Prever séries temporais é uma tarefa frequente em diversas áreas, porém exige conhecimento e ferramentas específicas. Os modelos de machine learning do Sklearn são populadores, porém são difíceis de aplicar em estruturas temporais de dados. Neste sentido, introduzimos a biblioteca Skforecast, que integra os modelos do Sklearn e a previsão de séries temporais de forma simples.
Biblioteca skforecast
A biblioteca skforecast é uma biblioteca de previsão de séries temporais no Python que possibilita trabalhar com:
- Modelos univariados de previsão
- Modelos multivariados de previsão
- Modelos globais de previsão
- Engenharia de variáveis
- Avaliação de performance
- Previsão probabilística
- Visualização de dados
Por sua versatilidade, facilidade e integração direta com o sklearn, é a biblioteca que usamos como base no curso de Previsão Macroeconômica usando Python e IA.
Exemplo prático
Aqui demonstramos um exemplo de aplicação da biblioteca skforecast para a previsão de uma série temporal.
Primeiro carregamos as biblitoecas e os dados:
h2o
---
Monthly expenditure ($AUD) on corticosteroid drugs that the Australian health
system had between 1991 and 2008.
Hyndman R (2023). fpp3: Data for Forecasting: Principles and Practice(3rd
Edition). http://pkg.robjhyndman.com/fpp3package/,https://github.com/robjhyndman
/fpp3package, http://OTexts.com/fpp3.
Shape of the dataset: (204, 2)| y | datetime | |
|---|---|---|
| 0 | 0.429795 | 1991-07-01 |
| 1 | 0.400906 | 1991-08-01 |
| 2 | 0.432159 | 1991-09-01 |
| 3 | 0.492543 | 1991-10-01 |
| 4 | 0.502369 | 1991-11-01 |
Em seguida, preparamos os dados, separando as amostras de treino e teste, e plotamos os dados em um gráfico:

Agora utilizamos um modelo do sklearn, a regressão Ridge, como previsor para a série temporal, gerando 36 períodos de previsão:
2005-07-01 0.973094
2005-08-01 1.022110
2005-09-01 1.151346
Freq: MS, Name: pred, dtype: float64
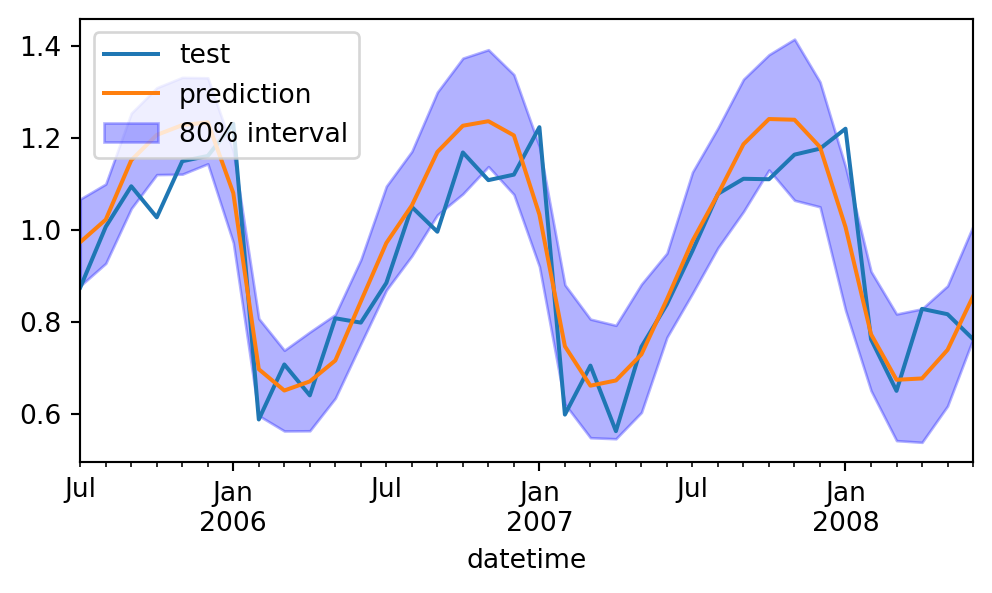
Por fim, calculamos o erro de previsão e exibimos o intervalos de confiança em um gráfico:
Test error (mse): 0.009916974045984968
Conclusão
Prever séries temporais é uma tarefa frequente em diversas áreas, porém exige conhecimento e ferramentas específicas. Os modelos de machine learning do Sklearn são populadores, porém são difíceis de aplicar em estruturas temporais de dados. Neste sentido, introduzimos a biblioteca Skforecast, que integra os modelos do Sklearn e a previsão de séries temporais de forma simples.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, conheça o Clube AM clicando aqui.

