Nem sempre os dados que precisamos estão disponíveis facilmente para download, principalmente quando se trata de fontes públicas de informação. Nestes casos, quando não há uma API ou um arquivo CSV, por exemplo, uma alternativa pode ser implementar a técnica de "raspagem de dados" ou web scrapping, que nada mais é do que coletar dados de páginas na web. Felizmente, no R este procedimento costuma ser relativamente fácil e neste post faremos um exercício simples de demonstração.
Como exemplo, pegaremos os dados de mandatos dos Ministros da Saúde do Brasil disponíveis neste link. A página contém três tabelas com informações sobre os nomes dos ministros, datas de início e fim no mandato e o respectivo governo. Vamos pegar os dados dessas três tabelas com o auxílio de alguns pacotes no R e, ao final, faremos uma simples análise gráfica.
Importante: para este tipo de procedimento recomendamos que utilize o navegador Google Chrome.
1º passo: identificar
Antes de tudo, até mesmo antes de abrir o RStudio, é preciso identificar na página quais informações se deseja coletar. Neste exemplo, os dados estão organizados em três tabelas: República Nova, Ditadura militar, Nova República.
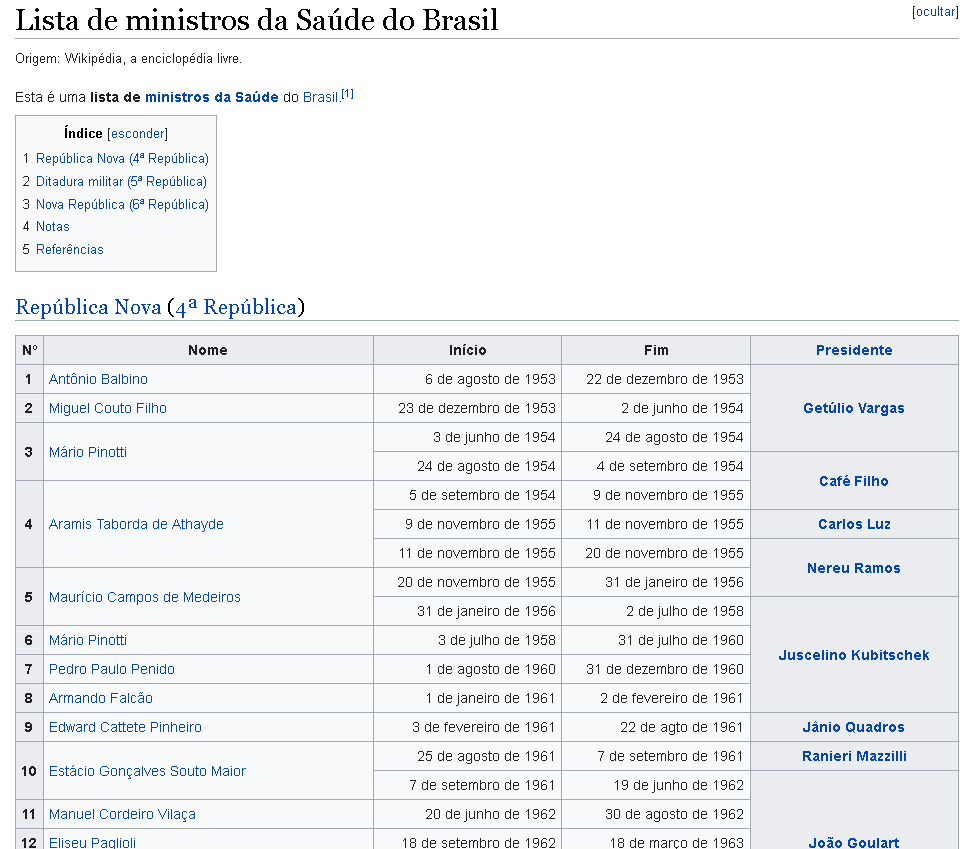
2º passo: navegar
Agora que sabemos o que desejamos obter, o próximo passo é buscar o chamado XPath que nos fornece um caminho para as tabelas, dentro da estrutura da página. Esse caminho servirá para apontar o que exatamente iremos coletar da página, facilitando o trabalho. Para obtê-lo é bem simples: clique com o botão direito em cima da tabela e depois clique em Inspecionar.
