Os textos divulgados pelo COPOM, sejam os comunicados ou atas, são o ponto de partida para diversos tipos de análises quantitativas, como a análise de sentimentos, e qualitativas, como uma análise de cenário econômico. Neste artigo, mostramos como coletar estes textos de forma automatizada usando web scrapping e Python.
Para o propósito deste artigo, que é a primeira parte de um exercício maior de análise de sentimentos, vamos focar em coletas as atas do COPOM na versão em inglês.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Bibliotecas
Primeiro, importamos as bibliotecas de Python necessárias no código.
- pandas
- requests
- os
- langchain_community
Coleta de dados
Em seguida, usando o navegador Google Chrome, siga estas etapas:
- Acessar o site em inglês das atas do COPOM: https://www.bcb.gov.br/en/publications/copomminutes
- Clicar com botão direito em cima do botão Download

- Clicar em Inspecionar
- Clicar em Network

- Pressionar Ctrl+R
- No campo Filter, pesquisar por “minutes”

- Nos resultados, encontrar o serviço de API “ultimas” e copiar o link até a parte “filtro=”, assim: https://www.bcb.gov.br/api/servico/sitebcb/copomminutes/ultimas?quantidade=3&filtro=

- Requisitar os metadados das últimas 50 atas, mudando o parâmetro “quantidate” no link acima, através das bibliotecas requests e pandas
Como resultado, temos uma tabela DataFrame com os links para os PDFs das últimas 50 atas:
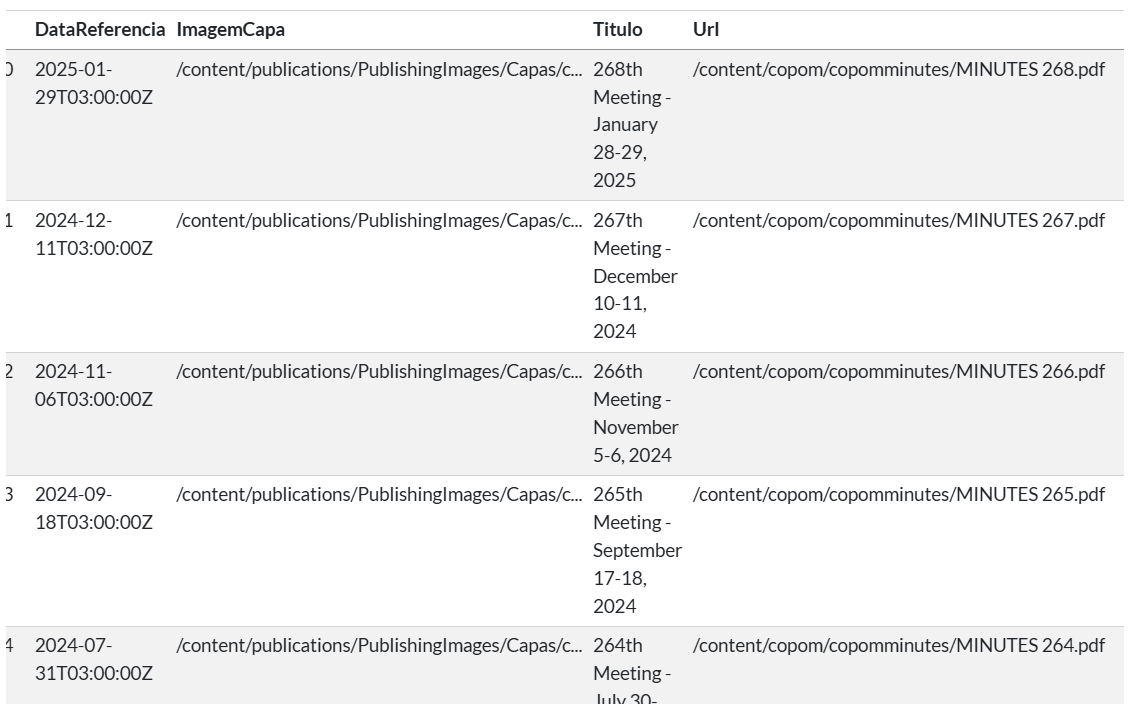
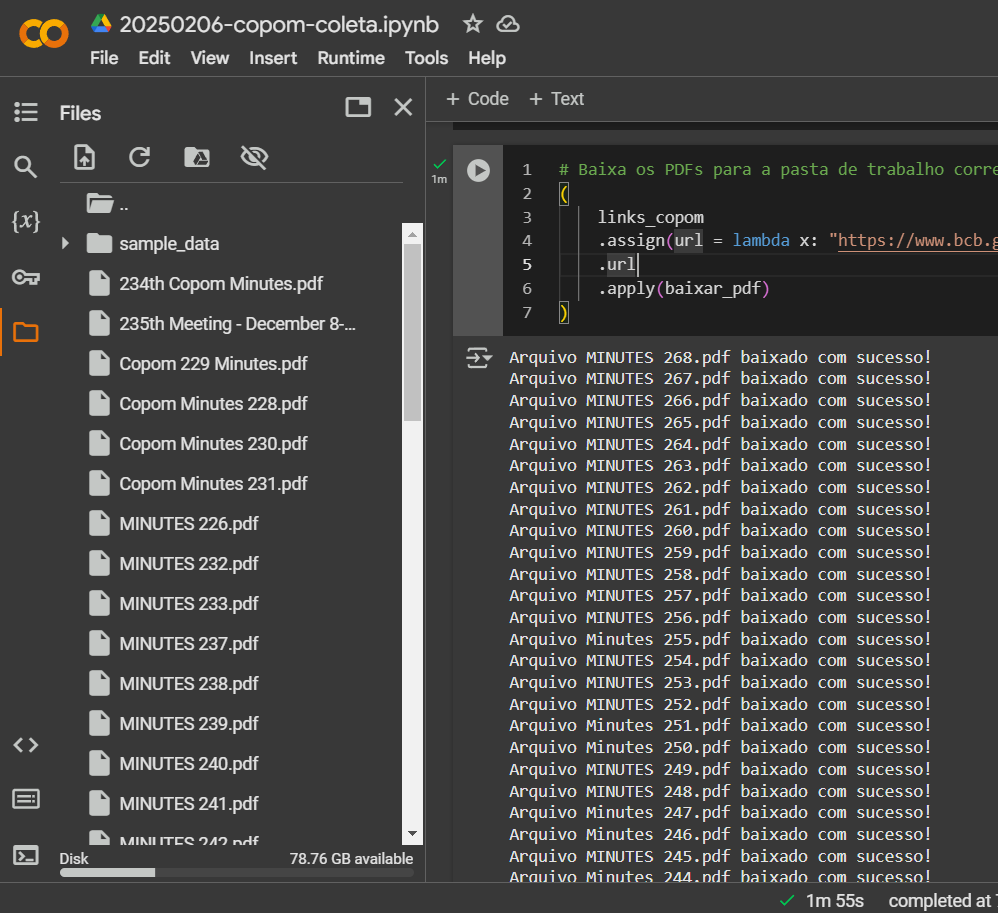
Importação de dados
Por fim, com os textos disponibilizados localmente em formato PDF, podemos avançar para a etapa de transformar as informações de PDF para texto (string) diretamente no Python. Usamos a biblioteca pypdf e a langchain_community para fazer esta transformações em poucas linhas de código.
Como resultado, teremos uma tabela com os metadados da ata do COPOM e o texto bruto associado:
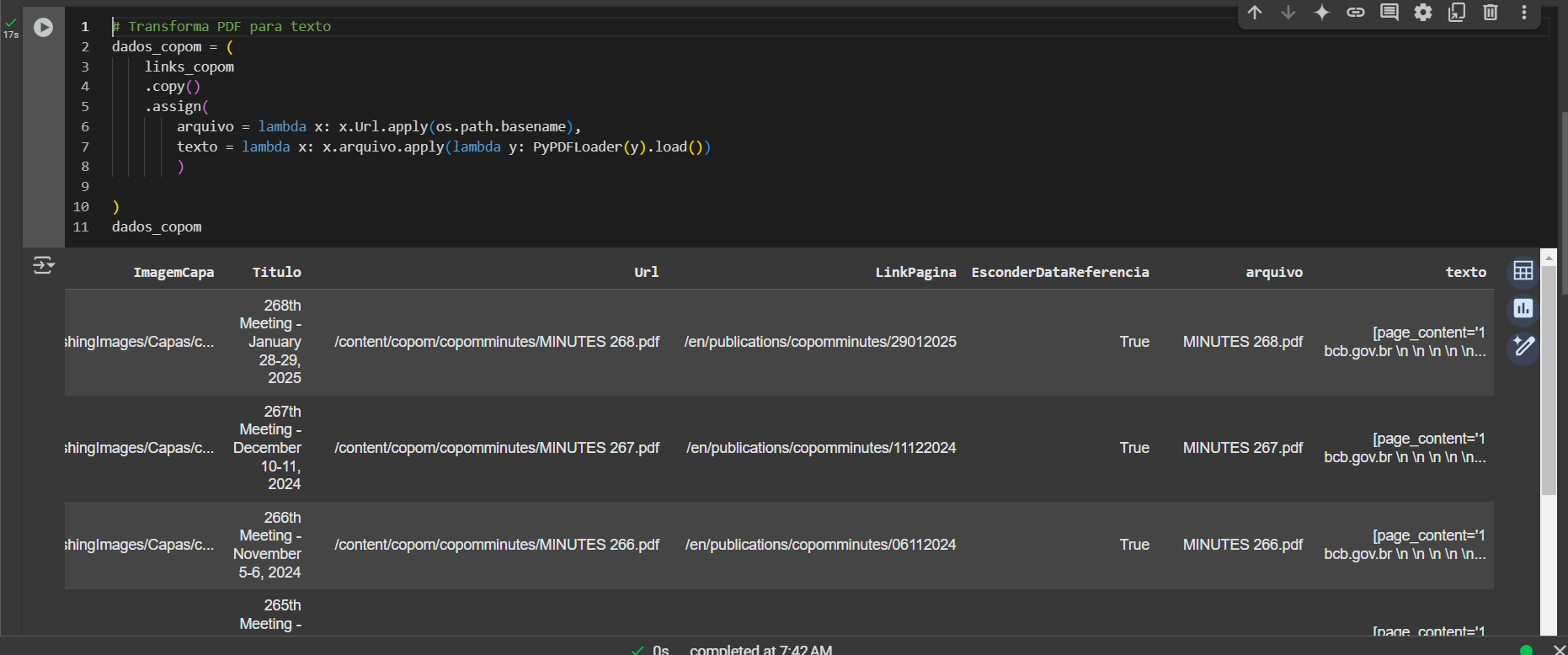
Conclusão
Os textos divulgados pelo COPOM, sejam os comunicados ou atas, são o ponto de partida para diversos tipos de análises quantitativas, como a análise de sentimentos, e qualitativas, como uma análise de cenário econômico. Neste artigo, mostramos como coletar estes textos de forma automatizada usando web scrapping e Python.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

