Em post anterior nesse espaço, comecei a investigar o comportamento da série mensal de focos de queimadas no Brasil. A primeira característica marcante da série é sua sazonalidade, que mostrei com a função ggmonthplot do pacote forecast. Agora, vamos retirar essa sazonalidade da série, de modo a investigar outros comportamentos interessantes.
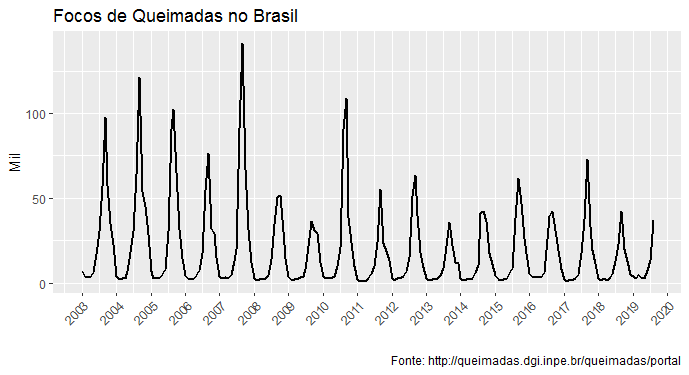
Antes de mais nada, um gráfico da nossa série:
ggplot(data, aes(obs, Focos/1000))+
geom_line(size=.8)+
scale_x_date(breaks = date_breaks("1 year"),
labels = date_format("%Y"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
labs(x='', y='Mil',
title='Focos de Queimadas no Brasil',
caption='Fonte: http://queimadas.dgi.inpe.br/queimadas/portal')
E o gráfico...
Usando o pacote seasonal, podemos agora dessazonalizar os nossos dados com o código abaixo.
queimadas_sa = final(seas(queimadas))
E abaixo um gráfico da nossa série dessazonalizada.
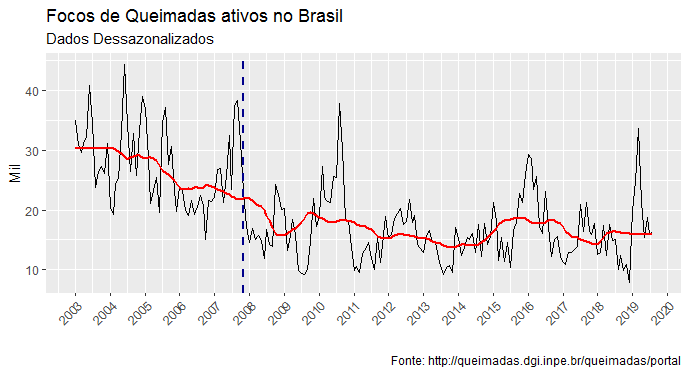
A linha vermelha é uma média móvel de 24 meses que mostra uma tendência de queda na maior parte da amostra.
_________________
Um script completo estará disponível no Clube do Código quando terminarmos essa série de posts sobre focos de queimadas no Brasil.