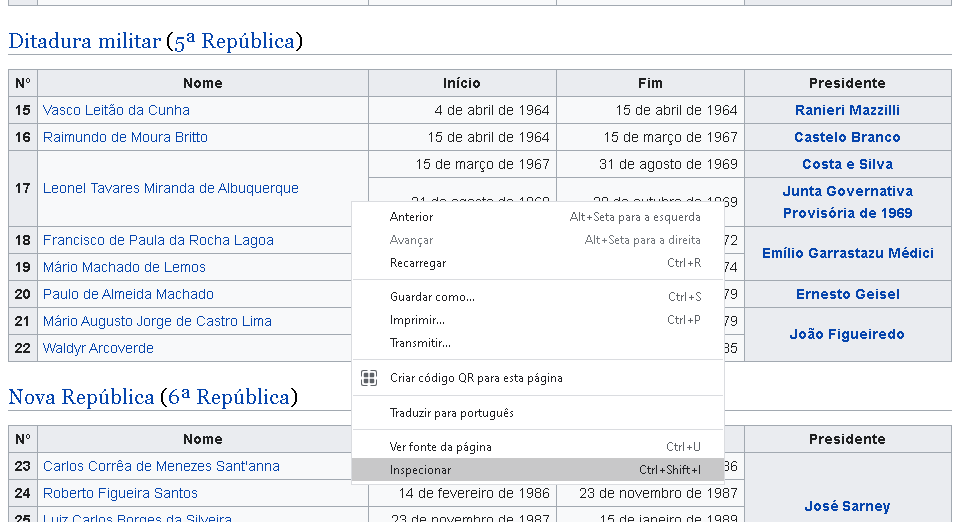
Isso fará com que se abra uma seção de ferramentas de desenvolvedor no navegador. Na aba Elements, aparecerá em destaque os códigos HTML do local onde você clicou com o botão direito. Um olhar ligeiro nos mostrará que as três tabelas que estamos buscando possuem essa identificação logo no início: <table width="100%" class="wikitable"> e devem constar próximo à região de destaque aberta. Agora clique com o botão direito sobre essa identificação em qualquer uma das três tabelas, selecione Copy e depois Copy XPath.
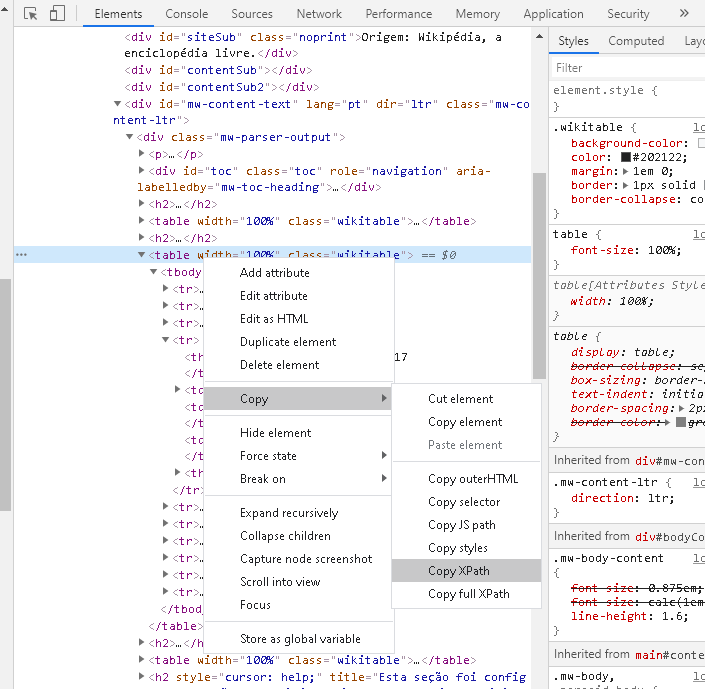
Esse procedimento pode variar conforme a página e/ou elemento que se deseja coletar, portanto é importante o instinto da curiosidade.
Feito estes procedimentos você deve ter obtido um código XPath similar a esse:
//*[@id="mw-content-text"]/div[1]/table[1]
Iremos remover a parte final entre colchetes que indica o número da tabela que queremos, assim obteremos todas as três tabelas de uma única vez:
//*[@id="mw-content-text"]/div[1]/table
3º passo: coletar
Agora vamos para o R fazer a coleta dos dados efetivamente. Aqui utilizaremos estes pacotes:
# Instalar/carregar pacotes
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
"tidyverse",
"rvest",
"janitor",
"lubridate"
)
Para organização do código, primeiro definimos os parâmetros XPath e a URL da página, salvando-os em objetos, e depois fazemos a leitura das informações da página usando a função read_html do pacote rvest.
# URL base www <- "https://pt.wikipedia.org/wiki/Lista_de_ministros_da_Sa%C3%BAde_do_Brasil" # Xpath da tabela xpath <- "//*[@id='mw-content-text']/div[1]/table" # Salvar informações da página pg <- rvest::read_html(www)
Agora usamos a função html_nodes para extrair exatamente o XPath desejado e transformamos o output em tabela. Em sequência fazemos uma pequena tratativa e unimos as três tabelas. O resultado é uma tibble com 59 linhas.
