
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
TruePasso 2: ler a página HTML no Python. Daqui em diante vamos usar as bibliotecas requests e bs4 para web scraping.
Ao imprimir o objeto temos uma resposta de sucesso (status 200) e podemos extrair o conteúdo da página:
<Response [200]>
Passo 3: localizar a tabela de interesse. Com todo o conteúdo da página importado para o Python, é necessário identificar qual parte/elemento se refere a tabela. Podemos ver todos os elementos que são tabelas com:
14Essa página possui várias tabelas, mas é possível notar que cada uma possui um atributo class diferente. Sendo assim, precisamos ver qual valor a tabela de interesse possui para esse atributo.
Passo 4: localizar atributo class do elemento tabela. Para isso, recomendamos o uso do navegador Google Chrome, seguindo os passos do GIF abaixo.
Passo 5: extrair o elemento tabela com base no atributo class. Para isso, podemos filtrar os resultados usando o argumento class_ com valor do atributo identificado na etapa anterior.
Passo 6: converter o código HTML para uma tabela (DataFrame). Para isso, podemos usar read_html() sobre o elemento extraído no passo anterior.
| Type | Mutability | Description | Syntax examples | |
|---|---|---|---|---|
| 0 | bool | immutable | Boolean value | True False |
| 1 | bytearray | mutable | Sequence of bytes | bytearray(b'Some ASCII') bytearray(b"Some ASCI... |
| 2 | bytes | immutable | Sequence of bytes | b'Some ASCII' b"Some ASCII" bytes([119, 105, 1... |
| 3 | complex | immutable | Complex number with real and imaginary parts | 3+2.7j 3 + 2.7j |
| 4 | dict | mutable | Associative array (or dictionary) of key and v... | {'key1': 1.0, 3: False} {} |
| 5 | types.EllipsisType | immutable | An ellipsis placeholder to be used as an index... | ... Ellipsis |
| 6 | float | immutable | Double-precision floating-point number. The pr... | 1.33333 |
| 7 | frozenset | immutable | Unordered set, contains no duplicates; can con... | frozenset([4.0, 'string', True]) |
| 8 | int | immutable | Integer of unlimited magnitude[114] | 42 |
| 9 | list | mutable | List, can contain mixed types | [4.0, 'string', True] [] |
| 10 | types.NoneType | immutable | An object representing the absence of a value,... | NaN |
| 11 | types.NotImplementedType | immutable | A placeholder that can be returned from overlo... | NotImplemented |
| 12 | range | immutable | An immutable sequence of numbers commonly used... | range(-1, 10) range(10, -5, -2) |
| 13 | set | mutable | Unordered set, contains no duplicates; can con... | {4.0, 'string', True} set() |
| 14 | str | immutable | A character string: sequence of Unicode codepo... | 'Wikipedia' "Wikipedia""""Spanning multiple li... |
| 15 | tuple | immutable | Can contain mixed types | (4.0, 'string', True) ('single element',) () |
Conclusão
Programar robôs para coletar informações online que não estão estruturadas ou disponíveis facilmente parece algo futurista, mas é uma vantagem competitiva de quem utiliza Python para analisar dados e automatizar processos. Neste artigo, apresentamos o que é a técnica web scraping, suas vantagens/desvantagens e como aplicar ela com o Python em um exemplo prático, do início ao fim.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

