Em uma noite de insônia, navegando pelo meu feed no facebook, acabei vendo um post do professor Carlos Eduardo Gonçalves com um gráfico de renda per capita fazendo referência ao projeto Maddison; que tem o ousado objetivo de estimar essa variável para todos os países do mundo desde os anos mais remotos. Acabei fazendo o que todo R Lover faria: dei um google para ver se tinha um pacote para o projeto. E, claro, tinha...
Acabei, então, dando uma vasculhada no dataset e escrevi algumas linhas de código, após comer um sanduíche... 🙂
library(maddison) library(ggplot2) library(scales) library(png) library(grid)
O script começa carregando - depois de ter instalado o mesmo, obviamente - o pacote maddison. Depois carreguei o pacote ggplot2 e alguns pacotes acessórios a ele, para produzir um gráfico mais bonitinho... Antes, claro, como o dataset é imenso - tem 45.318 observações para 9 variáveis - eu fiz um subset do que eu estava interessado para poder montar um gráfico...
df = subset(maddison, year>='1870-01-01' &
iso2c %in% c('BR', 'US', 'CL', 'JP', 'KR'))
Com o código acima, eu peguei os dados do pib per capita para Brasil, Estados Unidos, Chile, Japão e Coréia do Sul desde 1870, quando os primeiros dados para o Brasil estavam disponíveis. Com esses dados, construí o gráfico abaixo.
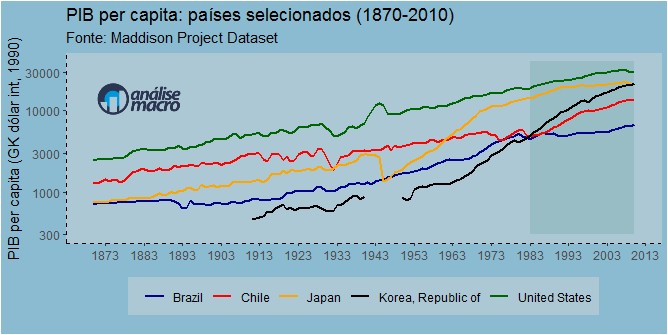
Algumas coisas me chamaram atenção nesse gráfico. Observe que tínhamos em 1870 a mesma renda per capita do Japão, que nos deixou para trás. Em 1980, tínhamos a mesma renda da Coreia do Sul, que também nos deixou para trás. Nesses 30 anos, diga-se, o Chile nos deu um banho de crescimento. E os EUA mantém uma linha praticamente linear de crescimento.
Fico pensando até quando o Brasil vai ficar para trás... Mas, isso já é um outro tema...
Caso queira receber o código do gráfico acima, rola a barrinha à direita e coloca seu e-mail na nossa newsletter! Na próxima segunda-feira, vou enviar algumas coisas bem legais para a lista!


