 Modelagem de séries temporais frequentemente exige a aplicação de transformações nas variáveis, tal como a bem conhecida primeira diferença. Formalmente, podemos descrever essa transformação como:
Modelagem de séries temporais frequentemente exige a aplicação de transformações nas variáveis, tal como a bem conhecida primeira diferença. Formalmente, podemos descrever essa transformação como:
![]()
Ou seja, dado uma série temporal regularmente espaçada, subtraímos do valor em t o valor anterior (t-1), obtendo a série dita "na primeira diferença" ou "nas diferenças".
A mudança de nível da série geralmente contorna diversas características "não desejadas" pelo analista como tendência, sazonalidade, etc., mas dificulta a interpretação dos valores - especialmente quando pretende-se comunicá-los para públicos não técnicos. Para este objetivo é de grande utilidade saber como diferenciar uma série temporal e, sobretudo, também como reverter a transformação.
Para reverter a primeira diferença de uma série utilizamos a soma cumulativa, representada como:
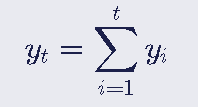
Ou seja, no final teremos um vetor com a soma de cada valor em t com todos os anteriores, valores estes que neste caso podem representar a série na primeira diferença que se deseja reverter.
Exemplo no R
Para exemplificar, vamos aplicar um exercício simples no R com o objetivo de 1) tomar a primeira de uma série e 2) reverter a transformação para obter a série original.
Para esse exemplo você precisará dos seguintes pacotes:
library(magrittr) # CRAN v2.0.1 library(GetBCBData) # CRAN v0.6 library(dplyr) # CRAN v1.0.7 library(timetk) # CRAN v2.6.2 library(tsibble) # CRAN v1.0.1 library(tidyr) # CRAN v1.1.4
