A inflação medida pelo IPCA é uma variável que possivelmente pode ser relacionada com uma série de outras variáveis, desde indicadores de nível de atividade, de expectativas, de mercado de trabalho até indicadores de política monetária, para citar alguns. E no mundo de hoje há uma abundância de dados, uma simples navegação até o sistema SGS do BCB já possibilita encontrar milhares de séries temporais. Dessa forma, rapidamente podemos incorrer na armadilha da alta dimensionalidade dentro de um problema de previsão, ou seja, quando temos mais variáveis (K) do que observações (T). Isso é especialmente comum em problemas de previsão de séries macroeconômicas, como o exemplo do IPCA, mas acontece em outras áreas também.
Portanto, como estimar relações entre as variáveis e construir previsões com essa dimensionalidade de dados? Como você escolhe quais variáveis relacionar e define quais são as mais importantes?
Mesmo que você não esteja em uma situação de problema de alta dimensionalidade, se as variáveis forem altamente correlacionadas e a variável que você deseja prever apresentar muitos ruídos, problemas como multicolinearidade e overfitting poderão aparecer, pois o modelo tentará ajustar o ruído. Você poderia então contornar esses problemas ao selecionar algumas variáveis para estimar um modelo em que K < T, mas a seleção das variáveis pode trazer outro problema que é selecionar variáveis que não ajudam em termos de performance preditiva, ou seja, você poderia perder informação útil para o modelo.
Uma outra solução poderia ser estimar vários modelos com diferentes seleções de variáveis em cada e, então, combinar as previsões individuais destes modelos. O comum dessa abordagem são modelos univariados, onde o interesse é prever a variável dependente usando vários modelos, cada um com uma variável independente diferente. No entanto, você provavelmente precisará mais do que um modelo univariado para explicar sua variável de interesse. Nesse caso, outra abordagem possível pode ser estimar modelos para todas as combinações possíveis de variáveis, porém o procedimento pode ser rapidamente inviável computacionalmente se o número de variáveis for muito grande.
O método CSR
A abordagem do método Complete Subset Regression (CSR) busca solucionar alguns desses problemas, pois permite definir um número k de variáveis e estimar todos os possíveis modelos com k < K variáveis (por isso subset), ou seja, teremos um total de K! / (k!(K - k)!) modelos estimados. Por exemplo, se você tem K = 20 variáveis e define k = 15 serão estimados 15504 modelos. A previsão do CSR é, então, gerada a partir da média das previsões obtidas por cada modelo.
Esse método é relativamente novo e simples, apresentado por Elliott et al. (2013), sendo bastante interessante para problemas de previsão com alta dimensionalidade. Conforme os autores, podemos destacar algumas das principais vantagens do CSR:
- Leva em conta o viés de variável omitida;
- Aplica pesos flexíveis aos coeficientes das regressões;
- É capaz de produzir menor erro de previsão fora da amostra em relação ao MQO e benchmarks.
Os autores também discutem, entre outros tópicos, o tradeoff entre viés e variância no contexto do método. Se você estiver interessado, estes e outros detalhes — assim como resultados de aplicações empíricas — são abordados no paper referenciado. Vale a pena conferir!
Em resumo, o CSR é um método recursivo em três simples etapas:
- Estime todos os modelos possíveis com k < K variáveis;
- Calcule as previsões de todos os modelos;
- Calcule a média de todas as previsões para obter a previsão final.
Apesar da simplicidade e das vantagens, o método parece ser ainda pouco difundido na área de ciência de dados. Portanto, a seguir mostramos como implementar o CSR utilizando a linguagem R.
Implementação no R
No R, a implementação do método CSR pode ser feita através do pacote {HDeconometrics}, que adota um procedimento adicional em relação ao método CSR original, conforme descrito em Garcia et al. (2017). O procedimento adicional envolve, em resumo, uma etapa de pré-seleção de variáveis em termos de poder de previsão; isso é feito com base na estatística t dos coeficientes estimados por regressões da variável de interesse contra cada K variável candidata. Estas variáveis pré-selecionadas são, então, usadas no método CSR.
Como exemplo, seguindo a provocação inicial do texto, definimos como interesse a previsão da inflação brasileira, medida pelo IPCA (% a.m.). A fonte de dados utilizada será o dataset de Garcia et al. (2017), que traz uma série de variáveis referentes a índices de preços, variáveis macroeconômicas, de expectativas, etc., além da própria variável de interesse. O dataset compreende a janela amostral de janeiro/2003 a dezembro/2015, totalizando 156 observações e 92 variáveis.
