Outliers são valores atípicos e distantes das demais observações de um determinado conjunto de dados. A depender do tipo de análise que você esteja fazendo, eles podem distorcer os resultados, levando a conclusões nem sempre verdadeiras. Por isso, é sempre importante fazer uma análise exploratória dos dados, se certificando de que o seu conjunto de dados não está contaminado com esse tipo de problema.
De modo a ilustrar como detectar e descartar outliers no R, vou mostrar aqui a parte introdutória de um exercício relacionando a inflação observada com as expectativas de inflação. Os dados estão disponíveis no Banco Central. Para começar, eu carrego alguns pacotes como abaixo.
## Pacotes library(rbcb) library(tidyverse) library(scales) library(ggrepel) library(png) library(grid) library(gridExtra) library(sidrar) library(readxl) library(xts) library(grDevices) library(ggalt)
Com o pacote rbcb, eu importo os dados de inflação e de expectativa de inflação, já fazendo um tratamento dessa última. O objetivo é ter um tibble com dados mensais de ambas as variáveis.
## Importar expectativas de inflação
expinf = get_twelve_months_inflation_expectations('IPCA',
start_date = '2001-11-01')
expectativa = expinf$mean[expinf$smoothed=='N' & expinf$base==0]
dates = expinf$date[expinf$smoothed=='N' & expinf$base==0]
expinf12 = xts(expectativa, order.by = dates)
expinf12 = apply.monthly(expinf12, FUN=mean)
expinf12 = expinf12[-length(expinf12)]
## Importar inflação
inflacao = get_series(13522, start_date='2001-11-01')
## Juntar dados
data = tibble(date=inflacao$date,
expfocus=as.numeric(expinf12),
inflacao=inflacao$`13522`)
colnames(data) = c('date', 'expfocus', 'inflacao')
Com os dados disponíveis, nós podemos gerar um gráfico de correlação já chamando atenção para os outliers presentes no conjunto de dados. O código abaixo implementa.
select.outliers = data[data$inflacao > min(boxplot.stats(data$inflacao)$out) |
data$expfocus > min(boxplot.stats(data$expfocus)$out),]
ggplot(data, aes(x=inflacao, y=expfocus))+
geom_point(stat='identity')+
geom_encircle(aes(x=inflacao, y=expfocus),
data=select.outliers,
color="red",
size=2,
expand=0.08)+
annotate('text', x=14, y=10,
label='Outliers',
colour='darkblue', size=4.5)+
labs(x='Inflação Observada', y='Expectativa de Inflação',
title='Inflação vs. Expectativa de Inflação no Brasil',
caption='Fonte: analisemacro.com.br com dados do BCB.')
Observe que estou usando a função boxplot.stats do pacote grDevices para construir o intervalo onde vou circular os possíveis outliers do conjunto de dados. Com essa função, nós conseguimos definir um outlier como sendo os valores que estão fora do intervalo composto por ![[(Q1 - 1,5*IQR), (Q3 + 1,5*IQR)]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-a0cffe79a73076df5ba58f056a575b95_l3.png "Rendered by QuickLaTeX.com") - para quem é iniciante em estatística, talvez seja necessário conhecer nosso Curso de Estatística usando R e Python A seguir colocamos o gráfico.
- para quem é iniciante em estatística, talvez seja necessário conhecer nosso Curso de Estatística usando R e Python A seguir colocamos o gráfico.
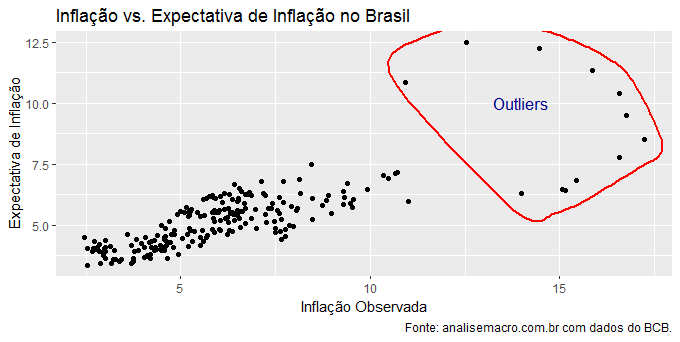
Uma vez identificadas as observações consideradas outliers, nós podemos nos livrar dela com o código abaixo.
outliers = c(boxplot.stats(data$inflacao)$out, boxplot.stats(data$expfocus)$out) data_outliers = data[-c(which(data$inflacao %in% outliers), which(data$expfocus %in% outliers)),]
Produzimos agora um gráfico de correlação sem os pontos considerados outliers como abaixo.
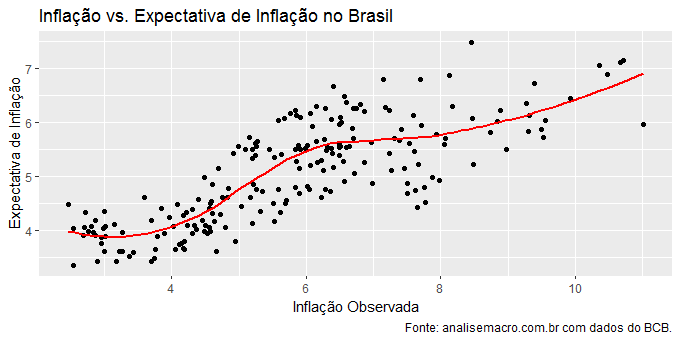
Bem melhor, não?
__________________________
(*) Isso e muito mais você aprende em nossos Cursos Aplicados de R e Python.