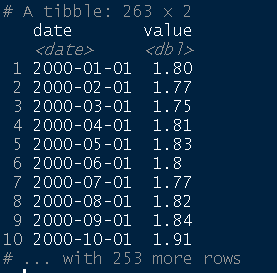
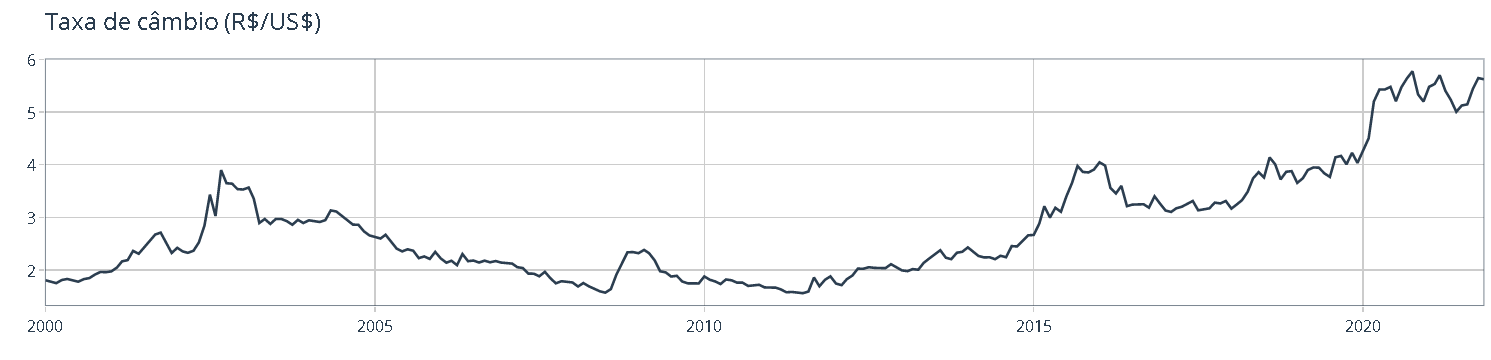
Utilizaremos uma série conhecidamente não estacionária: a taxa de câmbio (R$/US$). Primeiro, importamos a série diretamente do banco de dados do Banco Central (SGS/BCB) e tratamos os dados para obter um tibble:
dados <- GetBCBData::gbcbd_get_series(
id = 3696,
first.date = "2000-01-01",
use.memoise = FALSE
) %>%
dplyr::select("date" = "ref.date", "value") %>%
dplyr::as_tibble()
dados
timetk::plot_time_series( .data = dados, .date_var = date, .value = value, .smooth = FALSE, .title = "Taxa de câmbio (R$/US$)" )
dados %<>% dplyr::mutate(value_diff = tsibble::difference(value)) dados
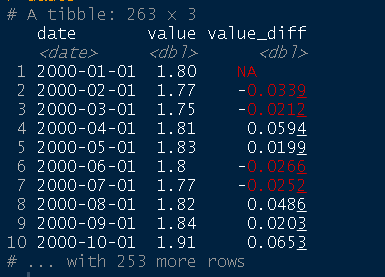
dados %<>% dplyr::mutate( value_diff = dplyr::if_else(is.na(value_diff), value, value_diff), value_revert = cumsum(value_diff) ) dados
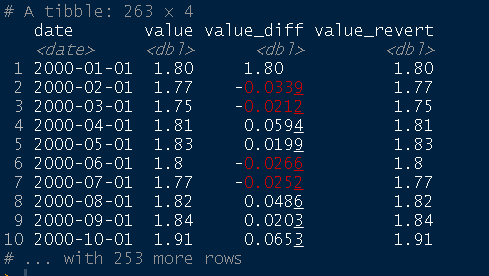
all.equal(dados$value_revert, dados$value)
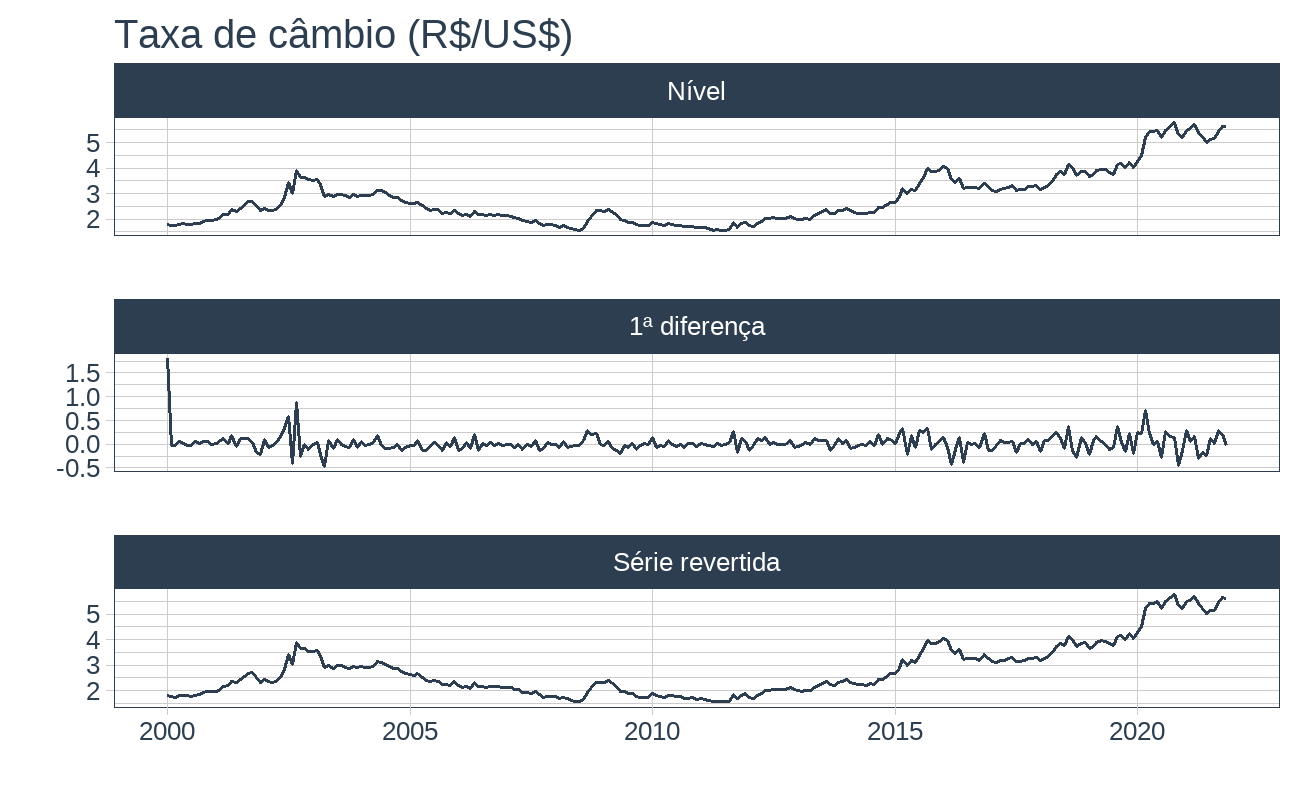
Os cálculos ocorreram conforme o esperado: a série original da taxa de câmbio importada do BCB é igual à série que aplicamos e revertemos a primeira diferença.
Simples, não?
Por fim, vale comparar visualmente o comportamento da série em nível e na diferença (primeiro gráfico):
dados %>% dplyr::select( "date", "Nível" = "value", "1ª diferença" = "value_diff", "Série revertida" = "value_revert" ) %>% tidyr::pivot_longer( cols = -"date", names_to = "variable" ) %>% timetk::plot_time_series( .date_var = date, .value = value, .facet_vars = variable, .smooth = FALSE, .title = "Taxa de câmbio (R$/US$)", .interactive = FALSE )


