Ao criar tabelas contendo dados sobre uma organização/empresa ou um projeto é necessário planejar cuidadosamente o design do banco de dados para que se evite erros e problemas ao consultar e inserir os dados. No post de hoje, iremos elencar alguns pontos principais e questões críticas que devem ser tomadas em conta ao planejar um banco de dados.
As vezes, ao invés de somente consultar dados por meio da manipulação, é interessante também utilizar comandos como CREATE para criar novas tabelas, bem como INSERT, UPDATE e DELETE para alterar e inserir os registros em um banco de dados. Entretanto, antes de utilizar esses comandos é necessário projetar como os dados estão dispostos, respondendo as seguintes perguntas:
- Qual o contexto da utilização do banco de dados no projeto ou empresa?
- Quais tabelas necessitam preencher esses requerimentos?
- Quais colunas cada tabela necessita conter?
- Como as tabelas serão normalizadas?
- Qual será a relação hierárquica das tabelas?
Além dessas questões, outros pontos são necessários a se considerar ao longo do design de um banco de dados, e um deles é como os dados serão inseridos, se não há manutenção no banco de dados, não há como utilizá-lo sempre, portanto, é necessário que se responda as seguintes perguntas:
- Qual a quantidade dados que serão inseridos nessas tabelas?
- Quem/O que irá inserir os dados?
- Qual a fonte dos dados?
- É necessário que o processo de inserção dos dados seja automatizado? Se sim, qual linguagem de programação irá realizar o trabalho?
Além dessas questões, é sempre importante pensar na segurança, afinal, dentro de uma empresa é importante manter o sigilo e a exposição ao risco dos dados.
- Quem deve ter acesso ao banco de dados?
- Quem deve ter acesso as tabelas e quais? Apenas leitura?
- Qual o plano de backup caso ocorra falhas?
Chave primária e Chave Estrangeira
Para criar um banco de dados, com diversas tabelas, é sempre necessário ter uma chave primária em qualquer tabela. Uma chave primário é considerada um campo especial que mantém uma identidade única para cada registro, bem como frequentemente define o relacionamento entre as tabelas. Configurar uma chave primária facilita as consultas do software do banco de dados, além de certificar a integridade dos dados, não permitindo valores duplicados. Elas são conhecidas por identificar as tabelas Parent.
É necessário certificar de que tabelas possuam uma chave estrangeira, que por outro lado, identificam uma tabela Child, isto é, em conjunto com a chave primária, definem a hierarquia da relação entre as tabelas.
Schemas
Com as Chaves primárias e Estrangeiras nas tabelas Parent e Child é possível estabelecer a relação entre diversas tabelas e desenhar um Schema do banco de dados, isto é, um diagrama que represente as tabelas, suas colunas e seus relacionamentos.
Veja no exemplo abaixo, em que há várias tabelas representadas por entidades, cada entidade possui um campo que podem ser chaves primárias e estrangeiras. Cada tabela é orientada por setas, todas as chaves primárias e estrangeiras são conectadas por setas. O lado que não possui pontas ligam as chaves primárias, enquanto o lado que possui pontas ligas as chaves estrangeiras.
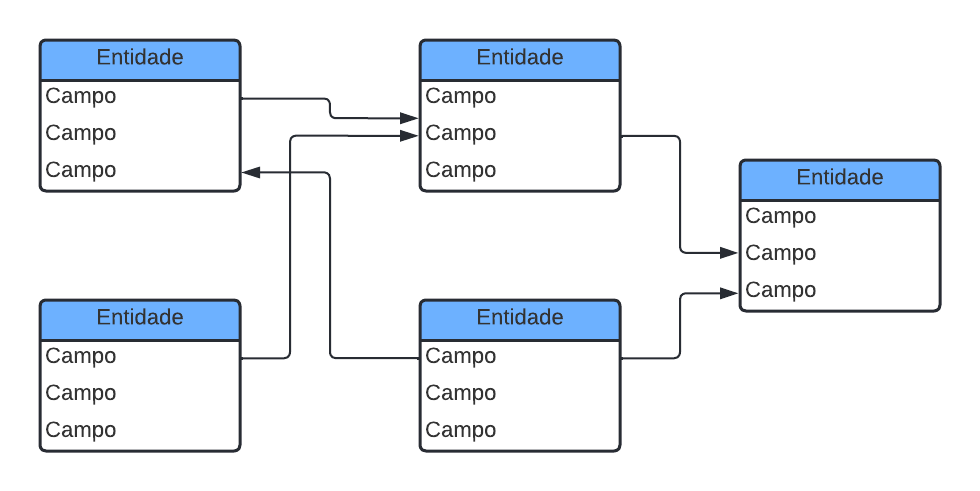
Com esses conceitos em mente, fica muito mais fácil de criar e desenhar um projeto de banco de dados, em que se tenha um relacionamento entre as tabelas de forma clara e concisa. Um Schema facilita a visualização desses relacionamentos.
____________________________________________________
Quer aprender mais?
Veja nosso curso de SQL para Economia e Finanças, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.
_________________________________________
Referências
Nield, Thomas. Getting Started with SQL: A Hands-On Approach for Beginners. O'Reilly Media, Inc., 2016.