# Buscar tabelas pelo Xpath e transformar formato dados <- pg %>% rvest::html_nodes(xpath = xpath) %>% rvest::html_table() %>% purrr::map(~dplyr::mutate(.x, `Nº` = as.character(`Nº`))) %>% dplyr::bind_rows() %>% janitor::clean_names() dplyr::glimpse(dados) # Rows: 59 # Columns: 5 # $ no <chr> "1", "2", "3", "3", "4", "4", "4", "5", "5", "6", "7", "8",~ # $ nome <chr> "Antônio Balbino", "Miguel Couto Filho", "Mário Pinotti", "~ # $ inicio <chr> "6 de agosto de 1953", "23 de dezembro de 1953", "3 de junh~ # $ fim <chr> "22 de dezembro de 1953", "2 de junho de 1954", "24 de agos~ # $ presidente <chr> "Getúlio Vargas", "Getúlio Vargas", "Getúlio Vargas", "Café~
Simples e rápido, né? E com esses dados em mãos, basta mais algumas tratativas para poder gerar um gráfico como esse:
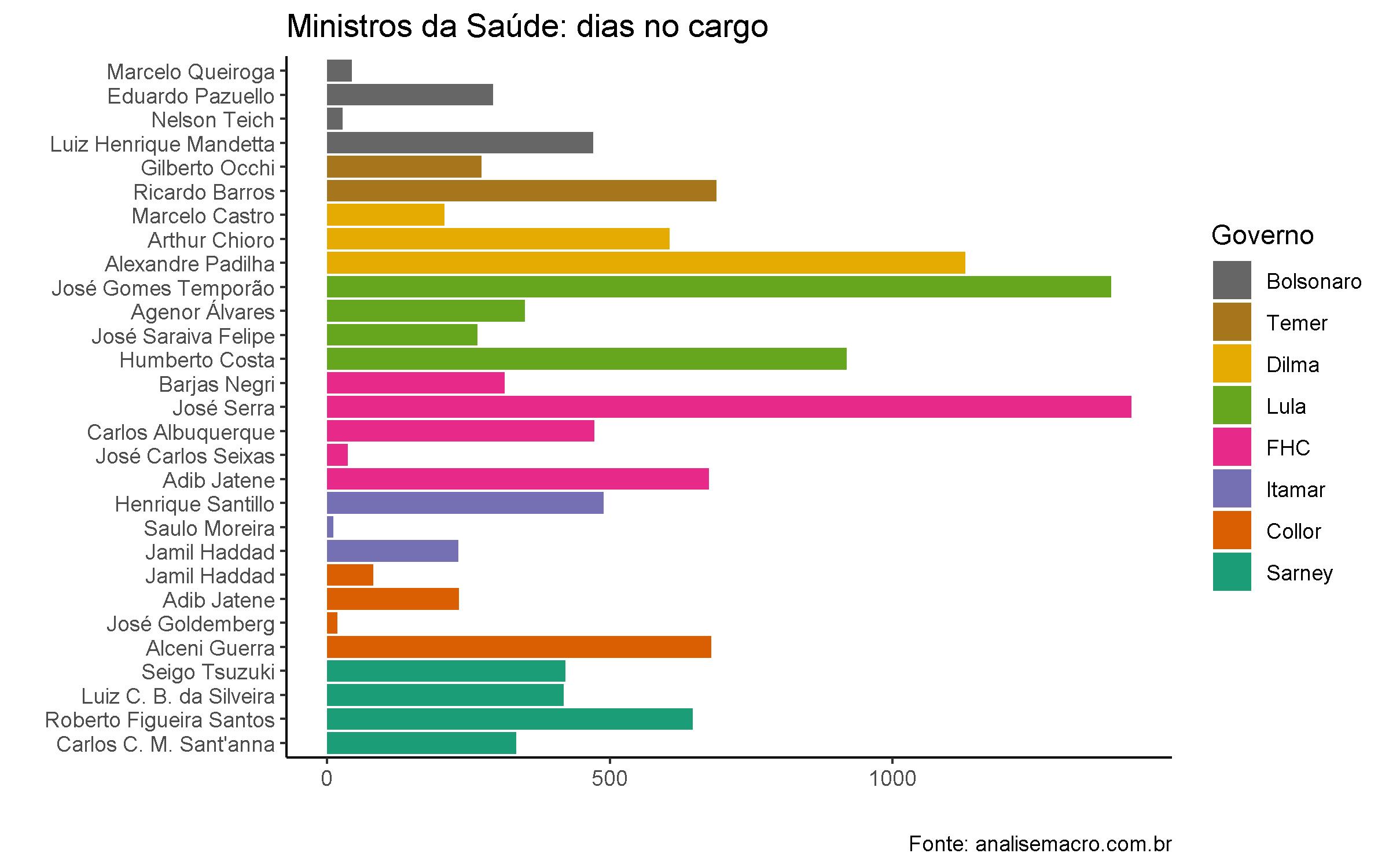
Com o gráfico é possível observar uma similaridade de mudanças de ministros entre o governo atual e os conturbados governos Collor e Itamar.