Os dados e o código de exemplo são disponibilizados nos próprios exemplos de uso na documentação do {HDeconometrics}, sendo que apenas adaptamos para demonstrar com a finalidade de previsão. Se você tiver interesse em um exemplo com dados mais atualizados e em uma estratégia de previsão completa, confira o curso de Modelos Preditivos da Análise Macro.
O pacote {HDeconometrics} está disponível para instalação através do GitHub, conforme o comando abaixo:
Os dados podem ser carregados para o seu Global Environment conforme abaixo:
Em seguida realizamos a preparação dos dados, com vistas a estimar um modelo na forma do IPCA corrente contra defasagens das variáveis regressoras candidatas, definindo as últimas 24 observações como alvo de previsão:
Por fim, o modelo pode ser estimado definindo o valor de K, que é o número de variáveis selecionadas na etapa de pré-seleção, e de k, que é o número de variáveis utilizadas em cada possível regressão do método CSR. Opcionalmente, podem ser definidas variáveis como parâmetros fixos no modelo, através do argumento fixed.controls. Nesse caso, definimos a primeira defasagem do IPCA como parâmetro fixo, indicando o índice da coluna correspondente em x, o que significa que cada possível modelo terá k + 1 variáveis.
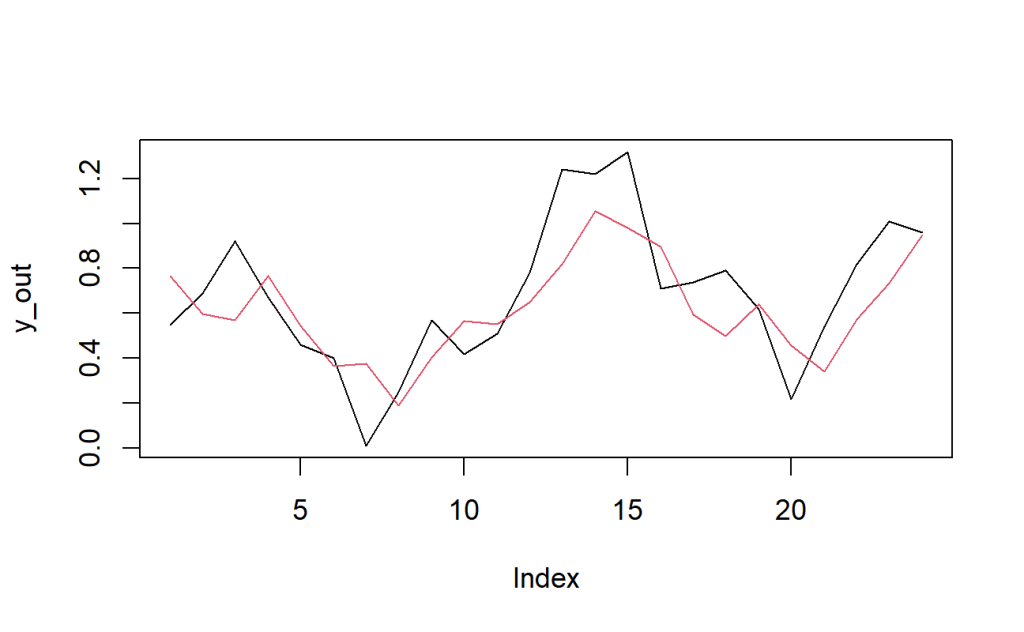
A seguir estimamos o modelo, calculamos as previsões 24 períodos a frente (pseudo fora da amostra) e plotamos o resultado comparando o valor observado do IPCA versus o previsto pelo modelo no período.
Apesar de ser um exemplo simples e sem muita robustez metodológica da forma como implementado, o resultado parece não ser ruim e, de fato, quando comparamos com outros modelos como Bagging, LASSO, etc., o método CSR se destaca em termos de acurácia de previsão do IPCA. Sinta-se livre para estimar outros modelos e realizar a comparação, assim como calcular o erro de previsão e métricas de acurácia.
Referências
Elliott, G., Gargano, A., & Timmermann, A. (2013). Complete subset regressions. Journal of Econometrics, 177(2), 357-373.
Vasconcelos, Gabriel F. R. (2022). HDeconometrics: Implementation of several econometric models in high-dimension. R package version 0.1.0.
Vasconcelos, Gabriel F. R. (2017, May 31). Complete Subset Regressions, simple and powerful. R-bloggers. https://www.r-bloggers.com/2017/05/complete-subset-regressions-simple-and-powerful/
Garcia, M. G., Medeiros, M. C., & Vasconcelos, G. F. (2017). Real-time inflation forecasting with high-dimensional models: The case of Brazil. International Journal of Forecasting, 33(3), 679-693.

